
Standard Retrieval-Augmented Generation works like this: user asks a question, system performs a similarity search against a vector database, top-K most similar documents are prepended to the prompt, the model generates an answer conditioned on those documents. This is useful, and for many applications it is sufficient.
But it fails in ways that are increasingly apparent as we push RAG systems to handle more complex queries:
- The initial query may be ambiguous, leading to poor retrieval
- The top-K retrieved documents may not contain sufficient information to answer the question
- The model may hallucinate confidently even when the retrieved documents contradict the answer
- Multi-hop questions (where the answer to step 1 is needed to formulate the query for step 2) are fundamentally beyond single-pass retrieval
Agentic RAG — RAG systems that can plan, iterate, and self-evaluate their retrieval process — addresses all of these limitations. It is not a single technique but a pattern: giving the RAG system agency over its own information-gathering process.
The Core Problem with Naive RAG
Let me be concrete about where naive RAG breaks down.
Ambiguous queries: "What are the main differences between the two approaches discussed last quarter?" requires context the retrieval system does not have. A static query cannot surface the right documents because the right documents depend on understanding what "the two approaches" and "last quarter" mean in this context.
Multi-hop retrieval: "What was the outcome of the experiment described in the paper that built on Smith et al.'s 2023 work?" requires two retrieval steps: find the paper that built on Smith et al., then find the outcome of its experiment. Single-pass retrieval cannot handle this without heroic luck.
Retrieval quality verification: standard RAG assumes the retrieved documents are relevant and accurate. When the retrieval quality is poor — when the document corpus is noisy, when queries are unusual, when the embedding model has gaps — the model generates an answer based on irrelevant context. It often does so confidently.
Iterative refinement: some questions cannot be fully answered in one retrieval pass. Research questions, comparative analyses, and synthesis tasks often require progressively more specific retrieval as the model learns more about what it does and does not know.
The Agentic RAG Architecture
In its most basic form, agentic RAG wraps the standard RAG loop in an agent that can decide to retrieve, evaluate retrieval quality, and re-retrieve if necessary.

The architecture exposes retrieval and quality evaluation as tools available to the agent rather than as fixed pipeline stages. A retrieve tool accepts a natural-language query and a result count, runs a similarity search against the vector store, and returns the matching document texts. An evaluate tool then takes the original question alongside the retrieved documents and asks a separate evaluator model to assess three things: whether the documents are relevant to the question, whether they contain sufficient information to construct an answer, and what additional information is still needed. With both tools available, the agent can loop — retrieve, evaluate, reformulate the query based on the evaluation, retrieve again — until the retrieval quality meets a threshold or a maximum iteration count is reached. This basic version gives the agent the ability to assess its own retrieval quality and decide whether to continue. More sophisticated versions add query reformulation, multi-source retrieval, and answer verification.
CRAG: Corrective RAG
Yan et al. (2024) introduced Corrective RAG (CRAG), which adds an explicit correction mechanism: after retrieval, a lightweight evaluator model assesses whether the retrieved documents are relevant. If they are not, the system falls back to web search. If they are partially relevant, the system decomposes documents and retains only relevant segments.
CRAG scores each retrieved document against the query on a continuous relevance scale. Documents scoring above a high threshold are kept as-is. Documents in an ambiguous middle range are decomposed into smaller chunks, each of which is re-evaluated individually — only the chunks that pass the relevance threshold are retained. Documents scoring below the threshold are discarded entirely, and when too many documents are discarded or no relevant material remains, the system falls back to a live web search. The final answer is generated over this curated, verified context rather than the raw retrieval output. CRAG shows meaningful improvements over naive RAG on knowledge-intensive benchmarks because it actively corrects for retrieval failures rather than generating over irrelevant context.
Self-RAG: Generating With Reflection
Asai et al. (2023) introduced Self-RAG, a training-based approach where the model learns to generate special reflection tokens that control its own retrieval behavior:
[Retrieve]: trigger retrieval of additional context[IsRel]: assess whether retrieved documents are relevant[IsSup]: assess whether the generated statement is supported by retrieved documents[IsUse]: assess whether the overall response is useful
Self-RAG requires fine-tuning, making it less flexible than prompting-based approaches, but the performance improvements are significant. The model learns not just to generate answers but to critique its own retrieval and generation process.
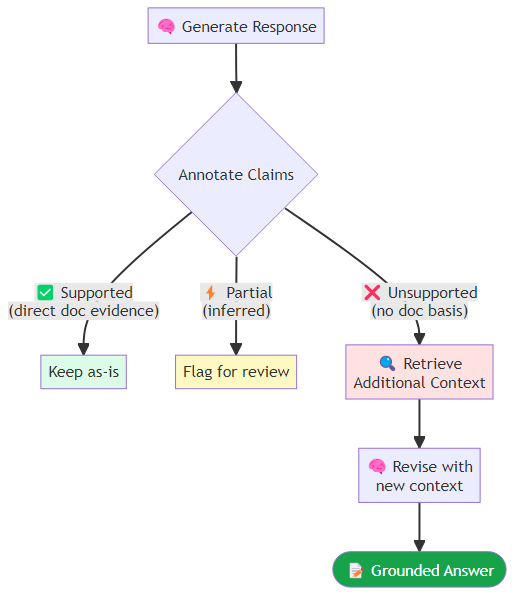
While full Self-RAG training is expensive, the reflection token idea can be approximated with prompting in capable models. The approach is to instruct the model to annotate each factual claim it generates with one of three markers: supported (the claim is directly backed by the provided documents), partial (the claim is broadly consistent with the documents but involves some inference), or unsupported (the claim goes beyond what the documents establish). When the model identifies unsupported claims in its own reasoning, it is instructed to retrieve additional context before finalizing its answer. This creates a self-monitoring loop that catches hallucination at generation time rather than after the fact.
Multi-Step Retrieval for Complex Questions
For multi-hop questions, the agent needs to decompose the question and retrieve iteratively. The process begins by asking the language model to break the original complex question into an ordered sequence of simpler sub-questions, each of which can be answered with a single retrieval step. The agent then works through the sub-questions in order. Crucially, each retrieval query is conditioned not just on the current sub-question but also on a running summary of the answers gathered so far — this prevents the agent from retrieving documents that answer the question in isolation but miss the specific angle that prior context has established. Once all sub-questions are answered, a final synthesis step assembles the accumulated context into a coherent answer to the original question. This is the approach taken by systems like IRCoT (Interleaved Retrieval and Chain-of-Thought), which interleaves retrieval steps with reasoning steps in a single chain-of-thought. Each reasoning step can trigger retrieval, and each retrieval informs the next reasoning step.
Query Reformulation
One of the most reliable improvements in agentic RAG is query reformulation — using the LLM to generate better retrieval queries before hitting the vector store.
HyDE (Hypothetical Document Embeddings): generate a hypothetical ideal answer to the question, then retrieve documents similar to the hypothetical answer rather than the question. This works because questions and answers often live in different parts of the embedding space. The implementation generates a brief expert-level answer to the question, embeds that hypothetical answer rather than the original query, and then retrieves documents whose embeddings are closest to the hypothetical answer embedding. The result is that retrieval is anchored in answer-space rather than question-space, which tends to surface more directly useful material.
Step-back prompting: ask the model to identify the broader category or principle that the question belongs to, then retrieve on that broader query first. "What is the capital of France?" becomes "European geography and capitals." This surfaces relevant context that a direct query might miss.
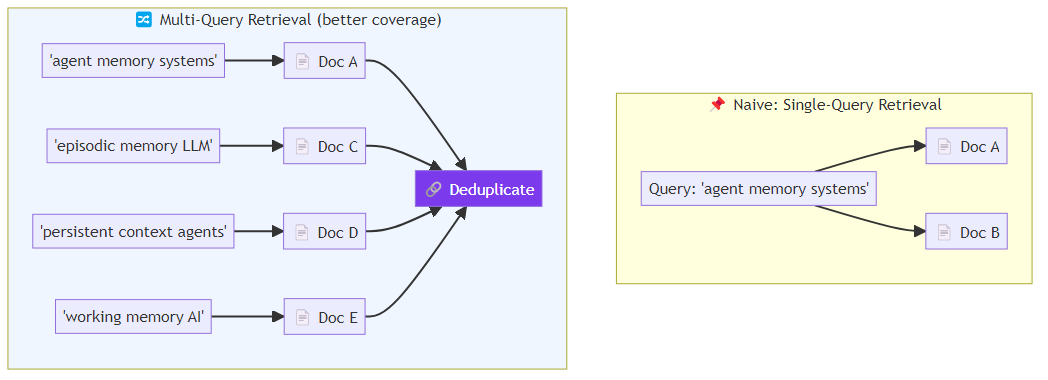
Multi-query retrieval: generate multiple paraphrases or related queries for the same question, retrieve for each, and deduplicate the results. This improves recall when a single query formulation might miss relevant documents.
When to Use Agentic RAG
Standard RAG remains appropriate for:
- Simple, direct factual questions over a consistent document corpus
- High-throughput applications where the latency of multiple retrieval rounds is unacceptable
- Well-defined domains where retrieval quality is consistently high
Agentic RAG earns its complexity for:
- Multi-hop questions requiring chained retrieval
- Noisy or heterogeneous document corpora where retrieval quality varies
- Research and analysis tasks where completeness matters more than speed
- High-stakes domains where hallucination on poor retrieval context is unacceptable
The fundamental shift in agentic RAG is epistemological: the system is not just answering based on what it retrieved, it is reasoning about whether it has retrieved enough, and acting to correct deficiencies. This is closer to how a skilled researcher works — not just searching once, but iteratively refining their information-gathering based on what they find and what they still need.
That metacognitive loop is what makes the difference between a system that generates plausible-sounding answers and one that generates well-grounded answers.


