
Expert performance in almost any cognitive domain requires the ability to step back from one's own work and evaluate it critically. A skilled programmer reads their code as if they had not written it, looking for the bugs their authoring perspective would have hidden. A good researcher reviews their own draft for logical gaps, unsupported claims, and alternative explanations. This metacognitive capacity — thinking about one's own thinking — is integral to expertise.
For a while, we assumed LLMs could not do this meaningfully. The model that generates an answer and the model that evaluates it are the same model in the same inference pass — how could it be both confident enough to generate and skeptical enough to critique? The answer, it turns out, is that with the right scaffolding, LLMs are remarkably capable self-evaluators. And systems that leverage this capability substantially outperform those that do not.
The Self-Consistency Baseline
The simplest form of self-reflection is self-consistency: generate multiple independent answers to the same question and select the most common one. Wang et al. (2022) showed that sampling multiple chain-of-thought reasoning paths and taking a majority vote significantly outperforms single-sample greedy decoding on arithmetic and commonsense reasoning benchmarks.
The implementation follows a straightforward pattern: the question is sent to the model multiple times with a non-zero temperature setting — meaning each run introduces slight variation — and the final answers are extracted from each response. A majority vote selects the winner, but only if enough responses agree; if fewer than 40% of samples converge on the same answer, the result is flagged as low-confidence rather than surfaced as definitive.
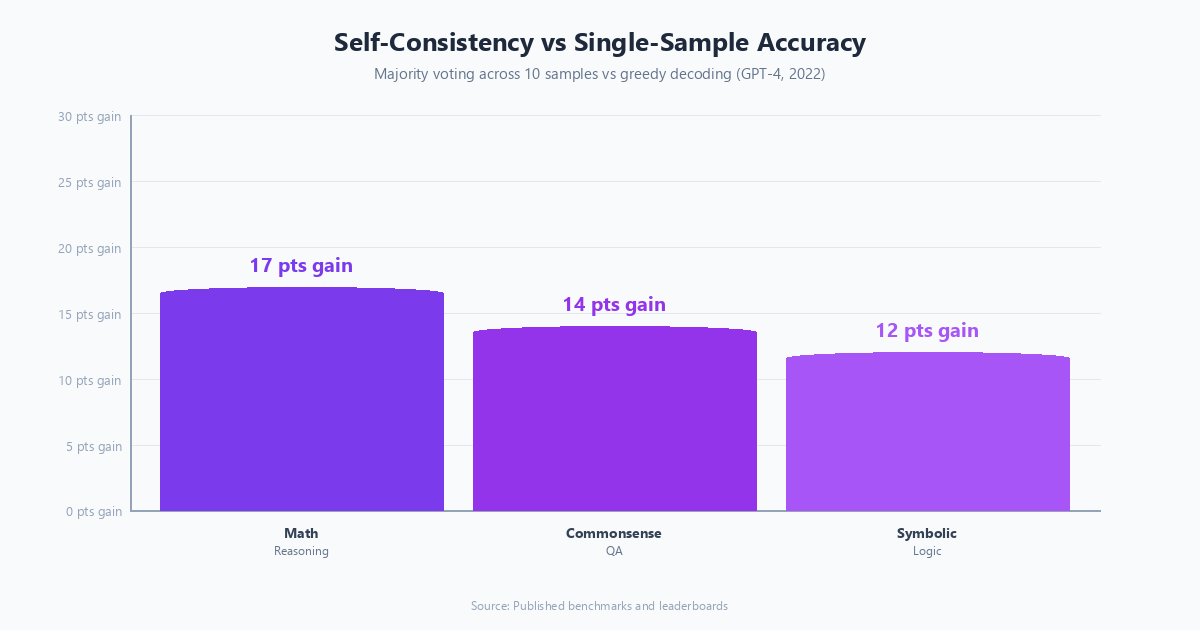
Self-consistency is effective but expensive: 10 samples means 10x the inference cost. It is appropriate for high-stakes decisions where the cost of a wrong answer exceeds the cost of additional inference, but not for interactive, latency-sensitive applications.
Reflexion: Learning From Failure
Shinn et al. (2023) introduced Reflexion, one of the most practically impactful self-reflection papers in agentic AI. The core idea: after an agent fails a task, have it generate a verbal reflection on why it failed, store that reflection in memory, and use it to guide future attempts.
A Reflexion agent maintains a list of past reflections that grows with each failed attempt. Before each new try, the agent receives its accumulated reflection history as context — effectively reading its own post-mortems before beginning again. After a failure, a structured prompt asks the agent to identify specifically what went wrong: what mistake did it make, what did it incorrectly assume, and what it will do differently next time. That reflection is stored and fed into the next attempt's context.

The Reflexion paper showed dramatic improvements: on HumanEval (Python programming), Reflexion with GPT-4 achieved 91% pass@1, compared to 48% for standard GPT-4. The same pattern of reflection-and-retry improved performance on sequential decision-making tasks and search-based QA.
The key insight: verbal reflection is a form of reinforcement signal that does not require gradient updates. The agent accumulates a verbal description of its failure modes and uses this as few-shot examples for avoiding the same mistakes. It is reinforcement learning via language, operating entirely at inference time.
Critique-and-Revise: The Editorial Loop
Beyond task-level reflection, self-reflection can be applied at the response level: generate an output, critique it, revise it based on the critique. This editorial loop pattern consistently improves output quality for writing, code generation, and analytical tasks.
The structure involves two sequential prompts. The first presents the original task and the initial draft together, asking the model to evaluate the draft across specific dimensions — technical accuracy, completeness, clarity, and conciseness, for example — and to be specific about what is good, what is lacking, and what should change. The second prompt presents the original draft alongside that critique and asks for an improved version that addresses the raised issues. The critique dimensions should be domain-specific: for code, you might evaluate correctness, efficiency, readability, and edge case handling; for a business analysis, you might focus on evidence quality, logical consistency, and consideration of alternatives.
Constitutional AI and Self-Evaluation Principles
Anthropic's Constitutional AI (Bai et al., 2022) applies self-reflection at the training level but the underlying technique — asking a model to evaluate its own outputs against a set of explicit principles — is applicable at inference time as well.
The idea: define a "constitution" — a set of principles the agent should adhere to — and ask the model to evaluate whether its output violates any of them before returning it. A practical inference-time constitution might include principles such as not making unverifiable claims, not recommending irreversible actions without explicit confirmation, and acknowledging uncertainty rather than projecting false confidence. The constitutional check evaluates each principle in sequence and, when it finds a violation, requests a revision that corrects the specific issue rather than regenerating from scratch.

Multi-Agent Debate as Self-Reflection
Du et al. (2023) showed that having multiple LLM instances debate an answer — each model seeing the others' reasoning and updating its position — outperforms single-model reflection. The key is that different instances of the model, when prompted to argue for different positions, genuinely identify different failure modes.
The debate pattern runs in two phases. First, each agent independently answers the question with a slightly elevated temperature to ensure variation. Then, in one or more debate rounds, each agent receives its own current answer alongside the other agents' answers and is asked whether any of those perspectives raise valid points it had missed — and either to update its position or defend it with additional reasoning. A final synthesis prompt reads all post-debate answers and produces the strongest consolidated response.
Debate is expensive — the number of agents multiplied by the number of rounds produces additional inference calls — but for high-stakes analytical tasks, the improvement in accuracy and the reduction in overconfident wrong answers is worth the cost.
Process Reward Models: Teaching Critique
A process reward model (PRM) is a model trained specifically to evaluate the quality of intermediate reasoning steps, not just final answers. OpenAI's work on PRMs for mathematical reasoning (Lightman et al., 2023) showed that rewarding correct intermediate steps produces better mathematical reasoning than rewarding only correct final answers.
In an agentic context, a PRM can be used to evaluate the quality of an agent's planning steps. It scores each step in context — examining the overall task, the steps completed so far, and the current step being evaluated — and flags trajectories that are trending poorly. If recent scores fall below a threshold, the agent can backtrack and try a different path rather than continuing down an unproductive chain of reasoning.
PRMs are not yet widely deployed outside of mathematical reasoning contexts, but they represent the leading edge of how self-reflection may be systematized in future agentic systems.
When to Apply Self-Reflection
Self-reflection adds inference cost and latency. Apply it selectively:
| Scenario | Recommended Technique |
|---|---|
| Math / coding with verifiable answers | Self-consistency + Reflexion |
| High-stakes analysis | Critique-and-revise + Constitutional check |
| Ambiguous or contested questions | Multi-agent debate |
| Long multi-step tasks | Step-level reflection and backtracking |
| Low latency required | None — route to more capable model instead |
The common thread across all these techniques: they treat the model's own reasoning as an object of inspection, not just a source of output. That metacognitive stance — reasoning about one's own reasoning — is both what makes expert human performance distinctive and what makes self-reflecting agents substantially more reliable.
Machines checking their own work is not science fiction. It is production-ready engineering.


