The Academy of Motion Picture Arts and Sciences just ruled that AI-generated actors and scripts are ineligible for Oscars. Anthropic is reportedly raising at a $900B+ valuation. OpenAI and Anthropic both launched enterprise joint ventures.
The enterprise AI market is maturing fast — and enterprise buyers are asking harder questions about oversight. "What happens if the agent does something wrong?" isn't a philosophical question anymore. It's a compliance requirement.
Human-in-the-loop (HITL) is the standard answer. But most HITL implementations are theater: they pause the agent, show a modal that says "approve or reject," and let the human click a button. This satisfies auditors but doesn't actually improve safety.
Real HITL design is harder. It requires deciding what to show, what to ask, how to present context efficiently, and what to do when the human is unavailable. This is the engineering framework.
Why Most HITL Implementation Fails
The standard failure mode: HITL is added as an afterthought. The agent reaches a decision point, the system pauses, a human sees a vague summary, and clicks approve or reject with no real ability to evaluate the decision.
Problems with naive HITL:
- Context starvation: the human sees a summary, not the full context needed to evaluate the decision
- Decision paralysis: too many checkpoints overwhelm humans, leading to rubber-stamping
- Latency accumulation: every HITL pause adds latency, creating pressure to minimize or skip checkpoints
- Unavailability failure: the human isn't online when needed, blocking the agent indefinitely
- No escalation path: when the human says "I don't know," the agent is stuck
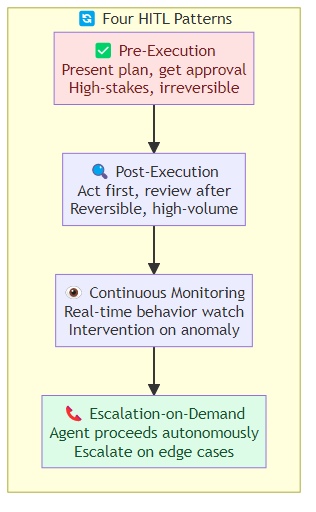
The Four HITL Patterns
Pattern 1: Pre-Execution Approval
The agent presents its planned action before executing it. The human approves or modifies the plan.
Best for: high-stakes actions (sending emails, making payments, deleting data) where reversal is costly or impossible.
The challenge: the human must understand the action well enough to evaluate it. This requires presenting context, the agent's reasoning, the expected outcome, and the alternatives considered.
Agent: "I plan to send the following email to customer@example.com:
Subject: Order #12345 status update
Body: 'Your order has been shipped and will arrive by May 15th.'
Reasoning: Customer asked about order status. Order #12345 status is 'shipped'
with carrier tracking XYZ. Estimated delivery is May 15th based on carrier data.
Risk: None identified. This is a standard status update.
Alternatives considered: None — this is a direct response to customer query."
[Approve] [Modify] [Reject]
Pattern 2: Post-Execution Review
The agent acts first, then a human reviews the result before it's finalized.
Best for: reversible actions where the cost of delay outweighs the cost of correction. Monitoring dashboards, content drafts, generated reports.
The challenge: the agent may produce irreversible side effects before review. Design for undo-ability or rollback.
Pattern 3: Continuous Monitoring
The human doesn't approve individual actions — they monitor the agent's behavior and intervene when something looks wrong.
Best for: high-volume, low-stakes tasks where individual review isn't feasible but behavioral monitoring is valuable.
The challenge: requires real-time dashboards, anomaly detection, and fast escalation paths. Humans can't monitor every action, so the system must surface the actions that actually need attention.
Pattern 4: Escalation-on-Demand
The agent proceeds autonomously until it encounters a situation it can't handle — then it escalates.
Best for: well-understood task distributions where the agent handles 90%+ of cases autonomously, with rare edge cases requiring human judgment.
The challenge: the agent must accurately recognize when it needs help. Under-escalation produces failures. Over-escalation defeats the purpose of autonomous operation.
Designing Effective Checkpoints
A checkpoint is effective only if it helps the human make a better decision. The design must address:
What to Show
The human needs enough context to evaluate the decision without drowning in detail.
The checkpoint summary template:
- What the agent is about to do (or did)
- Why it's doing it — the reasoning chain that led to this action
- What it expects the outcome to be
- What could go wrong — explicit risk assessment
- What alternatives were considered and why they weren't chosen
- What the human can do — approve, reject, modify, escalate
What to Ask
Don't just ask "approve or reject." Ask the question that actually matters:
- "Should I proceed with this action, or would you like me to modify it?"
- "This action involves customer PII. Do you authorize this?"
- "The agent's confidence is low (0.42). Would you like to review the full context?"
- "I've been attempting this task for 10 minutes without success. Should I continue trying or escalate?"
How Long to Wait
Timeout design is critical. Wait too long and the system is unusable. Wait too short and human review is meaningless.
Timeout strategy by checkpoint type:
- Pre-execution approval: 5-30 minutes (depending on action urgency)
- Post-execution review: 24 hours (batch review acceptable)
- Escalation-on-demand: immediate availability expected, with fallback to queue
Graceful degradation: if the human doesn't respond within the timeout:
- Retry with increased urgency (for non-critical tasks)
- Proceed with caution (reduced scope, increased monitoring) for critical tasks
- Escalate to an on-call reviewer for high-stakes tasks
- Never silently proceed past a critical checkpoint
How to Handle Modifications
When a human modifies an agent action, the modification itself must be evaluated:
- Does the modification introduce new risks?
- Is the modification consistent with the user's intent?
- Should the modification update the agent's behavior for future similar cases?
The Checkpoint Economy
Every checkpoint has a cost: latency, human attention, and operational burden. Too many checkpoints make the system unusable. Too few make it unsafe.
Checkpoint placement heuristics:
- Place checkpoints before irreversible actions (write, delete, send, spend)
- Place checkpoints before actions with high-stakes outcomes (medical, legal, financial)
- Place checkpoints when confidence is below threshold
- Place checkpoints on first-time actions or edge cases
- Skip checkpoints for routine, low-stakes, high-frequency actions
The checkpoint density metric: measure the ratio of checkpoint pauses to total agent actions. If it's too high (>20%), consider removing low-value checkpoints. If it's too low (<1%), audit whether you're catching the right failure modes.
HITL for Different Stakeholders
Different stakeholders need different HITL interfaces:
End users: simple, plain-language explanations of what the agent did and why. "The agent accessed your profile information to personalize responses." Consent and transparency, not technical detail.
Operators/IT: full context, tool call history, decision reasoning. Debug capability, not just approval.
Compliance/Audit: immutable audit logs of all decisions, approvals, and modifications. Compliance reports, not human interfaces.
Managers: aggregated metrics on agent behavior, exception rates, escalation frequency. Not individual action review.
The Bottom Line
HITL isn't a single design pattern — it's a spectrum from fully manual to fully autonomous, with checkpoints distributed throughout based on risk, stakes, and reversibility.
Build HITL intentionally, not as an afterthought:
- Classify actions by risk and reversibility
- Match checkpoint patterns to action types
- Design checkpoint summaries that enable actual evaluation
- Build graceful degradation when humans are unavailable
- Measure checkpoint effectiveness and adjust density
The goal isn't to slow agents down. It's to ensure that when agents make mistakes, the cost of those mistakes is bounded.
Related posts: AI Agent Harness Engineering — the execution layer where HITL lives. Observability for AI Agents — monitoring frameworks that support HITL. Agentic AI Threat Models — security implications of autonomous agent action.


