An AI agent that says "The customer's order has been shipped" is easy to evaluate — you read it and understand it.
An AI agent that needs to write {"order_id": "12345", "status": "shipped", "carrier": "FedEx", "tracking": "XYZ789"} to a database — that's a different engineering challenge. And it's the challenge that separates chat-style agents from production-grade agentic systems that integrate with real infrastructure.
Structured output is required whenever the agent's output must be consumed by another system: tool arguments, database writes, API responses, form submissions, configuration updates. Every time the agent talks to a machine instead of a human, structured output matters.
The Parse Failure Problem
The fundamental issue: LLMs generate text, not data. They can be prompted to produce JSON, but they're not guarantee it. Studies show that even frontier models fail to parse correctly in 5-15% of cases without structural enforcement.
Expected: {"name": "John", "age": 30}
LLM output: "Here's the JSON: {name: 'John', age: 30}" ← parse fails
LLM output: {"name": "John", "age": "thirty"} ← type mismatch
LLM output: {"name": "John"} ← missing field
LLM output: "{name: John, age: 30}" ← invalid JSON
Parse failures fall into three categories:
- Format failures: output isn't valid JSON/XML/etc. (missing braces, bad syntax)
- Schema failures: valid JSON but wrong types, missing required fields, extra unknown fields
- Semantic failures: valid JSON that passes schema check but contains wrong or nonsensical data
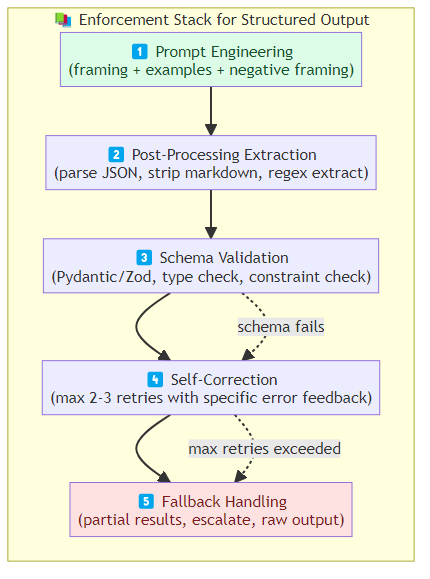
The Enforcement Stack
Production structured output requires a layered approach:
Layer 1: Prompt Engineering
Prompt the model explicitly for structured output. This is the first line of defense and catches the majority of failures.
System: You are a structured data extraction agent. Always output valid JSON.
Never include explanatory text, markdown fences, or code blocks.
Output ONLY the JSON object.
User: Extract order details from this email: [...]
Key prompt techniques:
- Format specification: "Output valid JSON matching this schema: {...}"
- Negative framing: "Never output anything other than the JSON object"
- Examples: provide 2-3 input→output examples that demonstrate the expected format
Layer 2: Post-Processing Extraction
After the LLM generates output, extract the structured data from whatever the model produced. The model might wrap JSON in markdown fences, prepend explanatory text, or produce partial JSON — extract what's there.
def extract_json(output: str) -> dict | None:
# Try direct JSON parse
try:
return json.loads(output)
except json.JSONDecodeError:
pass
# Try extracting from markdown fence
match = re.search(r'```json\s*(.+?)\s*```', output, re.DOTALL)
if match:
try:
return json.loads(match.group(1))
except json.JSONDecodeError:
pass
# Try extracting raw JSON-like content
match = re.search(r'\{.+\}', output, re.DOTALL)
if match:
try:
return json.loads(match.group(0))
except json.JSONDecodeError:
pass
return None
Layer 3: Schema Validation
After parsing, validate against the expected schema. Use a schema validator (Pydantic, Zod, JSON Schema) that catches type mismatches, missing fields, and constraint violations.
class OrderStatus(BaseModel):
order_id: str
status: Literal["shipped", "processing", "delivered", "cancelled"]
carrier: Optional[str]
tracking: Optional[str]
@field_validator("order_id")
def validate_order_id(cls, v):
if not re.match(r'^[A-Z0-9]{8,12}$', v):
raise ValueError("order_id must be 8-12 alphanumeric characters")
return v
Layer 4: Self-Correction
When parse or schema validation fails, attempt automatic correction:
Attempt 1: LLM produces output → parse fails → ask LLM to fix
"The JSON was invalid. Return ONLY the JSON object with no markdown."
Attempt 2: LLM produces output → parse succeeds → schema fails → ask LLM to fix
"The JSON was valid but 'age' was a string instead of an integer. Return the corrected JSON."
Implement a max-retries self-correction loop (typically 2-3 attempts). Each retry should include the specific error that caused the failure so the LLM can address it.
Layer 5: Fallback Handling
After max retries, fall back gracefully. Options:
- Return a partial result with explicit error flags
- Fall back to a simpler output format (natural language with parseable keywords)
- Escalate to human review
- Return the raw output and let the downstream system handle it with awareness
Tool Output vs. Agent Output
There are two distinct structured output contexts with different requirements:
Tool Arguments
The agent produces input to tool calls. The schema must be precise, types must be exact, and constraints must be enforced. A tool argument with the wrong type causes the tool to fail.
Tool output design:
- Use strict type schemas (Pydantic with constrained types)
- Add field-level documentation so the LLM understands the constraints
- Include example valid inputs in the tool description
- Validate before calling the tool, not after
Agent Responses
The agent produces output that's consumed by downstream systems or displayed to users. Less strict than tool arguments — natural language can wrap structured data, and graceful degradation is more acceptable.
Response output design:
- Separate structured data from natural language explanations
- Use a consistent wrapper format (e.g., always return
{"data": {...}, "explanation": "..."}) - Validate critical fields, accept partial validity for optional ones
Schema Evolution
Production agents evolve. Tools get new parameters. Output schemas change. The agent must handle both old and new schema versions during migration.
Schema versioning strategies:
- Additive changes: add new optional fields without breaking existing parsers
- Deprecated fields: mark old fields as deprecated, have the LLM emit both old and new until migration is complete
- Schema negotiation: the agent declares which schema version it expects, the tool returns data in that format
Performance Implications
Structured output has a hidden cost: it consumes more tokens (schema definitions, examples, validation feedback) and requires additional processing steps (parse, validate, self-correct).
For high-frequency, low-stakes tool calls (e.g., classification), this overhead may not be worth it. For low-frequency, high-stakes outputs (e.g., payment authorization), it's essential.
Profile the overhead for your specific use case. Structured output overhead typically ranges from 5-30% token increase and 10-50ms additional processing time per call.
The Bottom Line
Structured output from LLMs isn't a solved problem — it requires a layered enforcement stack: prompt framing, post-processing extraction, schema validation, self-correction, and graceful fallback.
The key insight: don't trust the LLM to produce correct structured output. Assume it will fail, build the recovery mechanisms, and validate everything.
Production agentic systems that integrate with real infrastructure need structured output everywhere the agent talks to a machine. Build the enforcement stack once, make it reusable, and apply it consistently.
Related posts: Advanced Tool Use Patterns — tool schema design and result processing. Building Resilient Agents — error handling and self-correction patterns. Agentic RAG — structured data extraction in agentic workflows.


