
Live-SWE-agent: Can Coding Agents Actually Learn on the Job?
SWE-agent (NeurIPS 2024) established that LLM agents with well-designed agent-computer interfaces can solve real GitHub issues automatically. Since then, a small industry has emerged around coding agents: Devin, Copilot Workspace, Claude's computer use — all variations on the same theme of giving an LLM a shell and letting it fix bugs.
But here's the fundamental limitation: these agents run with a fixed policy. They apply the same strategies, the same tool-use patterns, the same debugging approaches to every task. They don't adapt based on what works and what doesn't during the current session.
Live-SWE-agent (arXiv: 2511.13646, Nov 2025) asks the uncomfortable question: what if the agent could update its own strategies on-the-fly as it works through a task? Not retraining — just in-context self-improvement, adapting its approach based on failed attempts within the same session.
The Problem: Static Agents in a Dynamic Problem Space
Software engineering tasks are uniquely heterogeneous. A bug in a Python async library requires a different debugging strategy than a performance regression in a C++ game engine. A React component architecture issue is solved differently than a database query optimization problem.
Current coding agents use a fixed set of strategies — shell commands, file navigation, test running, patch application — in patterns determined by training. When a strategy fails (the tests don't pass after the first patch attempt), the agent tries the same category of approaches again rather than fundamentally reconsidering its strategy.
flowchart TD
subgraph Static Agent - Current Approach
A[GitHub Issue] --> B[Apply Strategy 1]
B --> C{Tests Pass?}
C -->|No| D[Apply Strategy 2]
D --> E{Tests Pass?}
E -->|No| F[Apply Strategy 1 variant]
F --> G[Fail / Wrong fix]
end
subgraph Live-SWE-agent - Self-Evolving
H[GitHub Issue] --> I[Apply Strategy 1]
I --> J{Tests Pass?}
J -->|No| K[Analyze failure pattern]
K --> L[Update strategy hypothesis]
L --> M[Apply Updated Strategy]
M --> N{Tests Pass?}
N -->|Yes| O[Success + Record learning]
end
style G fill:#ef4444,color:#fff
style O fill:#059669,color:#fff
style K fill:#2563eb,color:#fff
style L fill:#7c3aed,color:#fff
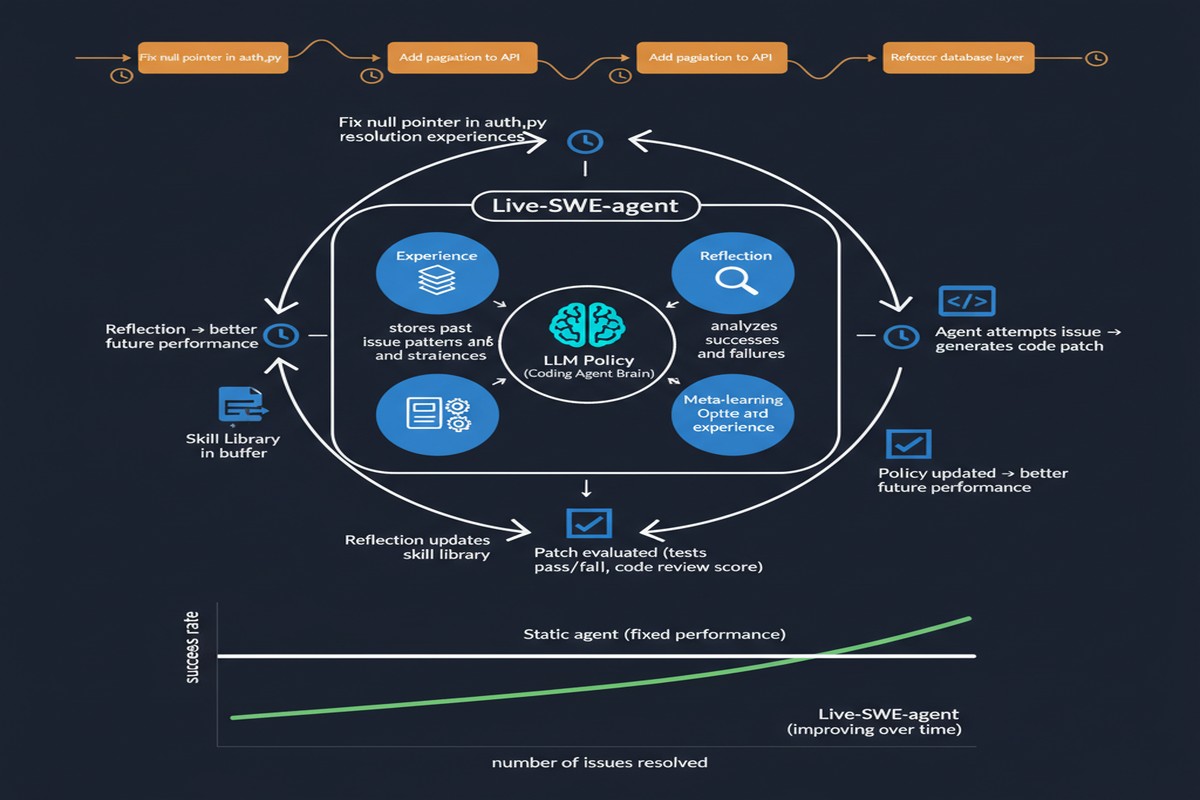
How Live-SWE-agent Self-Evolves
The system operates within a structured self-evolution loop:
Phase 1: Strategy Hypothesis Formation
Before attempting a fix, the agent generates explicit hypotheses about what the problem is and what strategies are likely to work. These hypotheses are stored in a structured "strategy scratchpad" — not just part of the raw context, but explicitly formatted reasoning about the approach.
Phase 2: Execution and Failure Analysis
When an attempt fails (tests don't pass, or the fix introduces new failures), rather than immediately trying the next strategy, the agent enters an explicit failure analysis phase. It asks:
- Which part of my strategy was wrong?
- Was the diagnosis correct but the implementation flawed?
- Was the diagnosis wrong entirely?
- What does this failure tell me about the codebase structure?
Phase 3: Strategy Update and Transfer
Based on the failure analysis, the agent updates its strategy scratchpad. This isn't just adding more context — it's explicitly revising hypotheses and strategy priorities. The updated strategies influence subsequent attempts within the same session.
Critically, Live-SWE-agent also maintains a cross-task strategy memory: patterns learned from failure analysis on one task inform strategy selection on subsequent tasks in the same session. If the agent discovers that a particular codebase uses unconventional import structures, this insight updates its file-finding strategies for all remaining tasks.
Results on SWE-Bench Verified
The paper evaluates on SWE-Bench Verified, comparing Live-SWE-agent against the base SWE-agent with the same underlying LLM:
Self-evolution within tasks (same GitHub issue, multiple attempts):
- Live-SWE-agent solves an additional 8-12% of issues that base SWE-agent fails on first attempt
- The improvement comes primarily from better failure analysis — the agent correctly identifies why its first approach failed rather than blindly retrying
Cross-task learning in session:
- Particularly strong improvement on repositories with similar structure (the agent builds a working model of the codebase's patterns)
- Less improvement on heterogeneous task batches where cross-task transfer is low
Compute overhead:
- The failure analysis and strategy update loops add approximately 30% more tokens per task
- Net efficiency (successful fixes per token) still improves due to fewer failed attempts
The Connection to Test-Time Compute
Live-SWE-agent is fundamentally a test-time compute scaling paper applied to software engineering. Rather than spending inference compute on forward passes through more LLM layers, it spends compute on structured self-reflection and strategy updating.
xychart-beta
title "Test-Time Compute vs. Fix Rate"
x-axis [1x, 2x, 3x, 4x]
y-axis "% Issues Resolved" 0 --> 70
line [42, 47, 49, 50]
line [42, 51, 57, 63]
Blue line: baseline best-of-N sampling. Orange line: Live-SWE-agent self-evolution. Self-evolution scales better.
The insight: structured self-reflection is a more efficient use of additional compute than naive sampling. When you use more compute for best-of-N, you're generating diverse random attempts from the same strategy. When you use more compute for self-evolution, you're systematically improving the strategy itself.
Why This Matters for Agentic Engineering
The implications extend beyond SWE-bench numbers. If coding agents can genuinely improve their strategies within a session, the economic model for agent deployment changes:
Longer sessions become more valuable: An agent that learns from its mistakes becomes more effective over the course of a multi-hour debugging session. The current model where agents are reset between tasks discards all this learning.
Codebase-specific adaptation: An agent that works in a codebase for a week should be dramatically better at week's end than day's start. Self-evolution within sessions is the prerequisite for this kind of deployment-time adaptation.
Reduced human intervention: If agents can identify and correct their own strategy errors, the frequency of human correction drops — reducing the bottleneck in human-agent collaborative workflows.
My Take
Live-SWE-agent is a significant step toward agents that genuinely improve through experience rather than just applying a fixed policy. The failure analysis loop is the key insight — making the agent explicitly reason about why attempts fail, not just what failed.
I'm excited about the cross-task strategy memory, but want to see it scaled. The current evaluation is relatively bounded — same session, related tasks. The real test is: can agents maintain and update useful strategy knowledge across sessions, across codebases, over weeks of deployment? That requires persistent memory systems beyond what current architectures support.
The 30% compute overhead is acceptable given the fix rate improvement, but it needs to be managed carefully in production. Not every failure warrants a deep self-reflection loop — simple, well-understood failures should be handled by lighter-weight error recovery.
The future direction I want to see: agents that externalize their strategy updates as documentation — creating and updating a "working notes" document that other agents (and humans) can read. This makes the self-improvement process transparent and auditable, rather than locked inside a black-box context window.
Self-evolving agents. We're getting there.
Paper: "Live-SWE-agent: Can Software Engineering Agents Self-Evolve on the Fly?", arXiv: 2511.13646, Nov 2025.


