The Oscars ruled that AI-generated actors and scripts are ineligible for awards. The OpenAI lawsuit continues. xAI reportedly trained Grok on OpenAI models. These aren't just news stories — they're signals of a broader reckoning with AI agent agency and accountability.
Security for AI agents isn't theoretical anymore. Enterprises deploying agents that send emails, access databases, execute code, and make decisions need defense implementations, not just threat models.
This post is the companion to the threat models piece: how to actually build the defenses.
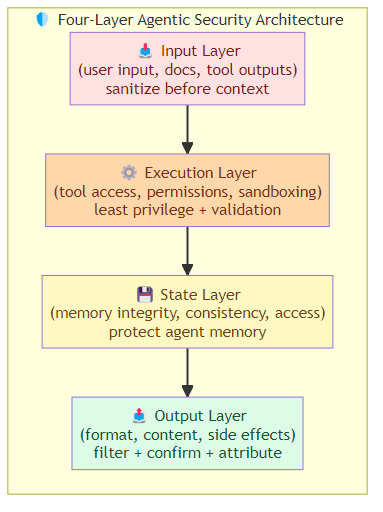
The Defense Architecture
A complete agentic security architecture has four layers:
- Input Layer: sanitize everything the agent receives (user input, retrieved documents, tool outputs)
- Execution Layer: control what the agent can do (tool access, permissions, sandboxing)
- State Layer: protect the agent's memory and context (integrity, consistency, access)
- Output Layer: validate everything the agent produces (format, content, side effects)
Each layer operates independently and catches different failure modes. The input layer can't prevent state manipulation. The output layer can't prevent tool poisoning. Defense in depth.
Input Sanitization Pipeline
The input layer is the first line of defense. Everything that enters the agent's context — user messages, retrieved documents, tool outputs, system prompts — must be sanitized before it reaches the LLM.
User Input Sanitization
User input is the most likely injection vector. Implement:
Instruction boundary enforcement: distinguish user content from system instructions. If a user message contains "Ignore previous instructions" or embedded directives, detect and neutralize them.
# Simple pattern-based detection
def detect_instruction_injection(text: str) -> bool:
patterns = [
r'ignore (previous|all) (instructions|commands)',
r'system prompt',
r'override',
r'#ansi.*?system',
]
return any(re.search(p, text, re.IGNORECASE) for p in patterns)
# If detected: strip the suspicious content, log the attempt, continue
Length and complexity limits: cap input length and structure complexity. Excessive nesting, extremely long inputs, or inputs with unusual structure patterns are indicators of injection attempts.
Structured input parsing: for inputs that should be structured (forms, API calls), parse and validate against a schema before passing to the agent. Reject malformed inputs.
Document Retrieval Sanitization
Indirect prompt injection is the hardest threat. The agent retrieves content from the web, documents, databases — and that content may contain adversarial instructions.
Content scanning: before loading retrieved content into context, scan for injection patterns:
- Unusual formatting (hidden text, CSS injection, zero-width characters)
- Instruction patterns (imperative commands embedded in prose)
- Role-playing instructions ("You are now...")
- HTML/script injection attempts
Segmentation with provenance: tag each piece of retrieved content with its source. The agent sees content as "[From: web_search(query='X')]" not as if it were user input. This helps the agent reason about content reliability.
Freshness and source scoring: rate retrieved content by reliability. Peer-reviewed papers score higher than forum posts. Government .gov sites score higher than anonymous paste bins. Weight retrieval accordingly.
Tool Output Sanitization
Tool outputs are trusted too readily. A compromised web search API could return malicious content. A poisoned database record could contain injection instructions.
Output validation: validate tool outputs against expected schemas and content patterns before passing to the agent. Reject outputs that don't match the tool's documented contract.
Content filtering: scan tool outputs for known injection patterns. This is redundant with document retrieval sanitization but catching it at the tool layer adds defense.
Tool Access Control
The tools the agent can call define its agency. If the agent can call any tool with any arguments, it has too much power.
Least Privilege Tool Assignment
Each task type should have the minimum tool set required. A customer service agent answering questions doesn't need a delete_data tool. A code reviewer doesn't need send_email.
Task: customer_inquiry
Allowed tools: [search_knowledge_base, lookup_order_status, suggest_actions]
Forbidden tools: [delete_data, send_email, execute_code, modify_permissions]
Task: developer_task
Allowed tools: [read_files, execute_code, run_tests, commit_code]
Forbidden tools: [send_email, delete_data, access_hr_records]
Tool Argument Validation
Before executing any tool, validate the arguments:
- Type correctness (strings are strings, integers are integers)
- Range validation (IDs match expected patterns, dates are valid, file paths are within allowed directories)
- Permission checks (is the agent authorized to perform this action for this resource?)
Sandbox Execution
Any tool that executes code, runs shell commands, or accesses external systems should run in a sandboxed environment:
- Containerized execution with resource limits (CPU, memory, network)
- Read-only filesystem except for designated workspace
- Network access disabled or restricted to allowed domains
- No root/privileged execution
Memory Integrity
The agent's memory is a critical attack surface. If an attacker can manipulate the agent's memory, they can change its behavior without directly interacting with it.
Memory Access Controls
Limit which components can write to memory:
- Tool outputs can append to episodic memory but not overwrite semantic memory
- User inputs can trigger memory retrieval but not direct memory writes
- Only validated, sanitized content gets stored in any memory layer
Memory Integrity Verification
Periodically verify memory integrity:
- Check semantic memory for internal consistency (facts that contradict each other)
- Verify episodic memory for injection patterns (instructions hidden in memory entries)
- Validate procedural memory for unauthorized behavior modifications
Memory Sealing
For high-stakes sessions, implement memory sealing: once a session reaches a certain state, additional memory writes are prohibited. The agent can continue functioning but cannot alter its memory. This prevents manipulation of completed transactions.
Output Filtering
The output layer ensures the agent's responses are safe before they reach users or trigger external actions.
Content Safety Filtering
Filter output for:
- PII leakage (names, emails, phone numbers, addresses in unexpected contexts)
- Malicious content (instructions, exploits, attack payloads)
- Confidential data (internal documents, credentials, access tokens)
- Policy violations (content that violates organizational policies)
Action Confirmation
Before executing write actions (sending emails, modifying records, triggering payments), require explicit confirmation. Not just "should I do this?" but "here is exactly what I'm about to do, and here is the verification that I have permission to do it."
Output Attribution
Every output should be traceable: which input triggered it, which tools were called, what reasoning led to it. This creates the audit trail necessary for security review and compliance.
The Defense-in-Depth Principle
No single security measure is sufficient. The input layer misses sophisticated injection. Tool access control misses state manipulation. Memory integrity checks miss output leakage.
Build all four layers. Expect attacks to bypass individual layers. Design the system so that bypassing any single layer isn't sufficient to cause harm.
Monitor for patterns: if input sanitization triggers frequently, investigate. If output filtering catches content, log and analyze. Security is a continuous operation, not a one-time implementation.
Related posts: Agentic AI Threat Models — the six threat categories and 5-layer defense framework. Observability for AI Agents — monitoring for security anomalies. AI Agent Harness Engineering — the execution layer where security controls live. AI Agent Governance — the policy and compliance layer for autonomous AI agents.


