There is a well-known valley of despair in AI deployment: the demo works beautifully, stakeholders are excited, the project gets greenlit, and then six months later the team is still debugging edge cases, handling unexpected failures, and trying to understand why the agent works great on some inputs and catastrophically fails on others. The move from proof-of-concept to production is where most agentic projects stall.
I have been through this transition enough times — both in my own research and advising engineering teams — to have strong opinions about what matters. Here are the patterns that consistently bridge the gap.
Pattern 1: Structured State Management
The single most important architectural decision for a production agent is how you manage state. Ad-hoc state management — passing dictionaries around, relying on variable names, using the model's context window as the sole source of truth — fails as agents grow in complexity.
A typed, explicit state schema is non-negotiable in production. In practice, this means defining a structured data contract that captures everything an agent knows at any point in its execution: the conversation history, the current task description, the list of planned steps with their completion status, a log of every tool call made in the session, a running retry counter, any error context from failed operations, and a dictionary of user-facing results produced so far. This explicit declaration is what makes the agent's internal state inspectable and debuggable rather than a black box. It also enables proper checkpointing — if the agent crashes mid-run, you can resume from the last saved state rather than restarting from zero. Most importantly, it forces explicit thinking about what information actually needs to persist across steps, a discipline that alone prevents entire categories of bugs.
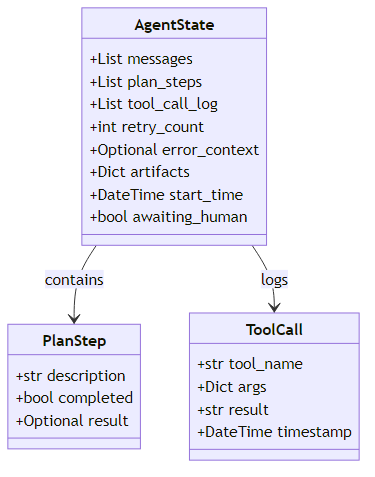
LangGraph's StateGraph is built around this pattern. Every node receives the full state and returns a state delta. This makes nodes individually testable and the state transitions auditable.
Pattern 2: Checkpointing and Resumability
Long-running agents will fail mid-execution. Network timeouts, API rate limits, model provider outages, tool errors — all of these can interrupt an agent that has been running for 10 minutes and has completed 20 of 25 planned steps. Without checkpointing, you restart from zero.
LangGraph provides built-in checkpointing that integrates directly with the state schema described above. The mechanism works by associating each agent run with a unique thread identifier — think of it as a session key. After every major state transition, the framework serializes the current state to a persistent store. If a run is interrupted and then reinvoked with the same thread identifier, the agent picks up exactly where it left off rather than re-executing completed steps. For distributed systems, the backing store should be a proper database such as PostgreSQL or Redis rather than a local file — durability and accessibility across multiple machines is the whole point.
The checkpoint interval matters: checkpoint after every major state transition, not every minor substep.
Pattern 3: The Circuit Breaker
Agents that encounter failures tend to retry. Agents that keep retrying can send thousands of identical failing requests to a downstream API, blow through rate limits, and incur significant costs before anyone notices. The circuit breaker pattern prevents this.
The circuit breaker maintains a simple state machine with three modes. In the closed state — normal operation — every outgoing call goes through. Each failure increments a counter. When failures accumulate beyond a threshold, the breaker trips to the open state and immediately rejects all further calls to that service, throwing an exception rather than attempting the call. After a configurable timeout period, the breaker moves to a half-open state and allows a single probe call through. If that probe succeeds, the breaker resets to closed; if it fails, it returns to open. This prevents a struggling downstream service from being hammered while it recovers.
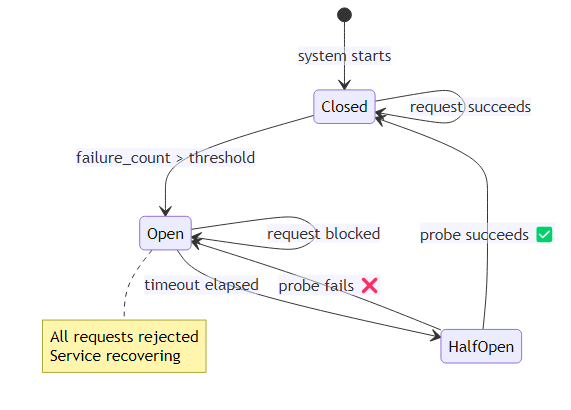
Apply circuit breakers to every external dependency: LLM API calls, tool APIs, database connections. When a circuit opens, the agent should degrade gracefully — return a partial result, escalate to a human, or schedule a retry rather than hammering a broken service.
Pattern 4: Tiered Fallback Strategy
Production agents need fallback plans. If the primary approach fails, what is plan B? If plan B fails, what is plan C?
A robust tool implementation works through tiers in sequence. The first attempt hits the primary provider. If that raises a rate-limit or API error, execution falls through to a secondary provider with equivalent functionality. If that also fails, the system checks whether a cached result exists from a recent prior query — returning it with a clear label that the data may be outdated. The final tier is an explicit acknowledgment of the limitation, allowing the agent to continue its task with the understanding that web search is unavailable for this step rather than halting entirely.
The fallback chain needs to be domain-specific. For a research agent, falling back to cached results is acceptable. For a financial agent executing trades, the correct fallback is to halt and alert a human.
Pattern 5: Human-in-the-Loop Gates
Not every decision should be automated. Production agents need explicit checkpoints where human review is required before proceeding.
Design decisions for HITL gates:
- What triggers a gate: irreversibility (sending emails, making purchases, deleting data), uncertainty (agent confidence below threshold), value threshold (transactions above a dollar limit)
- How to present decisions: agents should provide their reasoning and recommended action, not just ask "approve?" A well-structured HITL request accelerates human review
- Timeout behavior: what happens if the human does not respond in 30 minutes? Does the agent wait indefinitely, cancel, or proceed with a default action?
A well-designed approval gate packages the pending action into a structured request, assigns it a unique identifier, and sends it to a notification channel where human reviewers can act on it. The agent then awaits a response within a defined timeout window — typically thirty minutes. If the timeout elapses without a response, the system records the event in an audit log and defaults to the safest action: cancellation. This ensures that delayed or absent reviewers do not silently allow high-stakes actions to proceed.
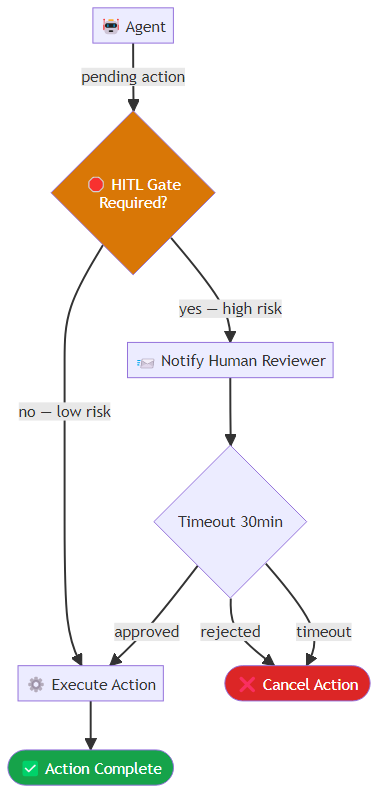
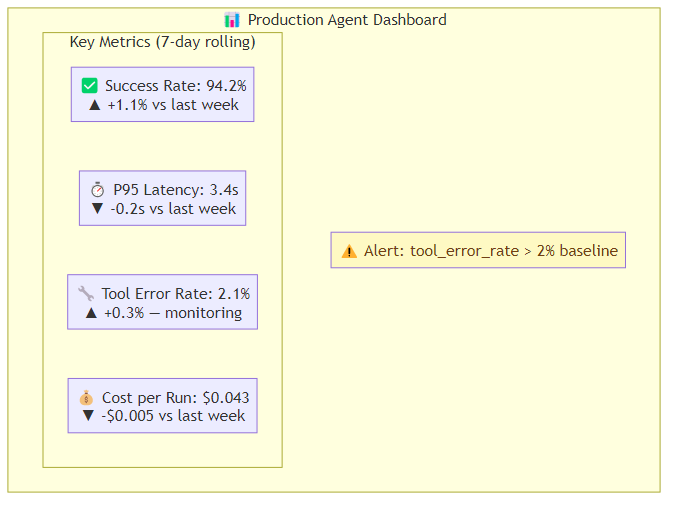
Pattern 6: Observability as a First-Class Requirement
You cannot improve what you cannot see. Every production agent needs:
Structured trace logging: every agent step — model inference, tool call, state transition — should be logged with a trace ID, timestamps, inputs, outputs, and latency. LangSmith, Arize Phoenix, Langfuse, and custom OpenTelemetry setups all support this. Decorating individual tool functions with tracing annotations is sufficient to capture the information needed — the framework handles the mechanics of recording inputs, outputs, and timing without requiring any changes to the tool's core logic.
Cost tracking per run: know what each agent execution costs. This is not just a financial concern — cost per run is a proxy for efficiency. If cost per run is increasing over time, your agent is probably doing something inefficient.
Anomaly detection: alert when success rate drops, latency increases, or tool error rates spike. Set baselines during initial deployment and alert on deviations.
Session replay: for debugging specific failures, you need the ability to replay an agent's exact sequence of steps with its exact inputs. This requires deterministic seeding (or accepting non-determinism and logging all randomness) and capturing all external tool responses.
Pattern 7: Graceful Degradation
When full agent functionality is unavailable, return something useful rather than a hard failure.
Graceful degradation is implemented as a cascade of capability tiers. The first attempt runs the full agentic pipeline with live tool access. If a system-level failure prevents that, a second attempt runs a degraded mode that uses only retrieval — pulling from a knowledge base without hitting live APIs. If even retrieval is unavailable, the agent falls back to a direct language model response, accompanied by an explicit disclaimer that it is operating in limited mode and that some capabilities are temporarily unavailable. The user always receives something useful and always knows the constraints under which the response was produced.
The user experience goal is: always return something useful, always be transparent about limitations, never fail silently.
The Production Readiness Checklist
Before I sign off on a production agent deployment, I want to verify:
- Typed state schema with explicit fields for all agent state
- Checkpointing configured with a persistent backing store
- Circuit breakers on all external API calls
- Tiered fallback for every critical capability
- HITL gates for all irreversible or high-stakes actions
- Trace logging with per-step inputs, outputs, latency, cost
- Alerting on success rate, latency, and error rate anomalies
- Graceful degradation strategy documented and tested
- Load tested at 2x expected peak traffic
- Failure injection testing (what happens when each dependency fails?)
- Runbook for on-call engineers covering common failure modes
None of these are exciting. All of them are necessary.
The agents that survive in production are not the most sophisticated ones. They are the ones built by teams that treated reliability as a requirement, not an afterthought.