
Human memory is not a single system. Cognitive scientists distinguish between working memory (what you can hold in conscious attention right now), episodic memory (your autobiographical record of past experiences), semantic memory (general knowledge about the world), and procedural memory (how to ride a bike or type without looking at the keyboard). Each operates differently, degrades differently, and serves different cognitive functions.
LLM agents need analogous systems. The context window is a reasonable working memory. But episodic memory — "what happened in our last conversation?" — procedural memory — "how do I handle this class of requests?" — and semantic memory — "what do I know about this user's domain?" — all require external infrastructure. Building that infrastructure is one of the defining challenges of practical agentic engineering.
The Four Memory Types in Agent Systems
Drawing on the Generative Agents paper (Park et al., 2023) and my own experience building production systems, I find it useful to think about four memory types:
In-context memory (working memory): information within the current context window. This is transient, limited by window size, and lost when the session ends. It is the only memory that does not require engineering effort — it is just the conversation.
External storage (episodic and semantic memory): databases, vector stores, document stores. Information persists across sessions and is retrieved as needed. This is where most of the engineering work lives.
In-weights memory (semantic memory): knowledge baked into the model's parameters through training and fine-tuning. Unchangeable at inference time, but can be updated through fine-tuning. Best for stable, general knowledge.
In-cache memory: KV cache across inference calls (supported by some serving infrastructure). Can dramatically reduce latency and cost for agents with static, long system prompts. Anthropic's prompt caching and similar features from other providers make this practically accessible.

Building Episodic Memory: What Happened Before
The most common user complaint about LLM assistants is that they do not remember previous conversations. This is a tractable engineering problem, though it requires careful design.
The naive approach is to inject the full conversation history into every new session. This fails quickly: conversations get long, context windows fill up, costs explode, and the model struggles to identify what is actually relevant from an undifferentiated wall of text.
A better approach is selective summarization and retrieval. At the end of each session, a lightweight model compresses the conversation into a concise summary of three to five key points, which is then embedded and stored in a vector database alongside metadata such as the session identifier and timestamp. When a new session begins and the user asks a question, the current query is used as a semantic search key against all stored summaries, and the most relevant past conversations are retrieved and prepended to the context. This means the agent begins each new session with targeted recall of relevant history rather than an undifferentiated dump of everything that was ever said.
The key design decisions:
Summarization granularity: do you summarize at the session level, the topic level, or the turn level? Finer granularity gives more precise retrieval but more storage overhead.
Retrieval strategy: semantic similarity (vector search) finds thematically related past conversations. Recency weighting ensures recent conversations are surfaced even if semantically distant. Hybrid approaches — combining semantic and recency scores — work best in practice.
Memory injection: how do you present retrieved memories to the model? I prefer a structured prefix: "Relevant context from previous conversations: [retrieved memories]. Current conversation: [messages]." Make it explicit that these are past records, not current facts.
Semantic Memory: Persistent Knowledge Bases
Beyond episodic records, agents often need access to structured knowledge: product documentation, company policies, domain knowledge, user preferences. This is semantic memory — stable knowledge that does not change frequently.
The canonical implementation is a RAG (Retrieval-Augmented Generation) system. But RAG is a spectrum from simple to sophisticated, and most implementations sit at the simpler end in ways that limit performance.
A well-designed semantic memory system for an agent has:
Chunking strategy: not all text should be chunked the same way. Code should be chunked at function boundaries. Documentation should be chunked at section boundaries. Conversation logs should be chunked at topic boundaries. Using fixed-size character chunks is convenient but loses semantic structure.
Metadata filtering: retrieval should not always scan the entire knowledge base. A customer service agent handling billing questions should retrieve from billing documentation, not from the engineering docs. Metadata filters narrow the search space and reduce noise.
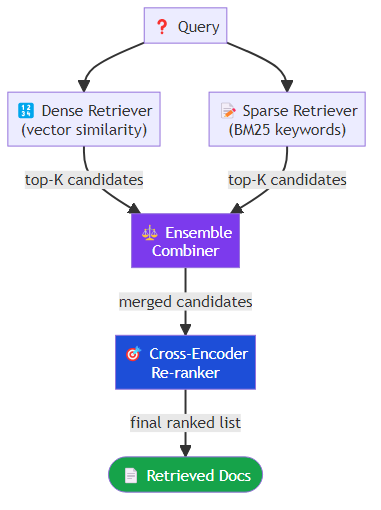
Hybrid retrieval: combining dense retrieval (vector similarity) with sparse retrieval (BM25 keyword matching) consistently outperforms either approach alone. Libraries like Weaviate, Elasticsearch, and Qdrant support hybrid search natively.
Re-ranking: the initial retrieval recalls broadly; a cross-encoder re-ranker then re-scores the top-K results with full query-document attention. This is a significant quality improvement at modest computational cost.
A mature hybrid retrieval setup combines a dense vector retriever — which finds semantically similar documents by comparing embedding vectors — with a sparse BM25 retriever that matches on exact keyword overlap. The two retrievers are run in parallel and their results are merged using weighted combination, typically giving slightly more weight to the dense retriever for general queries. A cross-encoder re-ranker then takes the merged candidate set and re-scores each document by attending simultaneously to both the query and the document text, producing a final ranked list that is substantially more precise than either retriever alone.
Procedural Memory: Learning How to Do Things
Procedural memory is the most underimplemented of the four types. In humans, procedural memory is how you learn to drive — initially effortful and conscious, eventually automatic and unconscious. For agents, the analogue is learning which workflows, prompting strategies, or tool sequences work best for particular task types.
There are two practical approaches:
Explicit procedure storage: store successful task execution traces as procedures. When a similar task arises, retrieve the relevant procedure and use it as a template. In practice this means maintaining a database of completed task workflows indexed by task type, with each record capturing the sequence of steps taken and the quality score of the outcome. When a new task arrives that matches a stored type, the best-performing historical procedure is retrieved and used to guide execution rather than starting from scratch.
Self-refinement loops: MemGPT (Packer et al., 2023) and similar architectures allow agents to update their own system prompts and procedural memory based on feedback. The agent reflects on why a task succeeded or failed and updates its stored procedures accordingly.
Memory Management: The Forgotten Problem
Memory systems fill up. Old information becomes stale. Contradictory information creates confusion. Memory management — deciding what to keep, what to update, and what to discard — is as important as memory storage.
Strategies:
Recency decay: weight more recent memories higher, allowing old information to fade in influence (if not in storage). This mirrors the forgetting curve but is implemented in retrieval scoring, not deletion.
Contradiction detection: when storing new information, check whether it contradicts existing memories. A user who changes their preferences should have the new preference stored with a higher recency weight than the old one.
Summarization hierarchies: as detailed memories accumulate, periodically summarize them into higher-level abstractions. Daily conversation logs become weekly summaries; weekly summaries become monthly themes. This is analogous to human memory consolidation during sleep.
Explicit memory management tools: give the agent tools to manage its own memory. An agent that can call a memory update function to record a changed user preference, or a memory delete function to clear out an obsolete project context, can maintain its own memory health without requiring external intervention.
The Context Window as Working Memory
Finally, within-context management matters more than most practitioners realize. Long contexts are not free — attention costs scale quadratically with context length in vanilla transformers, and even with linear attention variants, longer contexts increase latency and can dilute the model's focus on the most relevant information.
Techniques for effective working memory management:
Progressive summarization: as a conversation grows, periodically summarize the oldest exchanges while keeping recent turns verbatim.
Selective context injection: instead of injecting all available context, be selective. Use relevance scoring to decide what retrieved memories and tool outputs actually belong in the current context.
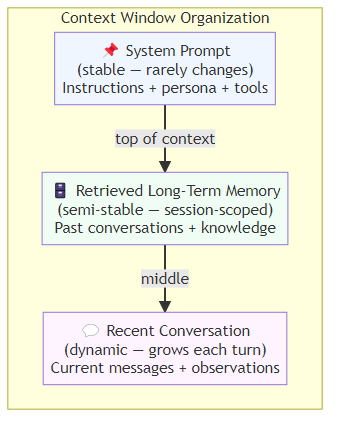
Structured context: organize the context window deliberately. System prompt (stable), retrieved long-term memory (semi-stable), recent conversation (dynamic). Make the structure explicit so the model can navigate it.
Memory is not a feature you add to an agent — it is an architectural decision that shapes every other design choice. The teams that build the most capable agents in 2026 are the ones thinking carefully about all four memory types and how they interact, not just plugging in a vector database and calling it done.
Related posts: The Architecture of Agent Memory — the 4-layer memory architecture from working to procedural memory. Agentic RAG — extending retrieval to agentic workflows. Planning in AI Agents — how memory enables goal-directed reasoning.


