
Every complex system fails. The question is not whether your AI agent will encounter errors — it will — but whether those errors propagate into catastrophic failures or get handled gracefully at the right level of abstraction. Building resilient agents is not glamorous work. It does not make for impressive demos. It is also the difference between a prototype and a production system, between a system you can sleep soundly maintaining and one that keeps your on-call rotation awake.
I want to walk through the complete resilience stack for production AI agents: from low-level retry logic to high-level degradation strategies, with patterns that actually work.
The Failure Taxonomy
Before designing error handling, understand what can fail. For LLM agents, failures fall into five categories:
LLM API failures: rate limits, timeouts, server errors, context window exceeded, content policy blocks. These are transient (rate limits, timeouts) or deterministic (content policy, context overflow).
Tool execution failures: network errors, API authentication failures, malformed responses, data validation errors, permission errors. Each tool in your agent's toolkit is an external dependency that can fail independently.
Model output failures: malformed JSON in function calls, unparseable structured output, hallucinated function names, arguments that fail validation. These are not tool failures — the LLM successfully returned a response, but the response does not conform to expectations.
Logic failures: infinite loops, divergent planning, stuck states where the agent cannot make progress. These are the hardest to detect because the agent appears to be functioning but is not making progress toward the goal.
Downstream failures: the agent successfully calls a tool, the tool successfully executes, but the action it performs causes a downstream failure (writing bad data to a database, sending an incorrect email, triggering an unintended side effect).
Each category requires different handling strategies. Let me go through each.
Handling LLM API Failures
API failures are the most common and best-understood failure mode. The standard pattern is exponential backoff with jitter: a decorator wraps any LLM call and, on a transient error such as a rate limit or connection timeout, waits an increasing amount of time before retrying — up to a configurable maximum delay and retry count. Critically, the wait interval includes a random component (the jitter) so that multiple agents hitting the same rate limit do not all retry at precisely the same moment and overwhelm the API all over again.
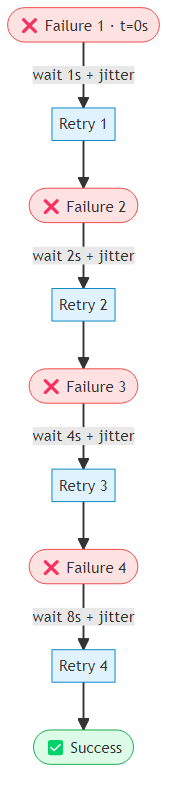
Jitter is important — without it, multiple agents hitting the same rate limit will retry at the same time, causing a thundering herd. Full jitter (random value between 0 and the base delay) distributes retries more evenly than decorrelated jitter in high-concurrency scenarios.
Context window errors require a different response from rate limits. Rather than retrying with the same input, the agent needs to compress its context before trying again. A practical compression strategy preserves the system prompt and the most recent turns of the conversation, then replaces the middle section with a condensed summary generated by the model itself. The result is a shorter message list that retains the essential history without exceeding the token budget.
Handling Model Output Failures
The model returns a response, but it is malformed. This is surprisingly common, particularly with smaller models or complex schemas. A robust parser makes multiple attempts in sequence: first, it tries to parse the raw response as JSON directly; if that fails, it looks for a JSON block inside a markdown code fence, which models often produce when they are trying to be helpful; and if neither works, it sends the malformed output back to the model with an explicit request to produce a corrected version conforming to the required schema. Only after all three attempts fail does it raise a parse error.
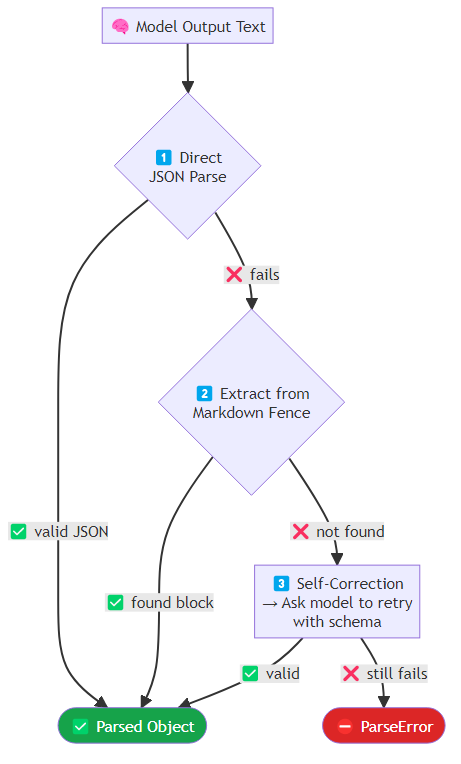
For function calling specifically, validate tool call arguments before execution. Each tool call should be checked in sequence: does the named tool exist in the registry? Can the arguments be parsed as valid JSON? Do the parsed arguments satisfy the tool's declared parameter schema? Each failure at these validation stages returns a structured error message rather than crashing, giving the model the information it needs to correct its next attempt.
Detecting and Breaking Logic Loops
Logic loops are insidious. The agent appears active — it is calling tools, generating reasoning — but it is not making progress. Common patterns: the agent keeps trying the same failing approach, the agent oscillates between two states, the agent generates plans it cannot execute and re-plans indefinitely.
Detection requires tracking progress, not just activity. A progress tracker maintains a rolling log of recent actions and a hash of the agent's state after each step. If the last several actions are drawn from a very small set — or if the state hash keeps returning to values already seen — the agent is stuck. The tracker can detect both monotonous repetition (calling the same failing tool over and over) and oscillation (bouncing between two actions without resolution).
When stagnation is detected, escalate: try a different strategy, request human intervention, or return a partial result with an explanation.
Graceful Degradation: Service Levels
True resilience means the system continues to provide value even when some components fail. Design explicit service levels: a full mode where all tools and capabilities are available, a reduced mode where some tools are unavailable but the agent works with what remains, a minimal mode where only the core language model is operational (no tool calls, with an explicit disclaimer to the user), and a degraded mode where even the LLM is unreachable and the system falls back to cached or static responses.
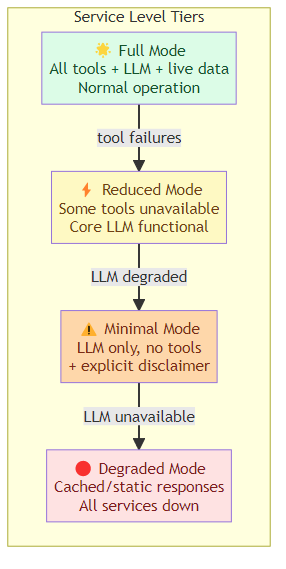
At startup and before handling each request, the agent runs health checks against its dependencies and selects the appropriate service level dynamically. This means a user interacting with the agent during a partial outage receives a degraded-but-functional response rather than an unhandled error.
Idempotency for Retried Actions
When a tool call fails and is retried, the runtime needs to know whether repeating the call is safe. Idempotent operations (reading data, running calculations) can be retried safely. Non-idempotent operations (sending emails, charging payment methods, creating records) must not be duplicated.
The solution is an idempotency key: before executing a non-idempotent tool, compute a hash of the tool name and its arguments and check a cache (such as Redis) for a prior result under that key. If a result exists, return it without re-executing. If not, execute the tool, store the result under the key with a 24-hour expiry, and return it. This guarantees exactly-once semantics even when the outer retry logic fires multiple times.
Observability for Resilience
You cannot manage what you cannot see. Every retry, every fallback, every circuit breaker activation should be logged and counted. A well-instrumented agent exports metrics for tool call outcomes (success or error, by tool name), retry counts (broken down by component and error type), circuit breaker state (open or closed, per dependency), and current service level. These metrics feed dashboards and alerts. If you want to go deeper on the observability layer — distributed tracing of every LLM call, tool execution, and state transition — see The Missing Discipline: AI Agent Harness Engineering which covers the full four-layer harness architecture including the observability stack.
An alert that fires when retry counts spike is your early warning system for dependency degradation. An alert on circuit breaker state tells you a service is down before your on-call rotation hears about it from users.
The Resilience Mindset
Building resilient agents requires a shift in how you think about failure. In research code, failures are exceptions that interrupt the happy path. In production code, failures are a normal operating condition that the system is designed to handle.
Design your agent as if every component will fail, every API will have rate limits, every model output might be malformed, and every external dependency might be temporarily unavailable. Then build the handling layer for each failure mode, test it explicitly, and monitor it in production.
The agents that earn user trust are not the ones that are impressive when everything works. They are the ones that remain useful — if necessarily constrained — when things go wrong. That is what resilience means.
Related posts: Structured Output from AI Agents — structured output enforcement and self-correction. Advanced Tool Use Patterns — fallback strategies and tool orchestration resilience.


