
Planning is the capacity to reason about a sequence of actions before taking them — to simulate possible futures, evaluate their consequences, and select a course of action that leads toward a goal. It is one of the hallmarks of intelligent behavior, and it is one of the hardest things to engineer reliably in LLM-based systems.
Classical AI planning — STRIPS, PDDL, hierarchical task networks — assumed a formal world model: a precise description of initial states, goal states, and the preconditions and effects of every possible action. Modern LLM agents have no such formal model. They plan in natural language, over a world that is only partially observable, using a model of the environment that is implicit in the weights of a neural network. This creates both remarkable flexibility and distinctive failure modes.
What Planning Actually Looks Like in LLM Agents
When we say an LLM agent "plans," we mean several different things depending on the architecture:
Chain-of-thought planning: the model generates a sequence of reasoning steps before producing an action. This was formalized in the Wei et al. (2022) chain-of-thought paper and is now standard practice. The planning is implicit in the generation process — it is not a separate module but emerges from prompted reasoning.
Explicit plan generation: the agent is prompted to produce a structured plan (a numbered list of steps, a JSON task graph) before execution begins. The plan is then executed step by step, with the agent checking off completed steps and adapting when needed.
Interleaved planning and execution: the agent generates one step of a plan, executes it, observes the result, and generates the next step. This is the ReAct pattern — and it is often more reliable than upfront planning because each step is grounded in actual observations rather than hypothesized outcomes.
Tree-based planning: the agent generates multiple candidate next steps, evaluates each one (via a value function, a critic model, or heuristic scoring), and selects the best branch to explore. This is the tree of thoughts approach.
Chain-of-Thought: The Foundation
The insight behind chain-of-thought prompting is deceptively simple: asking a model to show its work improves the quality of its final answer. For planning tasks, this means asking the model to enumerate the steps needed before taking the first one.
For a software debugging task, a chain-of-thought prompt walks the model through a structured diagnostic sequence: articulating the observed behavior, identifying the expected behavior, enumerating possible causes of the discrepancy, proposing a minimal test to distinguish between those causes, committing to the most likely root cause, and only then proposing a fix. Each question builds on the previous answer, preventing the model from jumping to a solution before the problem is properly understood.

This is planning — not planning in the formal AI sense, but planning in the practical engineering sense. The model is being asked to construct a mental model of the problem before jumping to a solution.
The limitation is that chain-of-thought planning is only as good as the model's knowledge and reasoning ability. If the model has incorrect beliefs about how a system works, its chain-of-thought plan will be confidently wrong. This is why grounding — connecting the planning process to actual observations, retrieved facts, and tool outputs — is essential.
Tree of Thoughts: Exploring Multiple Futures
Yao et al. (2023) proposed Tree of Thoughts (ToT), extending chain-of-thought to explicitly explore multiple reasoning paths. Instead of committing to a single chain of reasoning, the model generates multiple candidate thoughts at each step, evaluates them, and uses search (BFS, DFS, or beam search) to find the best path to a solution.
Tree of Thoughts operates as a beam search over reasoning paths. At each depth level, the algorithm generates a branching factor's worth of candidate next thoughts, scores each one against the original problem, keeps only the top candidates, and then expands those into the next generation of candidates. The process continues for a fixed number of depth steps, and the highest-scoring candidate at the final level is returned as the solution.
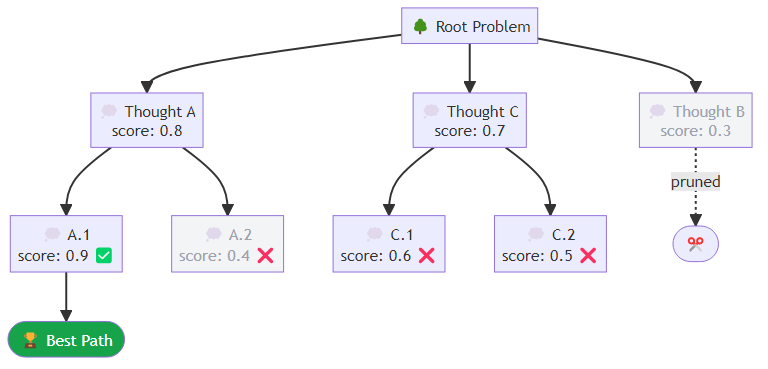
ToT shows strong gains on tasks requiring systematic search: mathematical reasoning, creative writing with constraints, multi-step puzzle solving. The cost is multiplicative inference calls — a branching factor of 3 with depth 4 means potentially 81 inference calls for a single plan. This is appropriate for high-value, low-latency-tolerance tasks, not for interactive conversational agents.
The Plan-and-Execute Pattern
For complex, multi-step tasks, a two-phase architecture often outperforms pure interleaved planning. The planner generates a complete task plan upfront; the executor works through it step by step, with the option to re-plan if a step fails or produces an unexpected result.
LangChain's Plan-and-Execute abstraction captures this pattern directly: a planner LLM is responsible solely for producing a structured task breakdown, while a separate executor LLM — equipped with tools — works through that breakdown step by step. For a task like researching the top AI labs and summarizing their publications, the planner would produce an ordered list of steps: identify the target labs, retrieve their recent publications from their blogs or arXiv, summarize key themes from each lab, compare research directions, and produce a structured report. The executor then attempts each step in sequence, grounding each action in real tool outputs rather than hypothesized outcomes.
Re-planning is often underimplemented. Production systems need explicit logic for: what constitutes a planning failure, when to re-plan vs. retry, how to incorporate the failed step's observations into the new plan, and how to avoid infinite re-planning loops.
MCTS and Advanced Search
For domains with well-defined reward signals (competitive games, verified mathematical proofs, code that passes test suites), Monte Carlo Tree Search (MCTS) can be integrated with LLM planning. The LLM serves as both the policy (suggesting candidate actions) and the value function (estimating the value of a state).
AlphaCode's successors and mathematical reasoning systems like DeepSeek-Prover use variants of this pattern. The LLM proposes proof steps; a verifier checks whether they are logically valid; MCTS explores the space of valid proof paths.
For most practical agentic engineering, MCTS is overkill. But the underlying insight — that systematic search with a learned value function outperforms greedy next-step prediction — applies more broadly. Even a simple "generate three alternatives and pick the best" heuristic is a degraded form of tree search.
Common Planning Failure Modes
Overconfident upfront plans: the model generates a confident-sounding plan that is fundamentally wrong because it lacks critical information. Mitigation: require the planning phase to identify what information it needs before generating a plan. Include a "gather information" step at the beginning.
Plan abandonment under execution pressure: the model forgets its plan mid-execution, especially in long contexts. Mitigation: keep the plan visible in the context at each step. LangGraph's state-based architecture handles this naturally.
Over-planning for simple tasks: the model generates a five-step plan for a one-step task, adding unnecessary latency and cost. Mitigation: include a complexity assessment step that routes simple tasks to direct execution and complex tasks to full planning.
Circular plans: the model generates plans that loop back to steps already completed, often when it has not properly tracked execution state. Mitigation: maintain an explicit "completed steps" tracker in the agent state.
Practical Planning Architecture
The architecture I recommend for production agentic systems:
Task classification: is this a direct-answer task, a single-tool task, or a multi-step planning task? Route accordingly.
Information gathering: before planning, identify and retrieve the information the agent will need. Upfront plans based on incomplete information produce poor results.
Plan generation with explicit uncertainties: ask the model to flag steps where the outcome is uncertain. These are re-planning triggers.
Interleaved execution with plan tracking: maintain the original plan in state, mark steps as complete, allow step-level adaptation without full re-planning.
Re-planning circuit breaker: after N re-planning attempts, escalate to a human or return a graceful failure rather than looping indefinitely.
Planning is not a solved problem in LLM agents. The models are capable of impressive multi-step reasoning, but they are also capable of confident mistakes and context drift in long execution sequences. The engineering challenge is building the scaffolding that makes their planning capabilities reliable enough to trust in production.
The goal is not plans that are always perfect. It is systems that fail gracefully and recover reliably.
Related posts: Planning and Reasoning in AI Agents — the planning spectrum from zero-shot to deliberative reasoning. The Architecture of Agent Memory — how memory enables long-horizon planning. ReAct and Reflexion Patterns — reasoning patterns for tool-use agents.


