
When Cognition Labs announced Devin in March 2024, the narrative was maximalist: the first AI software engineer, capable of end-to-end software development. The demo showed Devin completing a freelance programming task on Upwork, setting up a development environment, writing and debugging code, deploying the result. It was impressive. It was also, in some ways, the beginning of a more nuanced conversation about what AI software engineering agents can actually do reliably.
Eighteen months later, the landscape has clarified considerably. Devin has real production users. SWE-agent, SWE-bench, OpenHands, Aider, and a dozen other tools have added texture to our understanding of where these systems work well and where they fail. The picture is genuinely exciting — and genuinely complex.
The SWE-bench Benchmark
To understand AI software engineers, you need to understand SWE-bench. It is the benchmark that defined the field.
SWE-bench (Princeton, 2024) consists of 2,294 real GitHub issues from popular Python repositories — Django, Flask, NumPy, SciPy, and others. For each issue, the benchmark includes the repository state before the fix, the issue description, and the test(s) that the fix must pass. The agent's task: write code that resolves the issue and passes the tests, given only the issue description and the codebase.
This is substantially harder than academic coding benchmarks. The issues are real bugs, not toy problems. The codebases are large (tens of thousands of lines), complex, and require understanding of framework-specific conventions. Many issues require modifying multiple files and understanding the interaction between components written months or years apart.
SWE-bench Lite reduces the set to 300 higher-quality issues. SWE-bench Verified (introduced in 2024) uses human-verified issues to remove ambiguous or under-specified problems from the evaluation. The Verified split is now the most meaningful benchmark.
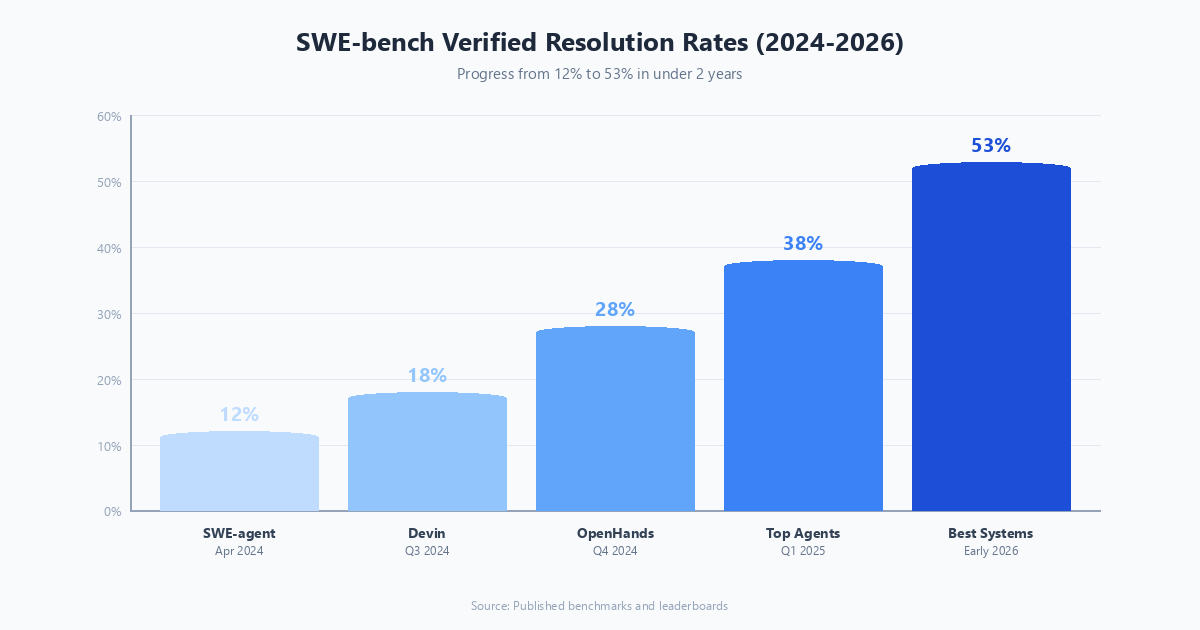
As of early 2026, top agents on SWE-bench Verified are resolving 50-55% of issues. That is remarkable progress from the 12% that early SWE-agent achieved in 2024. It is also a reminder that 45-50% failure rate on curated, well-specified real bugs is still a significant limitation for unmonitored production deployment.
SWE-agent: The Research System
SWE-agent (Yang et al., Princeton 2024) is the open-source research agent that established the SWE-bench baseline approach. Its key contribution was the Agent-Computer Interface (ACI) — a purpose-built command interface for LLMs interacting with code, rather than using raw bash.
The ACI insight: general-purpose terminal interfaces are poorly designed for LLM agents. They generate too much output, require precise command syntax the LLM may get wrong, and provide poor error feedback. SWE-agent's ACI wraps standard operations in LLM-friendly commands — searching within files, jumping to specific line numbers with surrounding context, scrolling through file contents, and editing a range of lines using a structured diff format — all with tighter, more informative feedback than a raw shell provides.
This interface substantially improves agent performance compared to raw bash by reducing the surface area of possible errors and making the feedback loop tighter. The lesson applies beyond SWE-agent: tool interface design is a significant performance lever for any agent system.
Devin: The Commercial System
Cognition's Devin targets a different user — software development teams looking for an agent that can handle complete development tasks, not just bug fixes. Devin has its own persistent development environment (browser, terminal, code editor), can read documentation, search the web, and work across long timeframes.
The independent evaluation by Cognition and others put Devin at roughly 13.86% on the original SWE-bench (full, unverified) in 2024. That number was widely misreported as disappointing given the marketing, but context matters: this was on unverified issues, many of which are ambiguous, using a single-attempt evaluation. On curated tasks with appropriate scaffolding, Devin's performance is substantially better.
More useful than benchmark comparisons is the class of tasks where Devin adds genuine value: setting up development environments from scratch, implementing features from specification documents, writing integration tests for existing APIs, and handling the kind of "junior developer" tasks that are tedious but straightforward. These are real use cases with real value — they just do not make for as dramatic a headline as "AI writes entire codebase."
OpenHands (formerly OpenDevin): The Open Alternative
OpenHands is the leading open-source alternative to Devin. It provides a sandboxed development environment and supports multiple backend models (Claude, GPT-4o, open-source models). The community around OpenHands has driven rapid development, and recent versions are competitive with commercial alternatives on SWE-bench.
What makes OpenHands particularly useful for research is the ability to run different models and observe how backend capability translates to agent performance. The answer, perhaps unsurprisingly, is that backend model quality is the dominant factor in agent performance — which is important for teams deciding how much to invest in framework sophistication versus model quality.
Aider: The Practical Tool
Aider takes a different approach from Devin and SWE-agent: it is designed for interactive use alongside a developer, not autonomous end-to-end task completion. You describe what you want in natural language, Aider generates the changes, shows you a diff, and only applies the change if you approve.
This human-in-the-loop design makes Aider more reliable in practice than fully autonomous agents, and many professional developers have integrated it into their daily workflow. Aider consistently achieves 50%+ on SWE-bench Verified with Claude Sonnet or GPT-4o backends — numbers that are competitive with fully autonomous systems, because the developer-in-the-loop catches errors before they propagate. You invoke it from the command line, point it at your repository, specify a model and whether to auto-commit changes, and then describe your requested change in plain English: for instance, adding input validation to a class to raise an error on invalid email formats.
The Real-World Gap
The most important thing I can tell you about AI software engineering agents is that SWE-bench scores overestimate real-world reliability in three consistent ways.
Task specification quality. SWE-bench issues are written by developers for developers. They contain relevant technical context, reference specific code locations, and include failing tests. Real-world feature requests and bug reports are often vague, missing context, or misattribute the root cause. Agent performance degrades significantly as specification quality drops.
Repository familiarity and scale. SWE-bench repositories are well-maintained, well-documented open-source projects with consistent coding conventions. Enterprise codebases often have years of accumulated technical debt, inconsistent patterns, missing documentation, and undocumented dependencies. Agent performance on these codebases is substantially lower.
Single-instance evaluation. SWE-bench evaluates single attempts on isolated issues. Production development involves ongoing work in shared repositories where changes interact, merge conflicts occur, and the codebase evolves while you are working. These dynamics are not captured in benchmark evaluation.
The Trajectory
Despite these caveats, the trajectory is clear and significant. In 18 months, top-line SWE-bench performance improved from roughly 12% to 50%+. The underlying techniques — better scaffolding, more capable models, multi-agent review loops, better file navigation — continue to improve.
The near-term prediction I am most confident in: AI software engineering agents will become standard development tools for specific, well-defined classes of tasks (writing tests, implementing CRUD operations from specifications, refactoring specific functions, updating dependencies) within the next 12 months. They will continue to struggle with architectural decisions, complex debugging across distributed systems, and tasks requiring deep institutional knowledge of a specific codebase.
The framing of "AI replaces software engineers" is wrong in both directions — it both overstates near-term capability and undersells the long-term transformation. The more useful frame is that software engineers who use AI agents effectively will dramatically outperform those who do not, because they will spend less time on implementation and more time on design, architecture, and judgment — which remain genuinely human domains for the foreseeable future.
Explore more from Dr. Jyothi


