Paper/Report: The Llama 4 Herd: The Beginning of a New Era of Natively Multimodal AI Innovation Published: Meta AI Blog + technical report, April 2025 Models: Llama 4 Scout (17B active/16 experts), Llama 4 Maverick (17B active/128 experts), Llama 4 Behemoth (288B active/16 experts, ~2T total)
Meta's Llama releases have followed a pattern: iterate on the dense transformer architecture, increase data quality and quantity, open the weights. Llama 1, 2, 3, 3.1 — progressively better, architecturally conservative, and reliably competitive with the best proprietary models at their scale.
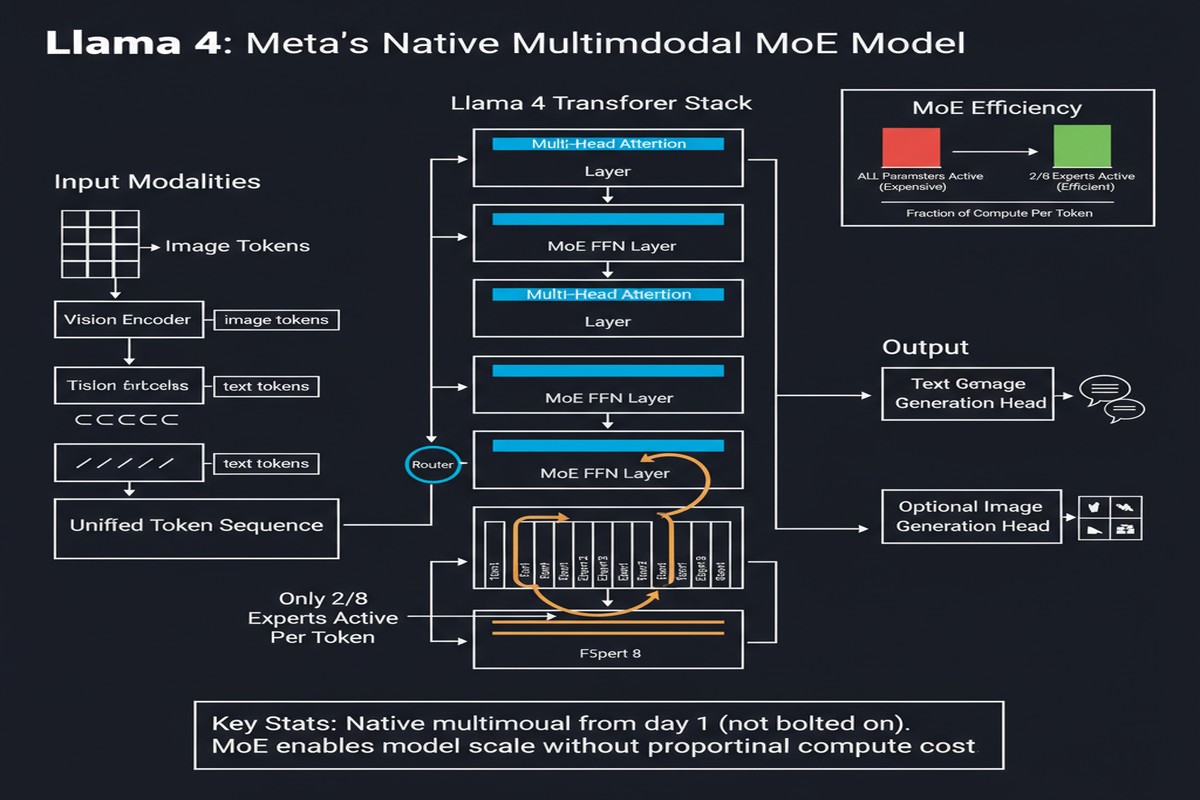
Llama 4 breaks the pattern. It is the first Llama family to use Mixture-of-Experts architecture. The first to be natively multimodal — trained on text, images, and video from the ground up, not patched in afterward. And with Behemoth's nearly 2 trillion total parameters, it is by far the largest model Meta has released.
The implications are significant, and not all of them are obvious.
The Architecture Shift: Why MoE Now?
Dense transformers scale predictably but expensively. Every token activates every parameter. At 70B parameters, inference is already compute-intensive; at 400B (Llama 3.1's largest variant), it requires multi-GPU serving for most applications.
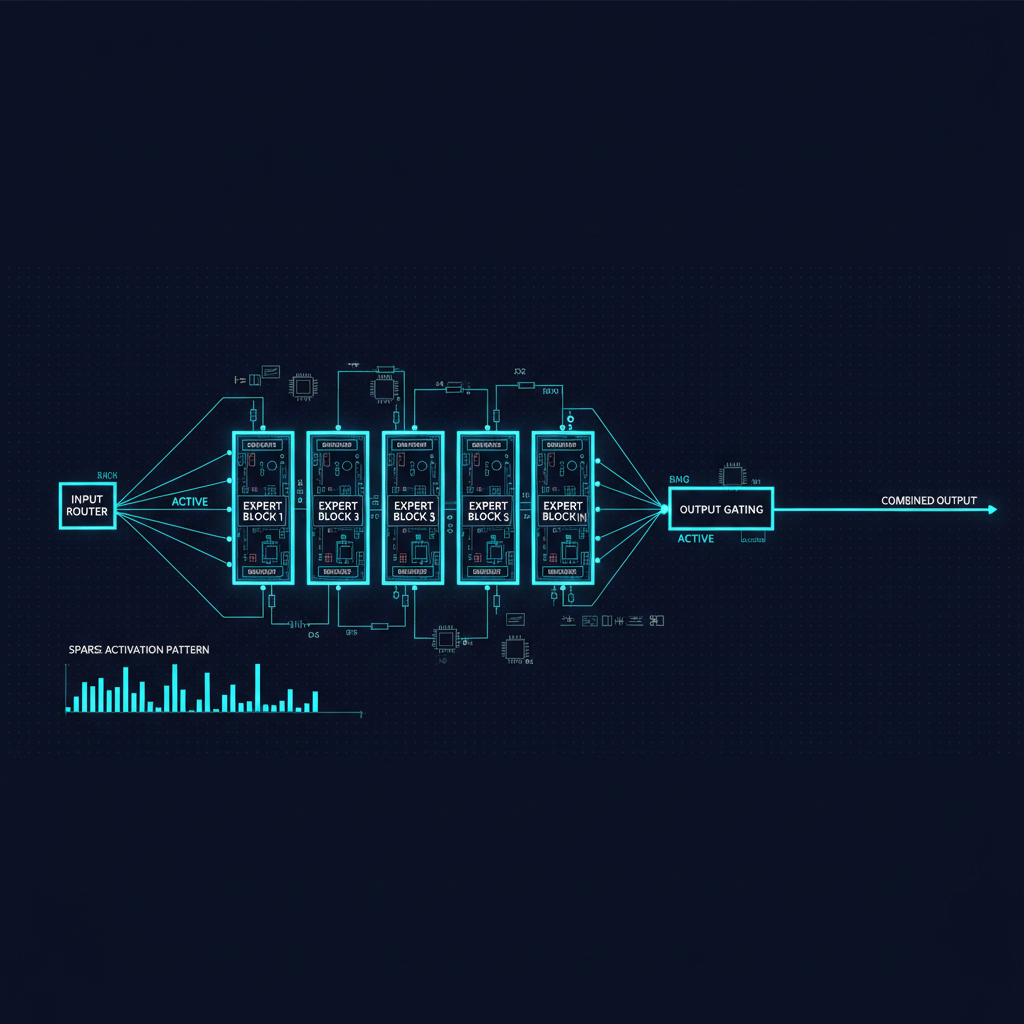
Mixture-of-Experts changes the scaling equation. In an MoE layer, each token is routed to a small subset of "expert" feedforward networks rather than to a single dense FFN. The total parameters are large, but the active parameters per token remain manageable.
Llama 4 Maverick has 17B active parameters per token with 128 experts, for a total of roughly 400B parameters. When you're serving it, each token only activates 17B parameters — comparable in compute to a Llama-3-13B, but with access to knowledge stored across 400B parameters. That's the MoE value proposition: near-small-model inference cost, near-large-model capacity.
flowchart TD
A[Input Token] --> B[Router: Which experts?]
B --> C{Token sent to...}
C --> D[Shared Expert: always active]
C --> E[Routed Expert #1]
C --> F[Expert #7]
C --> G["Expert #45 (128 total, 1 chosen)"]
D --> H[Aggregate outputs]
E --> H
G --> H
H --> I[Next layer]
style D fill:#4a9eff,color:#fff
note1["17B active params per token\n~400B total params\nLlama 4 Maverick configuration"] --> B
Alternating dense and MoE layers (rather than pure MoE throughout) provides additional stability. The dense layers maintain direct representational flow; the MoE layers handle the specialized processing with expert routing.
Native Multimodality: What It Actually Means
"Natively multimodal" is a loaded phrase that can mean anything from "we added a vision encoder after the fact" to "the model was trained on text, images, and video from the first token." Llama 4 claims the latter.
The distinction matters. Models that bolt on vision capabilities after language pretraining (like early GPT-4V implementations) have a fundamental awkwardness: the language model's representations were shaped entirely by text, and vision is integrated through adapters that translate image features into the language model's token space. This works, but the integration is imperfect.
A model pre-trained from the start on text and images develops joint representations that treat visual and textual information as peers. Concepts that have both visual and textual manifestations — a mathematical diagram, a chart, code in a screenshot — are represented more coherently in a natively multimodal model.
Meta trained the Llama 4 herd on over 30 trillion tokens from diverse datasets that include text, images, and video. The training data volume alone is a significant investment.
The Behemoth Problem
Llama 4 Behemoth deserves special mention because it's in a category by itself: 288B active parameters, nearly 2 trillion total parameters, 16 experts. Meta describes it as "one of the smartest LLMs in the world."
Meta did not open-weight Behemoth. It is used internally as a teacher model for distilling capabilities into Scout and Maverick. The distillation approach — using Behemoth's outputs to train smaller models — follows a well-established knowledge distillation paradigm, but at unprecedented scale.
The Maverick distillation from Behemoth is described as using a "novel distillation loss function that dynamically weights soft and hard targets through training." This adaptive weighting is important: early in training, soft targets (the full probability distribution from the teacher) are most informative, while late in training, hard targets (the teacher's top choices) matter more. The dynamic weighting captures this curriculum.
FP8 Training at Scale
All Llama 4 models use FP8 (8-bit floating point) precision training. This is significant: FP8 training was considered unstable at scale as recently as 2023. By 2025, hardware support (H100 with FP8 tensor cores, H200) and training stability techniques have made FP8 practical, enabling roughly 2x compute efficiency compared to BF16 training.
FP8 training at the scale of Behemoth means Meta ran trillion-parameter training at costs that would have been impossible two years ago. The hardware scaling story and the precision scaling story are intertwined.
Why This Matters
1. The open-weight frontier has reached trillion-parameter scale. Behemoth is not fully open — but Scout and Maverick are, with total parameters approaching 400B for Maverick. Open weights at that parameter scale, with MoE inference efficiency, means self-hosted AI deployments can now access capabilities that were proprietary-only as recently as GPT-4.
2. Native multimodality will become the baseline expectation. The separation between "vision models" and "language models" is a historical artifact of how models were built, not a natural architectural boundary. Llama 4 demonstrates that training natively multimodal at scale is viable. Future model releases that are text-only will increasingly be seen as capability-limited.
3. MoE is no longer experimental in open weights. Before Llama 4, the most prominent open MoE was Mixtral (Mistral AI, December 2023). Llama 4 brings MoE to Meta's scale and production maturity. Every major open-weight lab will now face pressure to evaluate MoE architectures.
4. Knowledge distillation from very large teachers changes the model development playbook. Behemoth as a teacher model is a bet that trillion-parameter training produces capabilities that can be efficiently transferred to smaller models. If this holds at scale, the competitive moat of very large models shrinks: labs that can't afford to serve Behemoth can still benefit from its knowledge through distillation.
5. The 10M context window is architecturally real. Llama 4 Scout supports 10M token context — not as a post-training patch but as a designed architectural capability. Combined with the long-context benchmarking work (see my post on the "Beyond a Million Tokens" paper), this sets a new floor for what "serious long-context support" means.
My Take
I want to push back on two aspects of the Llama 4 story.
First: the context window claim. 10M token context support is architecturally real. Whether it is practically useful is a different question. As I've discussed in detail in my piece on the "Beyond a Million Tokens" benchmark, current models including Llama 4 show significant degradation on hard long-context tasks past 1M tokens. Marketing 10M context as "transforming how we process information" is premature until the benchmark results at that scale are compelling.
Second: the open-weight framing. Meta open-weights Scout and Maverick with usage restrictions for large commercial deployments (companies above a certain scale require a separate license). This is not fully open — it is "open enough for most use cases." I understand the commercial logic but wish the messaging were clearer. Not all openness is equal.
The genuinely impressive achievements: FP8 training at Behemoth scale, native multimodality from pretraining, and the distillation pipeline that enables Maverick to punch far above its weight class. The 128-expert MoE in Maverick is architecturally elegant — the router granularity means the model can develop highly specialized expert pathways without sacrificing generalization.
Llama 4 matters because it establishes a new baseline for what open-weight models should do: multimodal, MoE-efficient, long-context capable, and trained at data scales competitive with the best proprietary models. The teams still using dense, unimodal models without this kind of pre-training investment are falling behind a rising bar.

Technical report: ai.meta.com/blog/llama-4-multimodal-intelligence