
Function calling — the ability for an LLM to produce structured output that maps to a programmatic function invocation — was not invented in 2023. Researchers had been eliciting structured outputs from language models for years using carefully crafted prompts and regex parsing. What changed when OpenAI shipped "function calling" in their API was the formalization: a first-class protocol for defining available functions, a reliable mechanism for the model to request their invocation, and a standard way to return results.
This formalization had an outsized impact. Once function calling was a reliable API feature rather than a prompt engineering trick, the ecosystem exploded. Every major LLM provider now supports it. Every major agent framework is built on top of it. It is, without exaggeration, the backbone of modern AI agent systems.
Let me go deep on how it actually works, where it breaks, and how to build production-grade function calling into your agents.
The Protocol Under the Hood
When you define a function/tool for an LLM, you are essentially writing an API specification that the model uses to make decisions. The model sees this specification and uses it to determine: should I call a function? which one? with what arguments?

Both OpenAI and Anthropic follow the same underlying principle: you declare a function's name, a description, and a JSON Schema defining its parameters — specifying types, allowed values, and which fields are required. The model interprets this specification to decide whether to call the function and what values to supply. The Anthropic format uses input_schema rather than nesting under function, but both are JSON Schema under the hood, which means you can use standard JSON Schema validation tools to verify your definitions.
The Critical Importance of Tool Description Quality
This cannot be said strongly enough: the description field is not documentation — it is behavior specification. The model uses descriptions to decide when to call a function and how to fill its parameters.
Consider a tool for database queries. Two descriptions:
Weak: "query_database": "Query the database"
Strong: "query_database": "Execute a read-only SQL query against the customer database. Use this to retrieve customer records, order history, or account information. Do NOT use this for financial transactions — use payment_api for those. Returns rows as a list of dictionaries."
The strong description tells the model:
- When to use this function (retrieving data)
- When NOT to use this function (financial operations)
- What it returns (list of dicts)
This specificity dramatically improves tool selection accuracy. I have seen teams improve their agent's tool selection accuracy from 72% to 91% purely by rewriting tool descriptions. The model capability did not change; the specification quality did.
Structured Outputs: Beyond Basic Function Calling
Modern API providers offer structured outputs — a stronger guarantee that the model's response will conform to a specified JSON Schema, not just that it will attempt to. OpenAI's Structured Outputs feature uses constrained decoding to guarantee schema conformance.
This is particularly valuable for multi-step data extraction — pulling structured information from unstructured text with guaranteed field types and required fields. The approach involves defining a typed data model — for example, a research summary with fields for title, authors, key findings, methodology, limitations, and publication year — and then passing that model directly as the expected response format when making an API call. The model cannot deviate from the schema; you receive a fully typed Python object rather than raw text you must parse yourself.

Using typed models with OpenAI's structured outputs gives you both schema validation (the model cannot deviate from the schema) and type safety in your Python code.
Parallel Function Calling
When a task requires multiple independent tool calls, modern APIs support parallel invocation — the model returns multiple function calls in a single response, and your runtime executes them concurrently.
The mechanics work as follows: when you send a prompt that requires multiple independent lookups — say, current weather in three different cities — the model responds with several tool call requests bundled together rather than one at a time. Your runtime then fires off all of those requests simultaneously using asynchronous execution, waits for all results to return, and packages them into a single follow-up message to the model. The model receives all results at once and synthesizes a final response.
The speedup from parallel tool calling can be dramatic. A sequential approach to fetching three independent data sources takes 3x the time of the slowest call. Parallel execution takes 1x. For agents making 10+ tool calls per task, this compounds significantly.
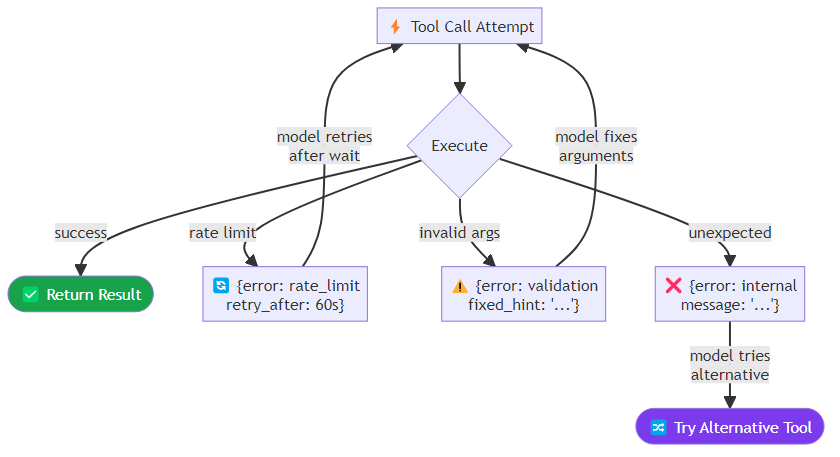
Error Handling in Tool Responses
Tool calls fail. APIs return errors, rate limits trigger, network timeouts occur. The question is not whether your tools will fail — they will — but whether your agent handles failures gracefully.
The mechanism for communicating tool failures back to the model is the tool result message itself. Rather than letting exceptions propagate and crash the workflow, a well-designed tool wrapper catches specific error types — rate limit errors, validation failures, unexpected exceptions — and returns a structured JSON response describing what went wrong. Each error type carries different information: a rate limit error includes how long to wait before retrying; a validation error includes what was wrong with the supplied arguments and how to correct them.
A well-designed error response includes enough information for the model to make a recovery decision: should it retry with different arguments? try a different tool? ask the user for clarification? escalate? The richer the error information, the more intelligently the model can handle failures.
Tool Choice Control
You can control whether the model is allowed to use tools, required to use tools, or forced to use a specific tool. The three modes are: auto, where the model decides on its own when to call tools; required, where the model must invoke at least one tool; and specific tool selection, where you name the exact tool the model must call. These three modes map onto three different orchestration needs — open-ended reasoning, extraction workflows, and deterministic pipeline steps, respectively.
The required and specific tool choice modes are useful in structured pipeline steps where you need to guarantee a particular type of output. An extraction agent that must always return structured data should use required or a specific tool to prevent the model from responding in plain text.
Security: Function Calling as an Attack Surface
Function calling is a code execution interface, and it carries the security implications of any code execution interface.
Argument injection: a malicious user might try to inject SQL, shell commands, or prompt injections through function arguments. Your tool implementations must validate and sanitize all inputs, regardless of whether they come from a user prompt directly or through the model. For database-facing tools, this means enforcing that only read operations are permitted — a pattern check on the incoming query string that rejects anything other than SELECT statements — and using parameterized queries for any user-supplied values rather than interpolating strings directly.
Scope limitation: each agent should only have access to the tools it needs. A customer service agent that can only read customer records (not modify them) has a smaller blast radius if compromised than one with full CRUD access.
Audit logging: log every tool call with arguments, response, and the user context that triggered it. This is essential for detecting abuse and debugging unexpected behavior.
Defining Tools Programmatically
For large tool sets, manually writing JSON schema definitions is error-prone. Frameworks like LangChain allow you to generate schemas automatically from your existing function definitions and typed parameter models. You define a Pydantic model for the function's inputs — each field annotated with a type and a human-readable description — write the implementation function, then let the framework derive the JSON schema from the model and register everything together as a tool.

This approach keeps your tool definitions DRY: the Pydantic model serves as both runtime validation and schema generation. Changes to parameter definitions are reflected automatically in both the JSON schema sent to the model and the validation applied to model outputs.
Function calling is mature enough that the basic mechanics should not be a significant engineering challenge in 2026. The differentiation is in the details: description quality, error handling, security posture, and parallel execution efficiency. Master those, and you have a solid foundation for every other capability in your agentic stack.


