
A language model without tools is like a brilliant analyst locked in a library with no phone, no internet, and no way to run an experiment. They can reason over what they already know, but they cannot check whether their assumptions are still accurate, query a live database, or run a calculation with more than a few significant digits. Tool use is the mechanism that breaks down this isolation.
The ability for LLMs to call external tools — APIs, code interpreters, databases, search engines — is arguably the most consequential capability addition since the transformer architecture itself. It is also one of the most technically nuanced to implement correctly.
The Mechanics of Tool Use
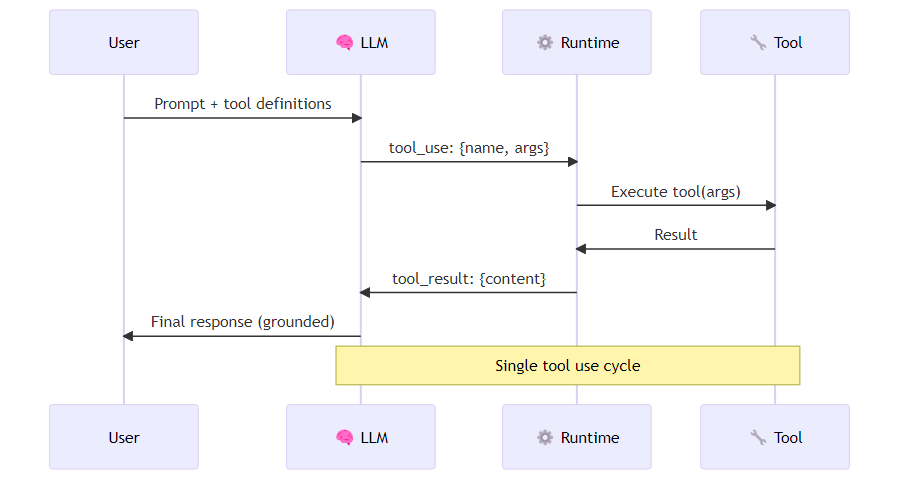
At its core, LLM tool use works through a structured interface between the model's text output and a runtime execution layer. The model is given a description of available tools — their names, descriptions, and parameter schemas — and asked to decide whether to call a tool, which one, and with what arguments. The runtime executes the call and returns the result to the model's context.
OpenAI formalized this with their function calling API in 2023, and Anthropic followed with tool use in Claude's API. The mechanics differ slightly, but the underlying pattern is the same.
The Anthropic tool use pattern works as follows. Each tool is declared to the API as a structured specification: a name, a natural-language description of what the tool does and when to use it, and a JSON schema defining the parameters the tool accepts. When the model receives a user message alongside this tool registry, it can respond in one of two ways: with a regular text reply, or with a tool-use signal indicating that it wants to call a specific tool with specific arguments. The calling application detects this signal, executes the actual tool function, and returns the result to the model in a follow-up message. The model then generates its final response conditioned on the tool's output. The loop is explicit: model decides, runtime executes, model continues. This is not magic — it is a structured prompt-and-response cycle with deterministic execution in between.
Tool Description Quality is Everything
The most common failure mode in tool use implementations is not a bug in the runtime — it is a poorly written tool description. The model decides whether and how to use a tool based almost entirely on the description you provide. Vague descriptions lead to incorrect tool selection. Ambiguous parameter descriptions lead to malformed arguments.
Compare these two descriptions for the same tool:
Bad: "search": "Search for information"
Good: "web_search": "Search the internet for current information not available in training data. Use this when the user asks about recent events, live data (prices, weather, sports scores), or information that may have changed since your training cutoff. Input should be a specific search query string."
The second description tells the model exactly when to use the tool, what kind of input it expects, and what kind of output to expect. This is documentation-as-behavior: the quality of your tool descriptions directly determines the quality of your agent's tool selection.
Parallel Tool Use
Modern APIs support parallel tool calls — the model can decide to call multiple tools simultaneously and wait for all results before continuing. This is a significant performance improvement for tasks with independent subtasks.
When an agent is asked to compare weather conditions across three cities, a capable model can recognize that the three retrieval operations are entirely independent and issue all three tool calls in a single response rather than serializing them. The calling application receives a list of tool calls, executes them concurrently — using asynchronous execution or threading — and returns all results together in the follow-up message. The runtime responsibility is to execute these calls in parallel and return all results in the follow-up message. A naive implementation that serializes parallel tool calls loses most of the latency benefit.
Beyond Simple APIs: Tool Categories
The tool use ecosystem has expanded well beyond simple REST API calls. The major categories are:
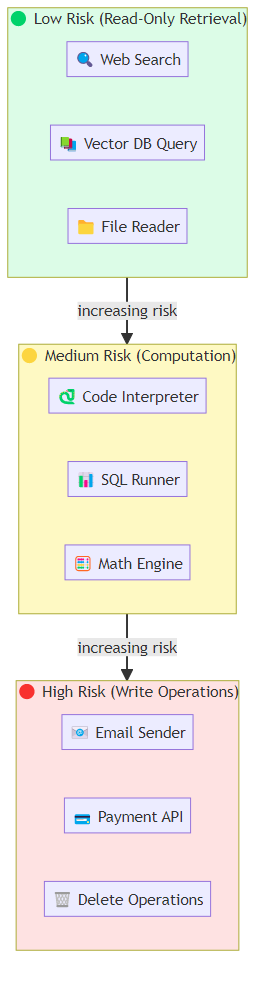
Retrieval tools: search engines, vector databases, knowledge bases. These are the backbone of RAG (Retrieval-Augmented Generation) systems. The tool is essentially a query interface; the model formulates a query and receives relevant documents or data.
Computation tools: code interpreters (Python, JavaScript), mathematical computation engines, SQL query runners. OpenAI's Code Interpreter (now called Advanced Data Analysis) popularized this pattern. The model writes code, the interpreter runs it, and the output (including charts, tables, error messages) comes back to the model's context.
Action tools: anything that changes state in the world. Email senders, calendar creators, form fillers, API call executors, browser automation. These are the most powerful and the most dangerous — mistakes have real-world consequences.
Memory tools: read/write interfaces to persistent storage, enabling agents to maintain state across sessions. These blur the line between tool use and agent memory architecture.
Agent-as-tool: In multi-agent systems, one agent can be a tool for another. The orchestrating agent calls a "research_agent" tool and gets back a synthesized research report. This is how hierarchical agent systems are often implemented in practice.
The Model Context Protocol
In late 2024, Anthropic introduced the Model Context Protocol (MCP) — a standardized, open protocol for connecting LLMs to tools and data sources. Rather than every team building custom tool integration code, MCP defines a standard interface that any LLM client can use to discover and call tools exposed by any MCP server.
The impact has been significant. MCP servers now exist for databases (PostgreSQL, SQLite), development tools (GitHub, Jira), productivity suites (Google Drive, Notion), and custom enterprise data sources. An agent built on a MCP-compatible framework can pick up new tools by connecting to new servers, without any code changes.
With MCP, an agent connects to a server at a known address, requests a list of all tools that server exposes, selects the appropriate one, and invokes it with the necessary arguments — all through a standard protocol that works identically regardless of what the server is actually doing under the hood. This means a single agent implementation can gain new capabilities simply by pointing at new MCP servers, without any changes to the agent code itself. MCP is not a silver bullet — you still need good tool descriptions, and the security implications of arbitrary tool connections deserve careful thought — but it represents an important step toward a more composable tool ecosystem.
Security and Safety Considerations
Tool use introduces an attack surface that pure text generation does not have. If your agent can call APIs, write to databases, or send emails, a carefully crafted input could potentially manipulate the agent into taking harmful actions. This is prompt injection applied to agentic systems.
Practical mitigations:
Principle of least privilege: give agents only the tools they need for their specific task. A customer service agent does not need write access to your production database.
Human-in-the-loop for high-stakes tools: for actions that are difficult to reverse (sending emails, making purchases, deleting data), require explicit human confirmation before execution.
Input validation on tool arguments: validate tool arguments before execution. A model might be coerced into passing a malicious SQL query; your tool runtime should sanitize inputs.
Audit logging: log every tool call with its full arguments. This is essential for debugging, for compliance, and for detecting adversarial patterns.
Sandboxing for code execution: if you give an agent a code interpreter, run it in a sandboxed environment. An unconstrained code interpreter is effectively an arbitrary code execution vulnerability.
Measuring Tool Use Quality
How do you know if your agent is using tools well? The metrics I track in production:
- Tool selection accuracy: does the agent call the right tool for a given query? Measure on a labeled evaluation set.
- Argument quality: are the arguments well-formed and semantically appropriate? Track API error rates from malformed arguments.
- Unnecessary tool calls: is the agent calling tools it does not need? This drives cost and latency.
- Tool use latency breakdown: what fraction of end-to-end latency is model inference vs. tool execution? This tells you where to optimize.
Tool use is where LLMs transition from remarkable text processors to genuine agents that can act in the world. Getting it right requires careful attention to tool descriptions, runtime reliability, parallel execution, and security. The models are capable. The hard work is in the engineering layer around them.


