
Microsoft Research's AutoGen arrived with a deceptively simple observation: the most effective way for multiple AI agents to collaborate on complex tasks is through structured conversation. Not API calls, not shared state objects, not message queues — conversation. Agents talk to each other, they question each other's outputs, they propose solutions and critique them, and through this iterative dialogue they produce better results than any single agent working alone.
This is either a profound insight or an expensive way to run inference, depending on how well you design the conversation structure. Having worked extensively with AutoGen across coding, research, and analysis tasks, I can tell you it is genuinely both, and the art is knowing when the expense is worth it.
AutoGen's Conversational Architecture
AutoGen v0.4 (the current production release) is built around a fully asynchronous, event-driven architecture. The core abstractions are ConversableAgent — an agent that can participate in conversations — and various conversation patterns that structure how agents interact.
The fundamental insight is that conversations naturally encode iterative refinement. When a human reviews a colleague's work and provides feedback, that is a conversation. When a test suite reports failures to a developer, that is a conversation. AutoGen formalizes this pattern and makes it composable.
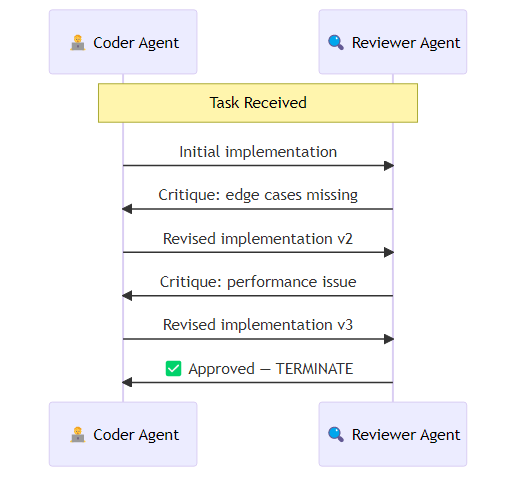
In a typical two-agent setup, a coding agent and a reviewer agent are each configured with system prompts that define their role and success criteria. The coding agent receives a task description and produces an initial implementation. The reviewer evaluates that implementation against explicit criteria — correctness, edge case handling, performance, code quality — and either approves it or returns specific, actionable feedback. The coding agent then revises and resubmits. The conversation terminates when the reviewer signals approval or when a maximum message count is reached. This pattern — generate, critique, revise — is where AutoGen genuinely outperforms single-agent approaches. The reviewer agent provides a forcing function for quality that single-agent self-reflection does not reliably achieve.
The UserProxy and Human-in-the-Loop
One of AutoGen's distinctive features is the UserProxyAgent — an agent that represents a human in the conversation and can execute code on their behalf.
AutoGen provides a CodeExecutorAgent that closes the loop between code generation and validation. Rather than simply producing code as text output, this agent actually runs the generated code in a controlled environment — typically a Docker container configured with the appropriate language runtime, a timeout to prevent runaway execution, and an isolated working directory for any files the code might create or modify. The coder writes code, the executor runs it, the results — including any error messages or stack traces — feed back into the conversation, and the coder iterates. This self-debugging loop is where AutoGen delivers some of its most impressive results on coding benchmarks.
The Docker executor is important here — running LLM-generated code in an isolated container rather than the host environment is a basic security requirement for production deployments.
GroupChat: When Multiple Agents Need to Deliberate
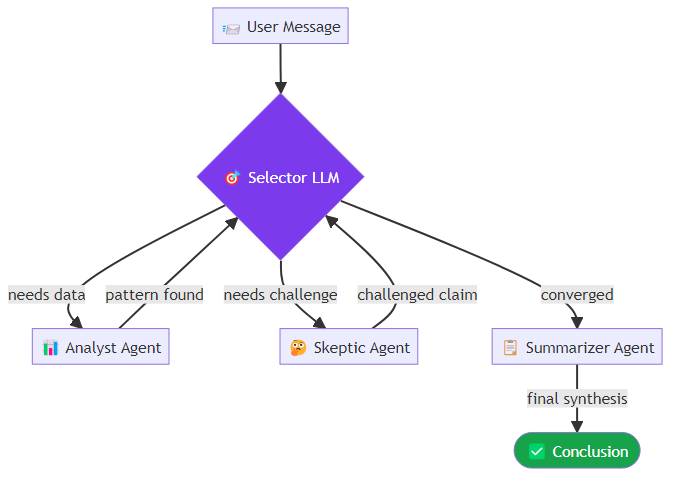
For tasks that benefit from multiple perspectives, AutoGen's GroupChat (or its newer SelectorGroupChat variant) allows more than two agents to participate.
A three-agent deliberative setup might include a data analyst whose role is to surface patterns and statistical signals, a skeptic whose role is to challenge assumptions and demand evidence before accepting claims, and a summarizer whose role is to synthesize the discussion into actionable conclusions. With SelectorGroupChat, a separate selector model reads the conversation at each turn and decides which agent should speak next based on context — routing to the skeptic when a claim needs challenging, to the summarizer when the discussion has converged sufficiently. SelectorGroupChat uses a selector LLM to decide which agent should speak next based on the conversation context. This is more natural than round-robin for deliberative tasks, but it adds another LLM call per turn and introduces routing errors — occasionally the wrong agent is selected at a crucial point.
AutoGen Studio and the Low-Code Interface
AutoGen Studio provides a web-based interface for building and testing agent workflows without writing code. It is genuinely useful for exploring AutoGen's capabilities and for stakeholders who need to understand what agents are doing without reading Python.
I use AutoGen Studio primarily for two purposes: rapid prototyping of new agent configurations before committing to code, and demonstrating agent behavior to non-technical stakeholders. For production deployment, I always move to the Python API — Studio's visual workflows do not expose all configuration options and add an abstraction layer that makes debugging harder.
Performance Characteristics
AutoGen's conversational approach has specific performance characteristics you need to plan for.
Token costs are multiplicative. In a two-agent conversation with 5 turns, you pay for 5 LLM calls on each agent, each with a growing conversation history in context. A task that a single agent might complete in 3 calls might require 10-15 calls in a two-agent AutoGen workflow. Whether the quality improvement justifies the cost depends on the task.
Latency compounds. Sequential conversation turns cannot be parallelized. If each turn takes 3 seconds and you average 10 turns per task, your per-task latency is 30 seconds minimum. For real-time applications, this is prohibitive. For batch processing tasks (overnight analysis, document processing), it is often acceptable.
The research paper "AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation" (Wu et al., 2023) reports significant improvements on coding tasks compared to single-agent baselines, particularly on tasks requiring verification (math proofs, code correctness). The verification benefit is real — but it requires the reviewer agent to be genuinely independent, using different prompting or even different models, not just a second instance of the same system.
Practical Guidance
Use AutoGen when verification matters. Tasks where you can define a clear correctness criterion — code that passes tests, calculations that can be checked, claims that can be fact-checked — benefit most from the generate-critique-revise loop.
Use different models for generator and reviewer. The most common mistake is using the same model configuration for both roles. A GPT-4o coder reviewed by a GPT-4o reviewer often results in the reviewer approving the same errors the coder made. Use different temperature settings at minimum; use different models where possible.
Set hard termination conditions. Always set MaxMessageTermination as a backstop. Without it, conversations can loop indefinitely if agents fail to converge. Ten to fifteen messages is usually sufficient for most tasks; if you need more than twenty turns to reach convergence, the task definition or agent configuration probably needs rethinking.
Log everything. AutoGen's conversation history is your primary debugging tool. Instrument your deployments to persist full conversation logs, indexed by task ID. When something goes wrong, the conversation transcript usually makes the failure point obvious.
AutoGen is the right choice when your task requires genuine iterative refinement through structured dialogue. For tasks with a single clear output, simpler frameworks will serve you better. For tasks where quality depends on multi-perspective deliberation — complex coding, research synthesis, technical analysis — AutoGen's conversational model delivers results that justify the overhead.
Explore more from Dr. Jyothi


