
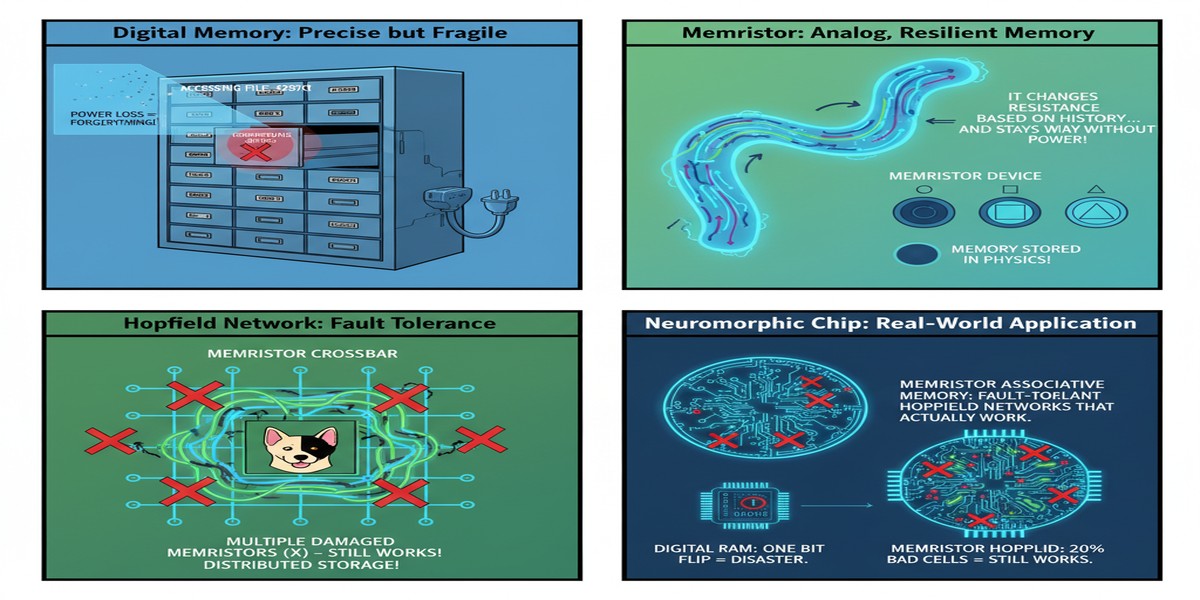
There is a particular kind of frustration that comes with memristor research papers. The physics is genuinely compelling — two-terminal devices with tunable resistance that retain their state without power, capable of performing multiply-accumulate operations in place, which is exactly what neural network inference requires. The fabrication is increasingly mature, with multiple groups demonstrating crossbar arrays of meaningful size. And yet the application layer consistently fails to account for the most fundamental practical reality of memristor hardware: devices fail, and they fail in ways that are not cleanly predictable.
Memristor crossbars have stuck-on faults, stuck-off faults, and gradual drift. Real arrays of any nontrivial size have fault rates that are not negligible. Most of the published work on memristor neural networks either ignores this reality entirely — demonstrating results on defect-free simulated crossbars — or applies post-hoc fault tolerance patches that were not designed into the learning algorithm from the start. The result is a large body of work that is technically valid but practically unreliable.
"Hardware-Adaptive and Superlinear-Capacity Memristor-based Associative Memory" by Chengping He et al. (arXiv:2505.12960, May 2025; Nature Communications 2026) attacks this problem from the correct direction. The learning algorithm is designed around hardware faults from the start, not patched afterward. The result is a Hopfield Network implementation that achieves 3x effective capacity under 50% device fault rates compared to state-of-the-art, extends to superlinear capacity scaling via a multilayer architecture, and delivers 2.68x–2.76x improvement in energy efficiency alongside a 99.4% reduction in processing time compared to digital implementations. These are extraordinary numbers on real hardware, and the methodology is sound.
Why Hopfield Networks on Memristors
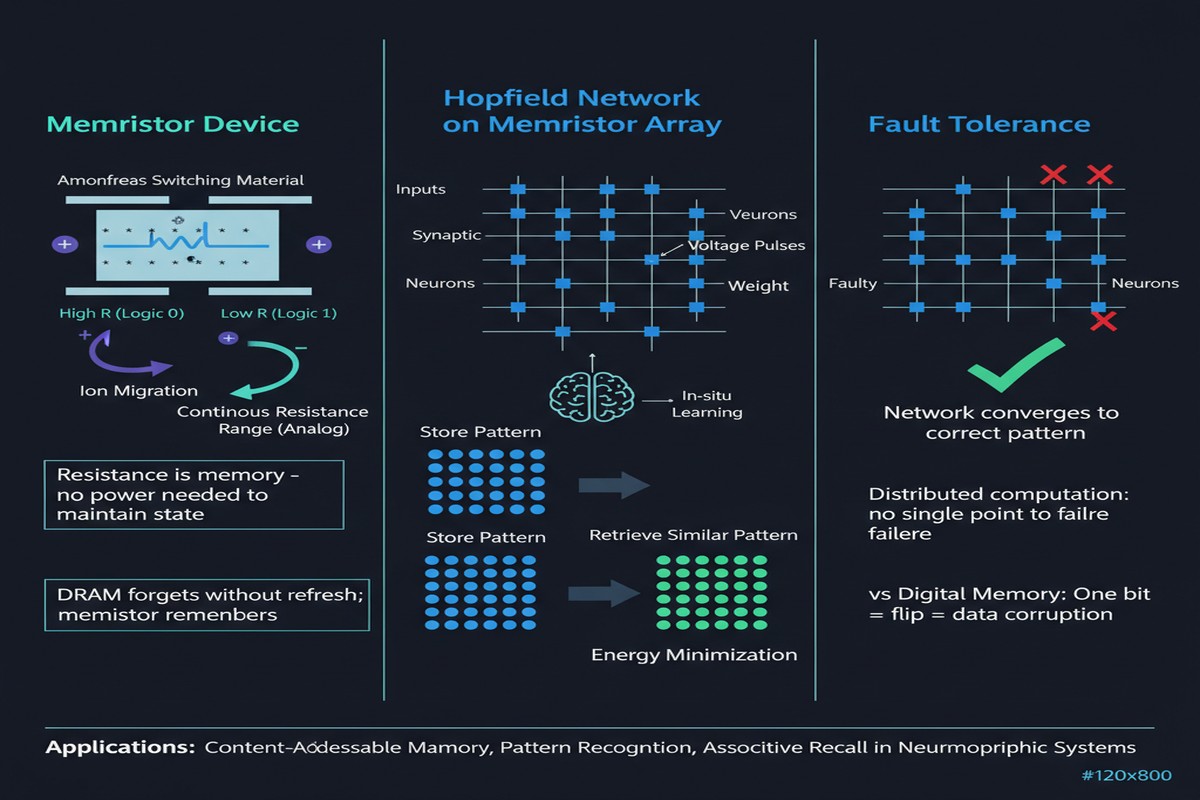
Hopfield Networks are associative memories — given a noisy or corrupted input pattern, they retrieve the closest stored clean pattern. The network is a fully connected symmetric weight matrix; the dynamics consist of updating each neuron to minimize a global energy function until convergence. When the weights encode stored patterns, convergence points correspond to stored memories.
The mapping to memristor crossbars is almost too natural. A memristor crossbar computes the matrix-vector product $\mathbf{y} = W\mathbf{x}$ in a single parallel operation — all rows simultaneously, in the time it takes current to flow through the crossbar. This is exactly the weight-input multiplication that Hopfield dynamics requires at each step. On a digital processor, you perform this multiplication sequentially using a MAC unit. On a memristor crossbar, you perform it in parallel using Ohm's law and Kirchhoff's current law. The energy consumption is dominated by the leakage currents in the crossbar, which are tiny compared to switching millions of transistors.
The theoretical efficiency advantage is clear. The practical problem is that a crossbar with 50% stuck faults is computing a corrupted weight matrix. The Hopfield dynamics will converge — but to corrupted memory patterns or spurious attractors. The effective capacity of the network plummets.
The Hardware-Adaptive Learning Algorithm
The central contribution is a learning algorithm that treats fault maps as input constraints rather than noise to be tolerated. The approach proceeds in three stages:
Fault characterization: Before learning, the crossbar is characterized to identify stuck-on and stuck-off cells. This produces a fault map — a binary mask indicating which crossbar cells are functional.
Constrained weight learning: The learning algorithm stores patterns using only the functional cells. Rather than distributing weights across all crossbar cells and accepting that some are corrupted, the algorithm concentrates weight storage in cells that are known to be working. This is the hardware-adaptive step. The weight assignments are a function of both the patterns to be stored and the hardware fault map.
Retrieval optimization: The retrieval dynamics are modified to account for the reduced effective weight precision resulting from the constrained assignment. The update rule incorporates a correction term derived from the fault map to compensate for systematic biases introduced by the missing weights.
The result is that a crossbar with 50% faults stores patterns as reliably as a near-perfect crossbar in conventional implementations — because the algorithm is using the same number of effective bits of information about the stored patterns. The faults reduce the raw capacity of the crossbar (fewer cells means fewer bits), but the algorithm uses the available cells maximally efficiently rather than wasting them on corrupted-but-not-yet-characterized cells.
flowchart TD
subgraph Phase1["Phase 1: Hardware Characterization"]
A[Memristor Crossbar Array] --> B[Fault Characterization\nSweep All Cells]
B --> C[Fault Map\nBinary: Working / Stuck]
end
subgraph Phase2["Phase 2: Hardware-Adaptive Learning"]
D[Patterns to Store] --> E[Constrained Weight\nSolver]
C --> E
E --> F[Weight Assignment\nFunctional Cells Only]
F --> G[Program Crossbar\nVerified Cells]
end
subgraph Phase3["Phase 3: Fault-Aware Retrieval"]
H[Noisy Input\nPattern] --> I[Crossbar\nMatrix-Vector Product]
G --> I
C --> J[Retrieval Correction\nBias Compensation]
I --> J
J --> K{Energy\nMinimized?}
K -->|No| I
K -->|Yes| L[Retrieved Clean\nMemory Pattern]
end
subgraph MultilayerExt["Multilayer Extension"]
M1[Layer 1\nCrossbar] --> M2[Layer 2\nCrossbar]
M2 --> M3[Layer N\nCrossbar]
M3 --> M4[Superlinear\nCapacity Scaling]
end
Phase1 --> Phase2 --> Phase3
Phase3 -.->|"Extend to"| MultilayerExt
style C fill:#0f3460,color:#fff
style L fill:#16213e,color:#00d4ff
style M4 fill:#16213e,color:#00d4ff
style Phase1 fill:#1a1a2e,color:#ccc
style Phase2 fill:#1a1a2e,color:#ccc
style Phase3 fill:#1a1a2e,color:#ccc
Superlinear Capacity Scaling via Multilayer Extension
Classical Hopfield Networks have a known capacity limit: approximately 0.138N patterns in a network of N neurons when using the Hebbian learning rule. Modern dense associative memory extensions raise this somewhat, but the scaling remains sub-linear in network size for fixed precision weights.
The multilayer extension in this paper achieves superlinear capacity scaling by stacking multiple crossbar layers in a hierarchical retrieval architecture. The first layer stores a subset of patterns; patterns that the first layer cannot reliably retrieve are escalated to the second layer with a refined representation. The key result is that total capacity grows faster than linearly with the number of layers — each additional layer contributes disproportionately to retrieval capability because it targets specifically the patterns that lower layers find ambiguous.
This is analogous to ensemble methods in classical machine learning — combining multiple weak classifiers to exceed the performance of any individual. The multilayer Hopfield construction is the associative memory analogue, and the memristor crossbar is the natural substrate because each layer can be a separate crossbar array, and the inter-layer communication is a matrix-vector product that maps directly onto another crossbar.
The capacity result under 50% faults is the headline number: 3x improvement over state-of-the-art with equivalent or higher fault tolerance. This is not an incremental improvement. It means a memristor crossbar with half its cells broken stores three times as many patterns as the best previous method on the same hardware. The practical implication is that memristor associative memory becomes viable for production deployment at current manufacturing fault rates — you do not need to wait for perfect fabrication yield.
The Energy and Speed Numbers
The 2.68x–2.76x improvement in energy efficiency is measured against digital implementations of the same Hopfield dynamics on conventional processors. The mechanism is the in-memory compute advantage: the crossbar performs the weight-input multiply in parallel using current summation, consuming energy proportional to the leakage current and programming voltage — much less than the switching energy of the transistors that would be required for the equivalent digital matrix-vector multiply.
The 99.4% reduction in processing time is the more dramatic figure. This comes from the parallelism of crossbar computation: all neurons in a layer are updated simultaneously in the time of a single current settling event (nanoseconds to microseconds, depending on crossbar size and device parameters). A digital implementation updates neurons sequentially or in small batches limited by vector unit width. For a Hopfield network with thousands of neurons, the crossbar advantage in time-to-convergence is roughly proportional to the number of neurons — hence the dramatic speedup.
I want to be careful about the comparison baseline here. The paper compares against a software Hopfield implementation on a CPU, which is not the strongest possible baseline. An FPGA implementation or a GPU-accelerated Hopfield network would reduce the speedup factor. But the energy efficiency comparison is more fundamental: the in-memory compute advantage over digital arithmetic is a physical property of the substrate, not an implementation detail.
Why This Matters
Associative memory is a genuinely useful computational primitive that has been largely absent from the AI systems stack because digital implementations are too slow and too power-hungry for the use cases where it matters most. Edge devices that need to recognize patterns from noisy sensor data — a wearable that recognizes a user's handwriting, a sensor node that identifies machine anomalies from vibration signatures, a medical implant that classifies neural activity patterns — are natural homes for associative memory. They need fast, low-power pattern retrieval from a stored library of known patterns.
The memristor crossbar provides the right physical substrate for this at the edge. The hardware-adaptive learning algorithm in this paper removes the fabrication-yield barrier that has prevented practical deployment. The 50% fault tolerance threshold is significant: current state-of-the-art memristor crossbar fabrication processes typically yield fault rates in the 5–30% range, well below the 50% threshold where this algorithm has been demonstrated.
That means the algorithm works on hardware you can actually buy or fabricate today, not on hypothetically perfect future hardware. That is the distinction between research that matters and research that is waiting for the future to arrive.
My Take
This is one of the most practically grounded memristor papers I have read in the last two years. The common failure mode in neuromorphic hardware papers is to demonstrate impressive results on either simulated hardware or hardware that required extensive manual selection for low defect rates. He et al. confront the defect problem directly and demonstrate results under genuinely harsh fault conditions.
The hardware-adaptive learning approach is conceptually clean and the implementation is not exotic. The fault characterization step is a standard test sequence that any manufacturing process already includes. The constrained weight learning is a quadratic optimization problem that can be solved efficiently for crossbar sizes of practical interest. The retrieval correction is a constant-time bias adjustment. None of this requires specialized hardware beyond the crossbar itself.
My only reservation concerns the scalability of the fault characterization step. As crossbar arrays scale to millions of cells, exhaustive characterization becomes time-consuming. The paper does not address hierarchical or sampling-based fault characterization strategies that would be necessary for large arrays. This is a solvable engineering problem, but it needs to be solved before the approach scales to the array sizes that would make it competitive with DRAM-based pattern storage systems.
The Nature Communications publication is well-deserved. This is substantive work with clear practical relevance and honest experimental methodology. If you are building edge inference hardware or evaluating neuromorphic memory architectures, this paper should be required reading.
The memristor field has been promising production-readiness for a decade. Papers like this are how promises turn into reality — by addressing the engineering problems that actually block deployment, not just the physics problems that are interesting to study.
Paper: "Hardware-Adaptive and Superlinear-Capacity Memristor-based Associative Memory" — Chengping He et al., arXiv:2505.12960, May 2025. Also published in Nature Communications 2026.


