Mix Data or Merge Models? The New Benchmark for Aligning Helpful, Harmless, and Honest LLMs
Alignment is expensive. Getting an LLM to be simultaneously helpful (answers questions usefully), harmless (refuses dangerous requests), and honest (doesn't fabricate) requires carefully curated training data, complex reward model training, and iterative RLHF or DPO runs. The three objectives frequently conflict with each other: being maximally helpful sometimes means providing information that's also harmful; being maximally safe sometimes means refusing legitimate requests.
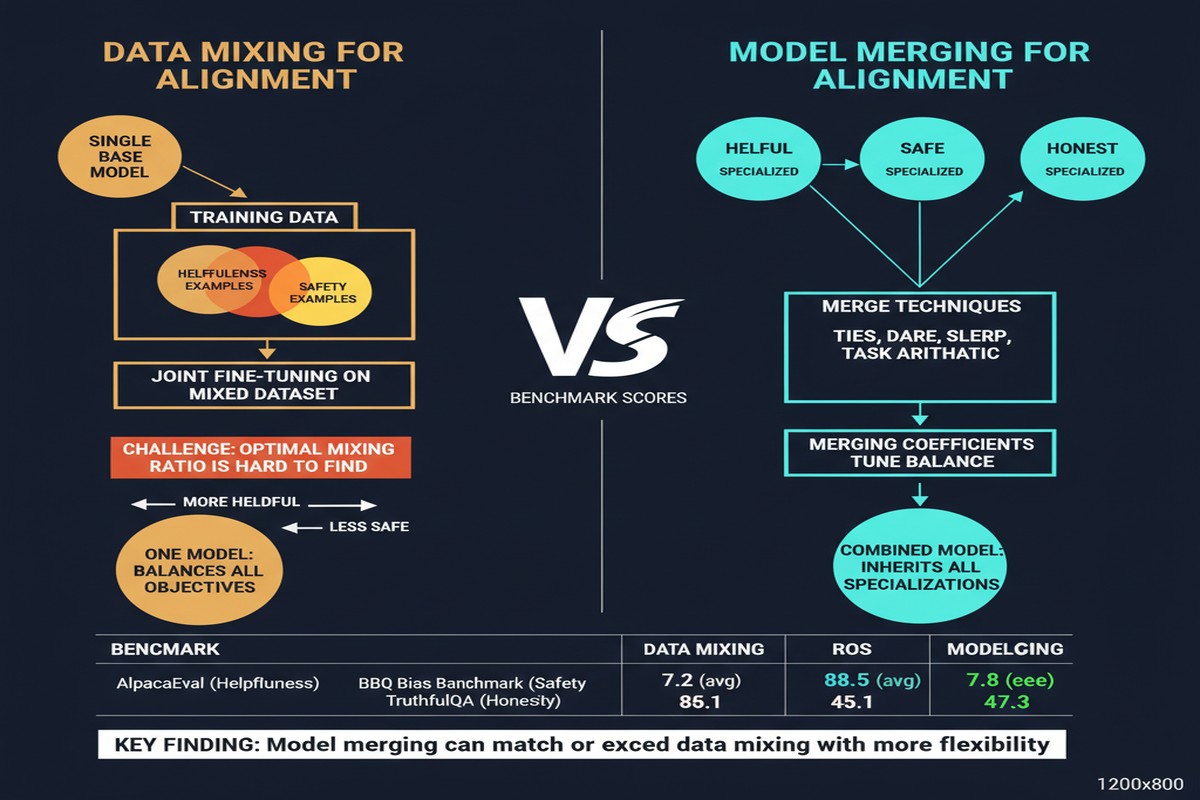
The dominant approach to handling this conflict is data mixing: combine data across all three objectives during training and hope the model learns a good trade-off. An alternative approach has been gaining traction: model merging, where you train separate models optimized for each objective and merge them at deployment time.
"Mix Data or Merge Models? Balancing the Helpfulness, Honesty, and Harmlessness of Large Language Model via Model Merging" (arXiv: 2502.06876, Feb 2025) is the first rigorous benchmark comparing these approaches systematically — and the results challenge the field's default assumptions.
The Alignment Trilemma
The H3 (Helpful, Harmless, Honest) framework, introduced by Anthropic's Constitutional AI work, frames alignment as a multi-objective optimization problem. In practice:
graph TD
H[Helpful] <-->|tension| S[Harmless]
H <-->|tension| O[Honest]
S <-->|tension| O
H -->|maximize| Q[Query answering quality]
S -->|maximize| R[Refusal of dangerous content]
O -->|maximize| A[Accuracy, no hallucination]
style H fill:#2563eb,color:#fff
style S fill:#059669,color:#fff
style O fill:#7c3aed,color:#fff
Helpful vs. Harmless: The most capable, most helpful models are also the most capable at being misused. Reducing harmful outputs often requires reducing helpful ones.
Helpful vs. Honest: The most fluent, engaging responses are not always the most accurate ones. Overly confident language (which users prefer) often involves implicit overclaiming.
Harmless vs. Honest: Calibrated uncertainty acknowledgment ("I don't know") is honest but can be unhelpful. Conversely, being honest about capabilities may include information that enables harm.
Current models navigate this trilemma through data mixing — the training mixture encodes an implicit trade-off. But the trade-off is invisible, non-adjustable, and fixed at training time.
The Comparison Framework
The paper creates a systematic benchmark covering:
- 5 base LLMs of different sizes and architectures
- Data mixing configurations: varying ratios of helpfulness, safety, and honesty data
- Model merging configurations: training separate H, S, and O models then merging with Task Arithmetic
- 15+ evaluation benchmarks covering each dimension plus combined performance
The evaluation measures not just average performance but the Pareto frontier — the set of configurations where you can't improve on one dimension without degrading another. Better alignment methods push the Pareto frontier outward.
Key Findings
Finding 1: Model Merging Is Competitive for Low Compute Budgets
When you have a limited fine-tuning compute budget, merging separately-trained models for each objective often achieves better H3 balance than data mixing. The reason: data mixing requires careful ratio selection (the wrong mixture hurts all objectives), while model merging separates the optimization problems entirely.
%%{init: {'quadrantChart': {'chartWidth': 600, 'chartHeight': 500, 'pointRadius': 5, 'pointLabelFontSize': 13, 'quadrantLabelFontSize': 14}}}%%
quadrantChart
title H vs S - Data Mixing vs Model Merging
x-axis Low Helpfulness --> High Helpfulness
y-axis Low Harmlessness --> High Harmlessness
quadrant-1 Ideal
quadrant-2 Safe but Useless
quadrant-3 Both Poor
quadrant-4 Helpful but Unsafe
Mix 30/70: [0.58, 0.90]
Mix 50/50: [0.70, 0.76]
Mix 70/30: [0.84, 0.60]
Merge TA: [0.77, 0.83]
Merge Weighted: [0.85, 0.88]
Approximate positioning based on paper's findings
Data mixing forces a single point on the H-S tradeoff curve at training time. Model merging moves the entire curve outward — achieving combinations of helpfulness and harmlessness that data mixing couldn't reach at the same compute budget.
Finding 2: The Honest Dimension Is Hardest to Align Through Mixing
Of the three H3 dimensions, honesty degrades most under data mixing. Honesty training requires specific examples of calibrated uncertainty expression, factual correction, and explicit acknowledgment of limitations — behaviors that conflict with the confident, fluent output style that helpfulness training reinforces.
Model merging handles this better because the honesty-optimized model develops genuine calibration during isolated training, and this calibration is preserved (rather than averaged away) through Task Arithmetic merging.
Finding 3: Merge Ratios Can Be Adjusted at Deployment Time
Perhaps the most practically interesting finding: model merging enables runtime adjustment of the alignment trade-off. By varying the coefficients in the Task Arithmetic merge (how much weight each component model gets), you can:
- Increase harmlessness weight for deployment in sensitive contexts (children's apps, healthcare)
- Increase helpfulness weight for deployment to expert users who need maximal capability
- Adjust honesty weight based on domain requirements
This is impossible with data mixing — the trade-off is baked in at training time. Model merging externalizes the trade-off to deployment-time configuration.
What Doesn't Work
The paper is honest about limitations:
High-compute data mixing beats everything: When training compute is abundant (enough to carefully craft optimal data mixtures and run extensive ablations), data mixing with the right ratios achieves better results than model merging. The problem is finding those ratios — it requires expensive grid search.
Merging only works with compatible base models: The separate H, S, O models must be fine-tuned from the same base model for merging to work. Cross-model merging (e.g., merging an RLHF-trained model from one base with a DPO-trained model from another) fails reliably.
Long-tail failures: Merged models have higher variance on edge cases than data-mixed models trained with explicit coverage of edge cases. Safety failures on unusual inputs are more likely with merged models.
Deployment Implications
The runtime adjustability finding has real product implications. A single set of merged component models could serve:
- A standard consumer-facing API (balanced H/S/O)
- An enterprise API with high safety requirements (upweighted S)
- A research API with emphasis on capability (upweighted H)
- A citation-required API for academic use (upweighted O)
This is cheaper than maintaining four separately fine-tuned model variants and provides a principled mechanism for adjusting the trade-off rather than arbitrary per-use-case fine-tuning.
My Take
This paper fills an important gap. The field has debated data mixing vs. model merging anecdotally for years. Establishing a rigorous benchmark for the H3 alignment problem specifically is valuable.
The runtime adjustability result is the most practically interesting finding. The ability to move along the alignment Pareto frontier at deployment time — without retraining — is a significant capability for AI product teams. It could enable safer experimentation with alignment trade-offs in production without the risks of retraining.
My concern: the evaluation of "harmlessness" in most benchmarks is still primitive. Measuring refusal of clearly harmful requests is easy. Measuring calibrated, context-appropriate refusal of ambiguous requests is much harder. The benchmark improvements reported here may not transfer to the subtle safety failures that actually matter in production.
Also, the interaction between H3 dimensions and capability (raw benchmark performance) isn't fully explored. Highly aligned models often show capability regressions on raw reasoning benchmarks. Does model merging preserve or degrade these capabilities compared to data mixing? That's the question the next paper needs to answer.
Model merging for alignment is not the full solution. But it's a powerful additional tool in the alignment toolkit, with a specific advantage — runtime adjustability — that data mixing fundamentally cannot match.

Paper: "Mix Data or Merge Models? Balancing the Helpfulness, Honesty, and Harmlessness of Large Language Model via Model Merging", arXiv: 2502.06876, Feb 2025.