
In October 2022, Shunyu Yao, Jeffrey Zhao, Dian Yu, and colleagues published "ReAct: Synergizing Reasoning and Acting in Language Models." The paper introduced a prompting strategy that would go on to become arguably the most influential single idea in applied LLM agent engineering: interleave the model's reasoning traces with its actions, grounding each reasoning step in actual observations from the environment.
The idea seems almost obvious in retrospect. Of course an agent should think before it acts, and of course it should update its thinking based on what it observes. But the specific implementation — the Thought-Action-Observation (TAO) loop as a prompting pattern — unlocked capabilities that neither reasoning alone (chain-of-thought) nor acting alone could achieve.
The ReAct Paper: What It Actually Said
Before discussing where ReAct has evolved, it is worth being precise about what the original paper demonstrated.
The authors evaluated on two task types: knowledge-intensive reasoning (HotpotQA, FEVER) and decision-making (ALFWorld, WebShop). Their key findings:
Chain-of-thought only (reason but do not act): good on static knowledge questions, but unable to correct reasoning errors because there is no grounding in external observations.
Acting only (act but do not reason): effective at tool use but lacks the planning capacity to handle multi-step, strategically complex tasks.
ReAct (interleaved reasoning and acting): consistently outperforms both baselines. On HotpotQA, ReAct improved over chain-of-thought alone by 10+ percentage points. On decision-making tasks, the improvement was even more dramatic.
The mechanism is important: the Thought steps are not just decoration. They serve as scratchpads that allow the model to maintain a working hypothesis, update it as observations come in, and generate better-targeted action choices.
The TAO Loop in Practice
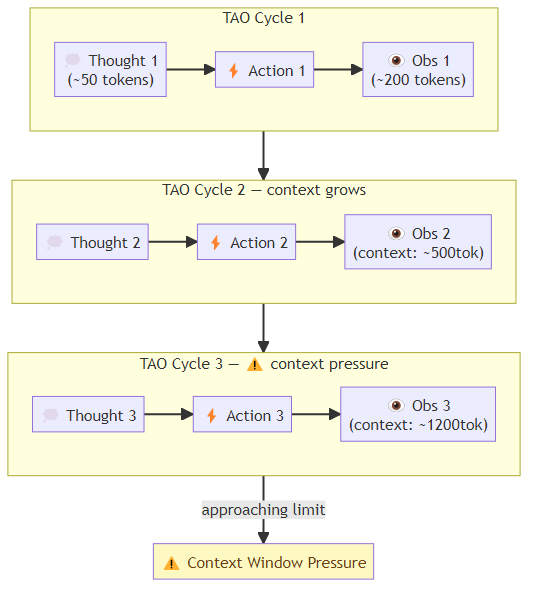
The ReAct prompting format produces a structured alternation between three distinct types of output. A Thought step is the model's internal reasoning — identifying what it knows, what it needs to find out, and what action would best advance its understanding. An Action step names the specific tool to invoke and the argument to pass to it. An Observation step is the result returned by that tool, which becomes new grounding for the next Thought. In a concrete example, an agent asked how many years ago the Eiffel Tower was completed would first reason through what it needs to look up, then issue a search action for the construction date, receive the date 1889 as an observation, then reason about the arithmetic needed, perform a calculation action, receive the result 137, and finally reason that it now has enough information to answer the question directly.

The explicit verbalization of reasoning between each action is doing real work. Studies on ReAct-style agents consistently show that removing the Thought steps — going directly from Observation to Action — degrades performance significantly, even when the model has access to the same tools.
Implementing ReAct with Modern Frameworks
In 2022, ReAct was implemented via raw prompt engineering. Today, frameworks abstract the loop cleanly. Creating a ReAct agent in LangChain requires defining tools with descriptions, providing a capable language model, and calling a single factory function that wires everything together. Behind the scenes, LangChain constructs the ReAct prompt format, parses the model's output to identify Thought, Action, and Observation boundaries, executes the appropriate tool call, and feeds the observation back into the growing context for the next iteration. What took pages of custom code in 2022 is a few lines today.
Where ReAct Falls Short
ReAct is powerful but not a silver bullet. Three failure modes show up consistently in production:
Reasoning hallucination: the model's Thought steps can be confidently wrong. If the model hypothesizes an incorrect mechanism in a Thought and subsequent Actions are based on that hypothesis, the entire trajectory can go off-rails. The observations ground the model, but only if the model updates its beliefs correctly in response to disconfirming evidence.
Infinite loops: in some implementations, agents get stuck in patterns where an action produces an observation that the model finds unsatisfying, leading to another action, another observation, and so on. Without a loop detection mechanism or a maximum step limit, this can run indefinitely. The straightforward mitigation is to configure a hard ceiling on the number of Thought-Action-Observation cycles the agent is permitted to complete, along with an early-stopping strategy that forces a final answer once that ceiling is reached rather than simply terminating mid-thought.
Context window exhaustion: each TAO cycle appends to the context. A long trajectory with verbose observations can exhaust the context window before the task is complete. Modern long-context models (200K+ tokens) have reduced this problem but not eliminated it for very long-running tasks.
Variants and Extensions
The ReAct paradigm has spawned a family of related approaches:
DEPS (Describe, Explain, Plan, Select): extends ReAct with explicit long-range planning before execution. Useful for tasks where the correct tool sequence is not obvious from the first step.
Reflexion (Shinn et al., 2023): adds a reflection step after each complete task attempt. The agent reviews its trajectory, identifies mistakes, and stores verbal reinforcement signals in memory to guide future attempts. On the HumanEval coding benchmark, Reflexion improved GPT-4's pass@1 from ~48% to ~68%. The mechanism is an outer loop around the ReAct agent: after each full attempt, a separate reflection step examines the complete trajectory and articulates what went wrong and what should be done differently. That reflection is stored in a memory module. On the next attempt, the agent begins with access to its own prior critiques, allowing it to avoid the same mistakes. This is a form of verbal reinforcement learning — the agent improves across attempts not by updating its weights but by accumulating better self-knowledge.
ReWOO (Xu et al., 2023): Reasoning WithOut Observations. The agent generates the full plan — including all tool calls — before executing any of them. This reduces the number of inference calls (no interleaved reasoning) at the cost of not being able to adapt the plan based on intermediate observations. Significantly faster for tasks where the plan is predictable.
LATS (Language Agent Tree Search): combines ReAct with Monte Carlo Tree Search. Rather than committing to a single action at each step, LATS explores multiple possible actions, evaluates them using a value function (another LLM call), and selects the most promising branch. Achieves state-of-the-art performance on reasoning benchmarks at the cost of 5-10x more inference calls.
The Reasoning Revolution: o1, o3, and Deliberative Alignment
The introduction of OpenAI's o1 model in late 2024 reframed the conversation around reasoning in agents. o1 internalizes chain-of-thought reasoning into the training process itself, producing a model that "thinks" before answering — but invisibly, in a hidden chain-of-thought that is not exposed in the output.
This is a fundamentally different approach from ReAct. Rather than prompting for interleaved reasoning, the reasoning capability is built into the model. The practical effect: o1 and o3 models perform dramatically better on reasoning-heavy tasks without explicit prompting for chain-of-thought.
The implication for agentic engineering is nuanced. For single-shot reasoning tasks, newer models with built-in deliberation may be superior to ReAct-style prompting. For tasks requiring genuine tool use and environmental grounding, the TAO loop remains essential — even a thinking model needs to interact with external systems, and the interaction protocol still looks like ReAct at the agent level.
What the TAO Loop Gets Right
After three years of widespread adoption, I think the enduring insight of ReAct is this: reasoning and acting are not separate phases — they are a dialogue. Every observation should be an opportunity to update beliefs. Every thought should be grounded in observed reality. Every action should be motivated by explicit reasoning.
This is not just an AI engineering principle. It is good scientific practice. Hypothesis, experiment, observation, updated hypothesis. The TAO loop is the scientific method applied to autonomous problem-solving.
The specific prompting format will continue to evolve. The underlying insight — that reasoning needs to be grounded in observation to be reliable — is almost certainly here to stay.


