
In the early days of multi-agent systems, communication was an afterthought. You had agents, you had tasks, and you passed strings between them. The agent that received a string would process it, produce another string, and pass it along. This worked well enough for demos and small systems, and it completely fell apart as systems grew.
The problem is not the string-passing itself — it is what strings fail to encode. A string does not carry type information, schema, capability declarations, or trust context. When Agent A sends Agent B a string, Agent B does not know whether that string is a task specification, an intermediate result, an error message, or a social nicety. It does not know what Agent A can do, what permissions it has, or whether it can be trusted. Scaling multi-agent systems requires answers to all of these questions.
The field is converging on answers, though the standardization is still in progress. Here is where things stand.
The Message Passing Foundation
Every multi-agent communication protocol starts from message passing. An agent sends a message, another agent receives it. The variation is in what structure that message carries.
The minimal viable structure is a typed message envelope. Each message carries a unique ID, the sender and recipient identities, a message type that declares the message's role in the conversation (task, result, error, query, or response), and the actual content payload. A correlation ID links related messages together — for example, connecting a response back to the original request that triggered it — which is essential for asynchronous communication patterns where many requests may be in flight simultaneously. A timestamp and a metadata dictionary round out the envelope, giving downstream consumers everything they need to log, route, and debug message flows without parsing the content itself.
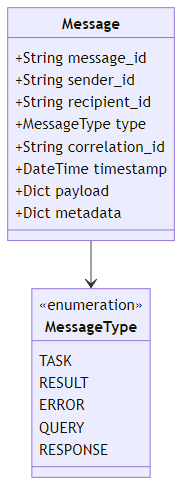
The correlation_id field is critical for multi-turn interactions: it links a response back to the original request, enabling the sender to match responses to outstanding requests even in asynchronous communication patterns.
Model Context Protocol (MCP)
Anthropic's Model Context Protocol, released in November 2024 and rapidly adopted across the industry, addresses a specific but critical communication problem: how should AI agents communicate with external tools and data sources?
Before MCP, every tool integration required bespoke code. An agent that needed to access a database, search the web, and read files required three different integration implementations, often with different authentication patterns, different error handling approaches, and different output formats. MCP standardizes this by defining a protocol through which AI models can discover and interact with capabilities exposed by "MCP servers."
The MCP architecture has three components:
MCP Servers expose capabilities (tools, resources, prompts) through a standardized interface. A server might expose filesystem access, database queries, API integrations, or custom business logic. The server declares its capabilities in a structured manifest.
MCP Clients are AI applications (like Claude, or any LLM-powered agent) that connect to servers and use their capabilities. The client queries the server for available tools, invokes tools with structured arguments, and receives structured results.
The MCP Transport Layer handles the actual communication — typically via stdio (for local servers) or HTTP+SSE (for remote servers).
An MCP server implementation declares its available tools in a structured manifest: each tool has a name, a human-readable description, and a JSON Schema that specifies the expected input parameters and their types. When an agent invokes a tool, the server validates the arguments against the schema, executes the corresponding logic, and returns a structured text result. The server registers these handlers on startup and then listens for incoming connections over its configured transport. This uniform interface means any MCP-compatible client — Claude, a custom LLM agent, a development tool — can discover and invoke the server's capabilities without custom integration code.
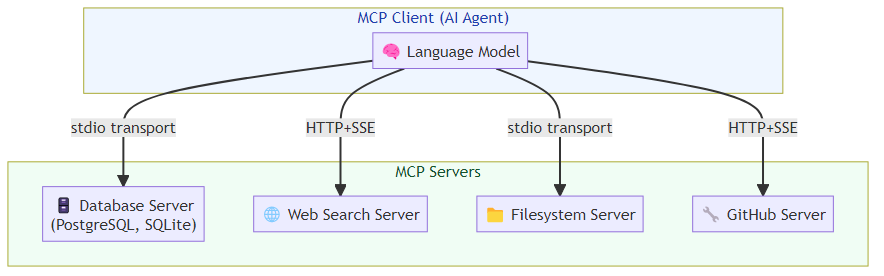
The power of MCP is standardization. An agent that speaks MCP can connect to any MCP server without custom integration code. The ecosystem of MCP servers is growing rapidly — there are now hundreds of community-built servers for databases, APIs, development tools, and enterprise systems.
Agent-to-Agent (A2A) Communication
MCP handles agent-to-tool communication. The complementary challenge is agent-to-agent communication: how should two AI agents negotiate tasks, share intermediate results, and coordinate on complex workflows?
Google's Agent-to-Agent (A2A) protocol (2025) addresses this. A2A defines how agents can:
- Discover other agents and their capabilities via "Agent Cards" (structured capability declarations)
- Negotiate task assignment through a defined message schema
- Exchange intermediate artifacts with provenance tracking
- Handle task delegation and result aggregation
The Agent Card is a key concept. It is a structured JSON document that a prospective caller can fetch to understand what a given agent can do: the agent's identity and description, a list of its capabilities with their input and output schemas, typical performance characteristics like average latency and cost per call, a trust level declaration, and the endpoint and authentication methods required to invoke it. This self-describing format means orchestrators can dynamically discover and reason about available agents without hardcoded configuration.
A2A is more opinionated than MCP — it includes notions of task status, agent trust levels, and cost declarations that MCP does not have. This makes A2A better suited for enterprise deployments where agents from different vendors or teams need to interoperate with explicit capability contracts.
In-Framework Communication Patterns
Within single-framework deployments (LangGraph, AutoGen, CrewAI), communication patterns are more constrained and more reliable because the framework controls the message format, delivery, and acknowledgment.
Shared state (LangGraph's approach): Agents do not send messages to each other; they read from and write to a shared state object. This eliminates message delivery failures and ensures consistency, at the cost of requiring explicit state schema design.
Chat messages (AutoGen's approach): Agents communicate through structured chat messages with roles (user, assistant, function, system). This maps naturally to how LLMs are trained and makes conversation history the primary communication medium.
Task context (CrewAI's approach): Agents receive task descriptions and the outputs of upstream tasks as their communication channel. The framework handles passing outputs between tasks.
Each approach has implications for debugging: shared state gives you a single object to inspect; chat messages give you a full conversation transcript; task context gives you per-task output files.
Trust and Authentication Between Agents
As agent systems move to production, inter-agent trust becomes a security-critical concern. When Agent B receives a message from Agent A, how does it know the message is authentic? How does it know Agent A has the permissions it claims?
Current best practices mirror standard service-to-service authentication in microservices:
JWT tokens with agent identity claims. When Agent A sends a message to Agent B, it includes a signed JWT that declares its identity, its permission scope, and the task context. Agent B validates the JWT before processing the message.
Capability attestation. Each agent should declare what permissions it has been granted, and receiving agents should validate that the sender's declared permissions are sufficient for the requested action.
Message provenance chains. In multi-hop workflows (Agent A delegates to Agent B which delegates to Agent C), the provenance chain should be preserved so that the final executor can verify that the original authorization is legitimate.
The emerging standards (MCP's authentication model, A2A's trust levels) are starting to address this, but the tooling for inter-agent trust is still immature compared to what exists for human-facing authentication. This is an area where investing in custom security infrastructure is likely to pay off as agent systems scale.
What the Protocol Landscape Tells Us
The rapid development of MCP, A2A, and related protocols signals something important: the industry has recognized that agent interoperability requires standardization, and that standardization is worth the coordination cost. This is the same transition that happened in web APIs (REST conventions, then OpenAPI), in data exchange (CSV, then JSON, then Parquet), and in messaging (custom protocols, then AMQP, then Kafka).
We are in the early standardization phase. The protocols that survive will be the ones that balance expressiveness (can they capture what agents actually need to communicate?) with simplicity (can developers implement and debug them without specialized expertise?). MCP's current momentum suggests it has found a good point in that design space, at least for tool communication. Agent-to-agent protocols are less settled.
Design your systems today to minimize tight coupling between agents, to use structured message formats that can be logged and debugged, and to anticipate that the protocols will evolve. The investment in clean inter-agent interfaces will pay dividends as the standards mature.
Related posts: Advanced Tool Use Patterns — the tool orchestration layer built on top of communication protocols. Multi-Agent Coordination Protocols — coordination patterns for multi-agent systems.
Explore more from Dr. Jyothi


