The problem of making a language model do what you want — not just predict plausible text but respond helpfully, honestly, and safely — has turned out to be one of the central technical challenges of this generation of AI. Two approaches have dominated the conversation: Reinforcement Learning from Human Feedback (RLHF), which powered the ChatGPT moment and remains the backbone of most frontier systems, and Direct Preference Optimization (DPO), which promised to achieve similar results with a fraction of the engineering complexity.
Understanding the difference between them matters whether you are training your own models, evaluating commercial systems, or trying to form a principled view of where AI safety work is heading.
RLHF: The Original Recipe
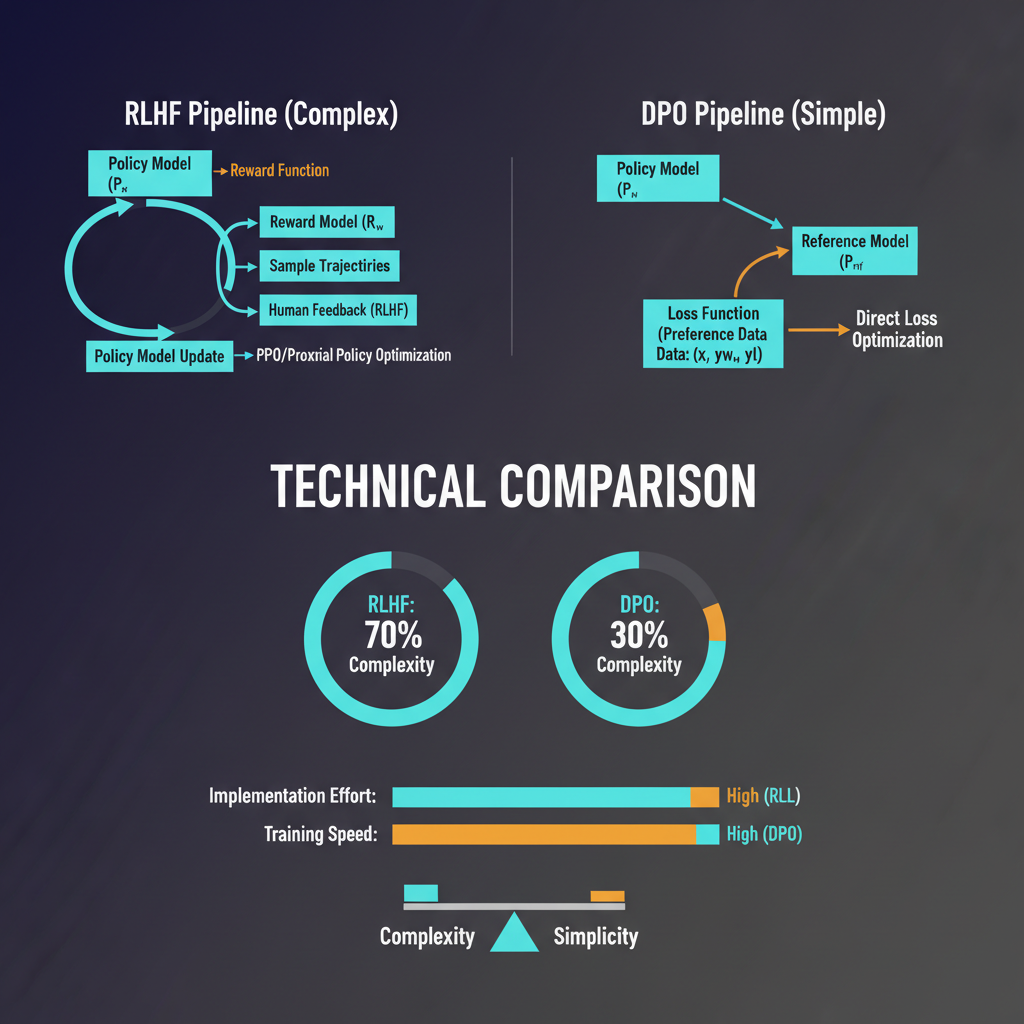
The InstructGPT paper (Ouyang et al., 2022) is the document that turned RLHF from an academic curiosity into the dominant paradigm for aligning large language models. The approach has three stages. First, collect demonstration data: human labelers write high-quality responses to prompts, and you fine-tune the base language model on these to get a supervised fine-tuned (SFT) model. Second, collect comparison data: for each prompt, generate multiple model outputs and have human labelers rank them, then train a reward model on these preferences. Third, use proximal policy optimization (PPO) — a reinforcement learning algorithm — to fine-tune the SFT model to maximize the reward model's score, with a KL-divergence penalty to prevent the policy from drifting too far from the original.
This is legitimately complicated. PPO is notoriously finicky to train; it requires careful hyperparameter tuning, careful reward model training, and significant engineering to make stable at scale. The reward model can be "gamed" by the policy in unexpected ways — a phenomenon called reward hacking, where the model learns to produce outputs that score well on the reward model without being genuinely better. The KL penalty is the main guard against this, but calibrating it is more art than science.
Despite the complexity, RLHF works remarkably well. GPT-4, Claude 3, and Gemini Ultra all rely on RLHF variants (often combined with constitutional methods). The approach can meaningfully improve instruction following, reduce harmful outputs, and produce more coherent multi-turn conversations. The InstructGPT paper showed that a 1.3B parameter RLHF-tuned model was preferred over the raw 175B GPT-3 by human evaluators — a stunning result that underscored how much post-training alignment matters.
DPO: Simplicity as a Feature
In 2023, Rafailov et al. published "Direct Preference Optimization: Your Language Model is Secretly a Reward Model," and the alignment community took notice. DPO's insight is elegant: the PPO step in RLHF is doing something you can actually do directly. Given a preference dataset (preferred response versus rejected response for a given prompt), you can directly fine-tune the language model using a reparameterization that optimizes for the same objective as RLHF — but without explicitly training a reward model and without running PPO.
The DPO objective is a binary cross-entropy loss where you increase the log-likelihood of preferred responses and decrease the log-likelihood of rejected responses, weighted by how much the current policy diverges from the reference policy on those responses. The math is clean, the implementation fits in roughly 50 lines of PyTorch, and you do not need a separate reward model at all.
The appeal was immediate and understandable. PPO requires running both the policy model and the reward model during training, typically on the same hardware, which means RLHF at scale requires significant infrastructure. DPO reduces this to a standard supervised fine-tuning setup with a modified loss. For the open-source community, which was suddenly able to train competitive instruction-following models on modest hardware, DPO was transformative. Zephyr, Tulu, and a wave of capable models emerged from DPO-based recipes.
Where the Comparison Gets Complicated
The natural question is: which is better? The honest answer is that it depends on what you mean by "better" and at what scale.
For mid-scale models — the 7B to 70B range that dominates practical deployment — DPO often performs comparably to RLHF on standard benchmarks. Alpaca Eval, MT-Bench, and similar evaluation frameworks show DPO-trained models in the same general performance range as RLHF-trained ones, sometimes ahead, sometimes behind. The variance is high and the differences are often within the noise of evaluation methodology.
But at frontier scale, the picture shifts. GPT-4 and Claude 3 Opus are RLHF-trained systems (with significant modifications), and the evidence suggests that for the most capable models, RLHF's explicit reward model and RL optimization step provides degrees of freedom that DPO lacks. Specifically, RLHF can optimize for complex, non-binary reward signals — not just "preferred vs. rejected" but nuanced rubrics, multi-dimensional quality assessments, and iterative improvements as the policy improves. DPO, by contrast, is tied to a static preference dataset; it cannot dynamically generate new challenging examples and assess them as training proceeds.
This connects to a deeper point about on-policy versus off-policy learning. DPO is fundamentally off-policy: the preference data was generated by some model (often the SFT model), and DPO updates the policy based on that fixed dataset. RLHF with PPO is online: the policy generates new completions, gets scored by the reward model, and updates accordingly. Online learning allows the model to explore and improve in ways that off-policy methods cannot.
Variants and Hybrids
The field has not settled for the binary choice. Several variants have emerged that try to capture the best of both approaches.
RAFT (Reward rAnked Fine-Tuning) and similar iterative DPO methods address the off-policy problem by alternating between generating new completions from the current policy, scoring them with a reward model, and running DPO on the resulting preferences. This adds back some of the online learning benefits while keeping the simplicity of the DPO loss.
IPO (Identity Preference Optimization) and KTO (Kahneman-Tversky Optimization) address theoretical weaknesses in DPO — specifically, the fact that DPO can overfit to the specific format of preference pairs and be sensitive to the distribution of rejected responses. KTO in particular abandons the pairwise preference framing entirely and works with point-wise signals: simply whether a given response is good or bad, without needing a paired comparison.
Anthropic's Constitutional AI approach adds another dimension: rather than relying solely on human preferences, it uses AI feedback to generate preference labels at scale, producing what they call RLAIF (RL from AI Feedback). This can dramatically increase the volume of preference signal available and allows incorporating explicit principles (the "constitution") into the reward signal in ways that are hard to do with purely human-labeled data.
Practical Guidance
For practitioners working with models in the 7B-70B range:
DPO is a strong baseline. The implementation simplicity is a genuine advantage, and if you have a high-quality preference dataset, DPO will get you 80-90% of the way to a well-aligned model with a fraction of the infrastructure cost. Use it for iterative experimentation.
If you are scaling up or need fine-grained control over specific behaviors — reducing particular failure modes, optimizing for specific user populations, or pushing performance on hard tasks — RLHF provides levers that DPO does not. The investment in reward model training and PPO infrastructure pays off at scale.
Data quality matters more than algorithm choice. Both RLHF and DPO can be undermined by low-quality preference data. Human labeler disagreement, ambiguous prompts, and inconsistent quality signals poison the well for any preference learning approach. Budget significantly for data collection and quality control.
Watch out for distribution shift. Both approaches are vulnerable to the policy learning shortcuts that happen to correlate with high preferences in your training data but do not generalize. Evaluation on held-out prompts and red-teaming are not optional.
The Deeper Question
The RLHF vs. DPO debate is partly a technical question and partly a philosophical one: what does it mean for a model to be "aligned"? Both approaches optimize for some operationalization of human preference, and both are therefore constrained by what human preferences capture and fail to capture. A model that is brilliant at producing text that human labelers rate highly might still be confidently wrong, subtly manipulative, or aligned with the preferences of a non-representative labeler population.
This is why the alignment problem is not solved by either RLHF or DPO — it is merely redirected. The harder questions about whose preferences, how to handle disagreement, and how to align models with long-term human values rather than immediate approval remain active areas of research. But having these sophisticated optimization tools is a prerequisite for engaging with those harder questions seriously.
The battle between RLHF and DPO is not over. It may be that they converge on similar approaches as online DPO variants mature. What is clear is that preference learning, in some form, is central to how we build models that behave well — and understanding its mechanics is essential for anyone working seriously in this field.


