
Model Merging During Pretraining: A Free Lunch That Actually Exists
Free lunches don't exist in machine learning. Except when they do.
"Model Merging in Pre-training of Large Language Models" (arXiv: 2505.12082, May 2025) reports that merging intermediate checkpoints during pretraining produces models that are meaningfully better than the final checkpoint at the same total compute budget. No additional training. No additional data. Just smarter use of the checkpoints you were already saving.
This is distinct from post-training model merging (which I've written about separately and which has mixed results on LLMs). Checkpoint merging during pretraining operates in a different regime — and works.
The Setup: What Are We Merging?
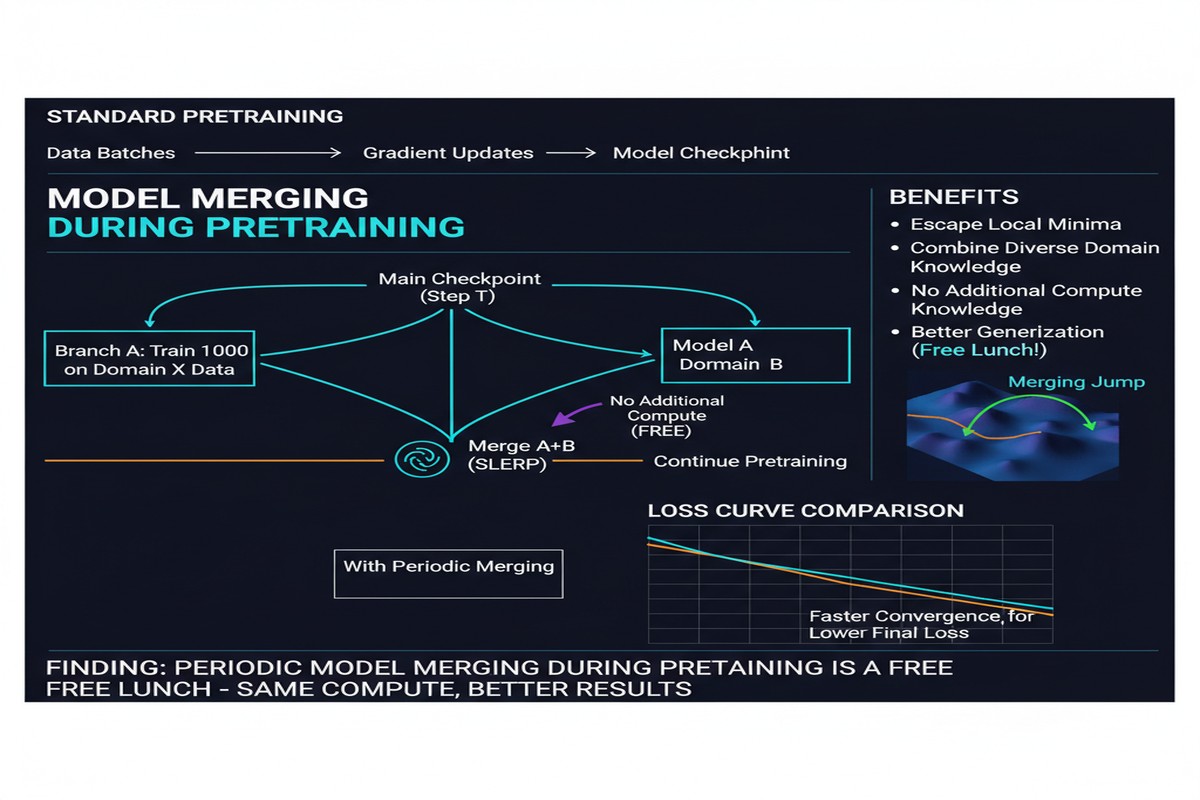
During standard LLM pretraining, practitioners routinely save checkpoints every N steps. This is standard practice for fault tolerance: if training crashes at step 100K, you can resume from step 99K rather than starting over.
Most of the time, these intermediate checkpoints are discarded after training completes. The final checkpoint is the model; the intermediate ones are scaffolding.
The paper asks: what if you didn't discard them? What if you averaged intermediate checkpoints together at the end of pretraining?
flowchart LR
subgraph Standard Pretraining
A[Step 0] --> B[Step 50K] --> C[Step 100K] --> D[Step 150K] --> E[Final Model]
B -.-> |discarded| X1[X]
C -.-> |discarded| X2[X]
D -.-> |discarded| X3[X]
end
subgraph Checkpoint Merging
F[Step 0] --> G[Step 50K] --> H[Step 100K] --> I[Step 150K] --> J[Final Step]
G --> M[Merge]
H --> M
I --> M
J --> M
M --> K[Merged Model - Better!]
end
style E fill:#d97706,color:#fff
style K fill:#059669,color:#fff
Why Would This Work?
The intuition comes from optimization landscape geometry. Neural network training follows a loss gradient through parameter space. The optimization trajectory isn't a straight line — it curves, zigzags through valleys and around local obstacles. The final checkpoint sits wherever the optimizer stopped: often a good spot, but not necessarily the best achievable spot in its neighborhood.
Averaging intermediate checkpoints is a form of stochastic weight averaging (SWA) — a technique with strong theoretical foundations. SWA has been shown to find flatter, broader loss minima than standard SGD training. Broad minima generalize better than sharp minima.
For LLMs with constant learning rates (no learning rate decay), checkpoint merging is particularly effective. With constant LR, the optimizer keeps moving through parameter space rather than converging to a point — the trajectory explores a region around the loss minimum. Averaging over this trajectory is mathematically equivalent to moving to the center of the explored region, which tends to be flatter and better-generalizing.
Results Across Model Architectures
The paper evaluates across an impressive range:
Dense models: Improvements consistent from 100M to 100B+ parameter models. The improvement is approximately 1-3% on most benchmarks, with larger gains on tasks that reward generalization over memorization.
Mixture-of-Experts (MoE) models: Particularly strong results here. MoE models have sparse routing — only a subset of experts activate for each token. Checkpoint merging helps by averaging expert weights across checkpoints where different experts were activated, effectively improving coverage. The improvement on MoE models is 2-5% on average, larger than dense model gains.
xychart-beta
title "Performance Improvement from Checkpoint Merging"
x-axis ["Dense 100M", "Dense 1B", "Dense 7B", "Dense 70B", "MoE 8x7B"]
y-axis "Relative Improvement %" 0 --> 6
bar [1.2, 1.8, 2.1, 1.9, 4.3]
Approximate figures based on paper's reported results across benchmarks
The Practical Recipe
The paper provides a clear recipe for practitioners:
1. Train with constant learning rate. Don't use learning rate decay that converges to zero. A constant or cosine schedule without decay keeps the trajectory in a region rather than collapsing to a point.
2. Save checkpoints frequently in the final ~20-30% of training. The checkpoints most useful for merging are those in the later stages when the model is in a good region of parameter space but still exploring.
3. Merge the final 3-8 checkpoints. Simple averaging. More exotic merging methods (from the post-training merging literature) don't provide additional benefit here and can hurt.
4. Evaluate the merged model. In all experiments, the merged model outperforms any single checkpoint including the final one.
The compute overhead is negligible — merging checkpoints is just a weighted average of parameter tensors, taking seconds even for large models.
How This Differs From Post-Training Merging
It's important not to confuse this with the post-training model merging that the field has been experimenting with (and which mostly fails for LLMs in rigorous evaluation). The differences are fundamental:
| Checkpoint Merging During Pretraining | Post-Training Model Merging | |
|---|---|---|
| What's merged | Same model at different training steps | Different models fine-tuned for different tasks |
| Weight delta structure | Gradual, correlated changes | Task-specific, potentially conflicting deltas |
| Why it works | SWA / broad minima theory | Capability combination (often doesn't work) |
| Reliability | Consistent improvement | Unreliable for LLMs |
Post-training merging tries to combine what models know. Checkpoint merging during pretraining improves how well the model knows what it knows. Different problem, different mechanism, different reliability.
Implications for Training Pipelines
If you're training a large model from scratch, or fine-tuning from a base model, this technique is essentially free improvement:
Infrastructure is already there: You're already saving checkpoints. You just need to average the last few before releasing the model.
No quality-speed tradeoff: Unlike quantization or pruning, checkpoint merging doesn't compress the model. You get a full-precision, full-parameter model that's simply better trained.
Works for fine-tuning too: The paper includes experiments on domain-specific fine-tuning where checkpoint merging similarly improves the quality of the fine-tuned model.
Why This Matters
LLM training is expensive. The ability to extract more quality from the same training run, using checkpoints that would otherwise be discarded, is directly economically valuable.
More philosophically: this result says something interesting about the loss landscape. The fact that averaging trajectories reliably improves over any single point on the trajectory suggests that pretraining convergence is not to a single optimal point but to a region — and the interior of that region is better than its edges.
This has implications for how we think about "training to convergence." Perhaps final-checkpoint performance is not the right evaluation target. The community evaluates at final checkpoints by convention, but checkpoint-merged models would consistently outscore the final checkpoint. Are our benchmark comparisons actually comparing the best achievable models?
My Take
This is one of those "obvious in hindsight" papers that makes me wonder why the community wasn't doing this already. SWA has been known to help for smaller models. Extending it to LLM pretraining is natural, but somehow it took until 2025 for a systematic large-scale study.
The MoE result is the most interesting. MoE's expert routing creates a form of sparse specialization — individual experts become specialized during training. Averaging over checkpoints where routing decisions differed could help prevent over-specialization and improve expert coverage. Understanding this mechanism better could lead to MoE training improvements beyond simple checkpoint merging.
My recommendation: if you're training or fine-tuning LLMs, add checkpoint merging to your standard pipeline. It's not sexy, it's not a new architecture — it's just smart use of work you were already doing. That's the best kind of improvement.

Paper: "Model Merging in Pre-training of Large Language Models", arXiv: 2505.12082, May 2025.


