
Paper: Qwen3 Technical Report arXiv: 2505.09388 | May 2025 Authors: Qwen Team, Alibaba Group
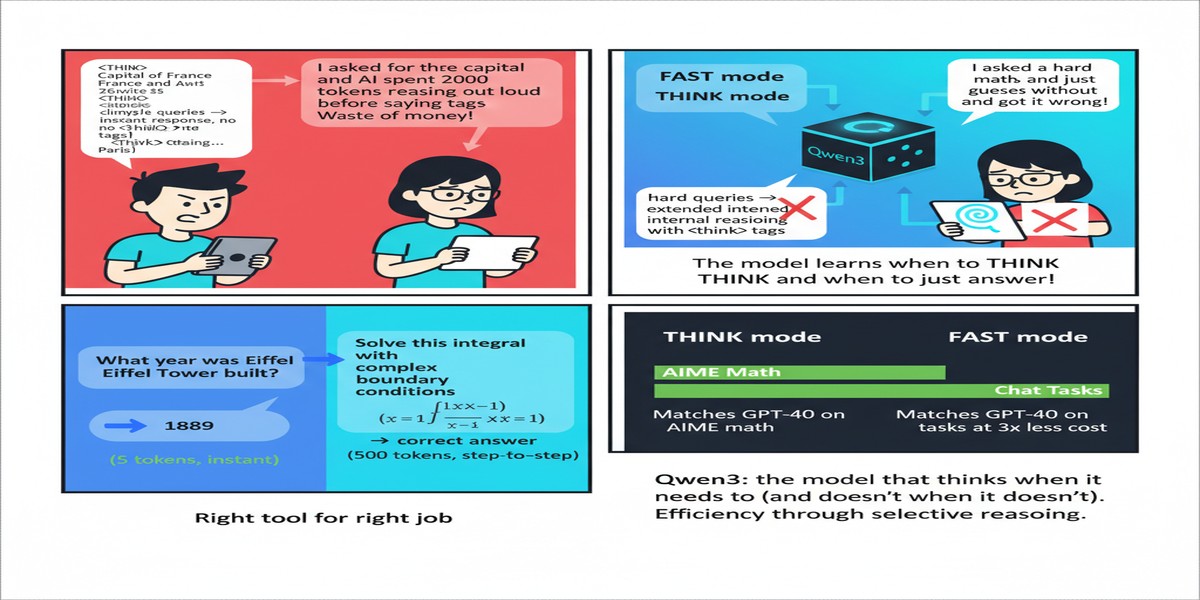
The reasoning model proliferation of 2025 created a practical problem that nobody wanted to talk about: you now need two models for every application. Use DeepSeek-R1 (or o1, or QwQ) for hard problems that require extended thinking. Use a fast chat model (GPT-4o, Qwen2.5-Instruct, Claude Haiku) for everything else. The routing layer between them — deciding which model to invoke for which query — became an engineering problem in itself.
Qwen3 solves this by making it unnecessary. It integrates thinking and non-thinking modes into a single model, switchable via a chat template flag or automatic mode detection. For hard math problems: thinks. For simple questions: responds directly. One model, two modes, correct behavior for each.
This sounds like a small ergonomic improvement. It is, in practice, a significant architectural and training achievement — and the results justify the approach.
The Core Innovation: Unified Thinking and Non-Thinking
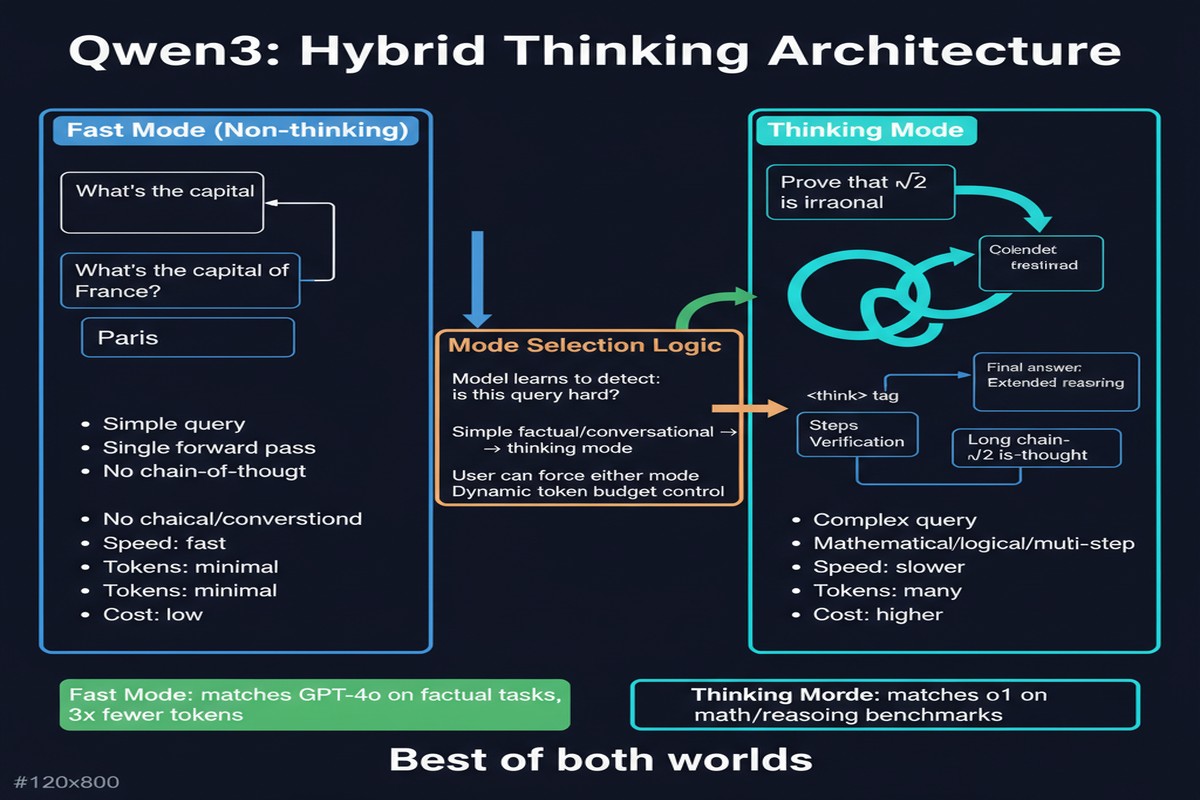
Prior reasoning models (o1, DeepSeek-R1, QwQ-32B) are trained to always produce an extended reasoning chain before answering. This is appropriate for hard problems but wasteful and sometimes worse for simple queries. A model trained to "think about everything" generates unnecessary tokens on easy questions, increasing latency and cost without improving quality.
Standard chat models (GPT-4o, Qwen2.5-Instruct) are trained to respond directly. They perform fine on routine tasks but struggle with hard reasoning because they lack the extended self-reflection training.
Qwen3 trains both modes jointly:
stateDiagram-v2
[*] --> QueryReceived
QueryReceived --> ModeDetection
ModeDetection --> ThinkingMode: Complex/Hard query
ModeDetection --> NonThinkingMode: Simple/Routine query
ModeDetection --> UserOverride: Explicit /think or /nothink flag
ThinkingMode --> ExtendedReasoning: Generate think tokens
ExtendedReasoning --> FinalAnswer: Collapse to answer
FinalAnswer --> [*]
NonThinkingMode --> DirectResponse: Respond immediately
DirectResponse --> [*]
UserOverride --> ThinkingMode: /think flag
UserOverride --> NonThinkingMode: /nothink flag
The unified training involves multi-stage instruction tuning where the model sees both thinking-trace examples and direct-response examples, with mode indicators in the training data. The result is a model that has internalized when extended reasoning adds value versus when it's overhead.
The user-facing API exposes this as:
enable_thinking=True: forces thinking mode (reasoning trace visible)enable_thinking=False: forces non-thinking mode (direct response)- Default: automatic mode detection based on query complexity
The Scale: 36 Trillion Tokens, 119 Languages
Qwen3 pre-trains on 36 trillion tokens — double Qwen2.5's 18T and the largest publicly disclosed pre-training dataset at the time of release. The multilingual scope is also ambitious: 119 languages and dialects, with particular emphasis on underrepresented languages in the Qwen2.5 corpus.
The data quality improvements extend what Qwen2.5 did: further synthetic data generation for reasoning traces, additional STEM content, and expanded code coverage across more programming languages and paradigms.
The architectural options span dense and MoE:
- Dense models: 0.6B, 1.7B, 4B, 8B, 14B, 32B (for edge deployment to server-class)
- MoE models: 30B active/235B total, 3B active/22B total (for maximum efficiency)
The 235B MoE model is the flagship, with 30B active parameters providing competitive inference costs with much larger parameter coverage.
Performance: The Benchmark Story
Qwen3 achieves state-of-the-art results across a range of benchmarks in both thinking and non-thinking modes:
In thinking mode, Qwen3-235B-A22B (the large MoE in non-thinking mode — I'll clarify this below) is competitive with DeepSeek-R1-0528 on math benchmarks and outperforms many models that are significantly larger in active parameter count.
In non-thinking mode, Qwen3 models are competitive with GPT-4o class models on standard chat benchmarks — without the reasoning overhead.
The 32B dense model is particularly interesting: in thinking mode, it matches or exceeds the performance of models with far larger parameter counts on hard reasoning tasks. Combined with Qwen2.5's lesson that data quality matters more than model size, this suggests the Qwen training methodology has figured out something about dense-model training efficiency that the field hasn't fully internalized.
The Multilingual Story
119 languages is not just a feature checkbox. Qwen3 shows meaningful performance improvements on non-English reasoning tasks compared to Qwen2.5. This matters because most reasoning model research evaluates on English benchmarks, and the assumption that "reasoning scales to other languages" deserves empirical validation.
The evidence is that multilingual training at scale helps. Qwen3's performance on mathematical and scientific reasoning in non-English languages exceeds what you'd expect from a model fine-tuned from an English-primary base. The hypothesis is that multilingual training provides additional algebraic / formal reasoning signal from diverse language structures.
For anyone building AI applications for markets where English is not the primary language — which includes most of Asia, Africa, and Latin America — Qwen3's multilingual investment is directly relevant.
Why This Matters
1. The unified model architecture is the right UX. Forcing users to choose between "reasoning mode" and "fast mode" at deployment time creates unnecessary complexity. Qwen3's dynamic mode switching is how reasoning capability should work: invisible overhead for easy queries, automatic engagement for hard ones.
2. 36T tokens is setting a new data baseline. The progression from 7T (Qwen2) to 18T (Qwen2.5) to 36T (Qwen3) shows Alibaba's data scaling investment. The continued improvement suggests the field has not hit diminishing returns from data quality and diversity.
3. Apache 2.0 licensing is significant. All Qwen3 models are fully open under Apache 2.0 — no Meta-style commercial restrictions, no usage limits beyond the license itself. For enterprises building on open-weight models, this removes a meaningful legal risk from the stack.
4. The small model story is compelling. Qwen3-8B and Qwen3-4B, in thinking mode, are capable of handling genuinely hard reasoning tasks. This makes on-device reasoning — running on consumer GPUs, edge servers, or even powerful mobile devices — practically viable for the first time.
5. Multilingual reasoning at scale validates the approach. If you're building products for non-English markets, Qwen3 is currently the strongest open-weight option for reasoning-intensive tasks in diverse languages.
My Take
Qwen3 is, in my view, the most well-rounded open-weight model release of 2025. It doesn't win on any single metric, but the combination of qualities — unified thinking/non-thinking, 36T token pre-training, 119-language coverage, Apache 2.0 licensing, and a model family spanning 0.6B to 235B — makes it the most practically useful foundation for a wide range of applications.
The dynamic mode switching is the feature I find most significant for production engineering. The cost of always running in thinking mode for simple queries is substantial — extended reasoning on a "what's the capital of France?" question wastes tokens, latency, and money. Being able to deploy a single model that adapts its compute expenditure to query complexity is genuinely valuable.
I'm skeptical of the largest MoE variant (235B total parameters) for most deployment scenarios. Serving a 235B model requires meaningful GPU infrastructure, and for most use cases, Qwen3-32B in thinking mode provides excellent quality at a fraction of the cost. The 235B is a benchmark number; the 32B is what most teams will actually deploy.
My advice: if you are evaluating base models for fine-tuning or API-level deployment in mid-2025 through 2026, Qwen3-32B is one of the first models to test. The thinking mode quality, combined with the efficient non-thinking mode for routine queries, makes it architecturally cleaner than running two separate models — and cleaner architecture produces cleaner engineering decisions downstream.
Alibaba continues to execute at the frontier of open-weight model development. That should be neither comfortable for Western labs nor surprising at this point.
arXiv:2505.09388 — read the full paper at arxiv.org/abs/2505.09388


