There is a puzzle at the heart of scaling language models. Making a model bigger generally makes it better — this is the central finding of scaling laws research. But bigger models are more expensive to run, and the cost grows with the number of parameters that are active during each forward pass. If you want a model with 500 billion parameters but the inference economics of a 50 billion parameter model, standard dense transformers offer no good solution.
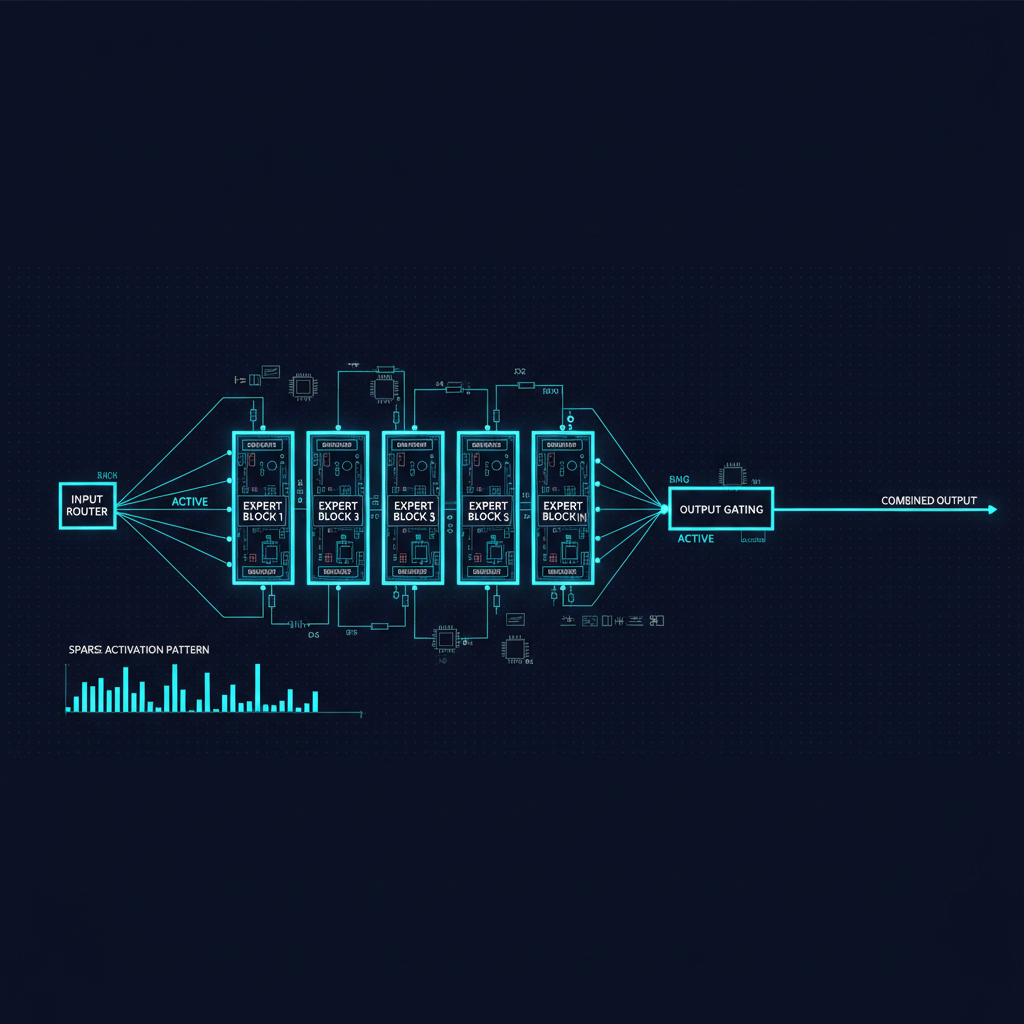
Mixture of Experts (MoE) architectures break this constraint. By replacing the dense feed-forward layers in a transformer with a collection of "expert" sub-networks and a routing mechanism that activates only a small subset per token, MoE enables models with enormous total parameter counts while keeping per-token computation comparable to a much smaller dense model.
This is not a new idea — the term "Mixture of Experts" originates from Jacobs et al. in 1991, and Shazeer et al. reintroduced it for neural networks in 2017 with their "Outrageously Large Neural Networks" paper. But the technique has reached maturity in the current generation of frontier models in ways that make it genuinely transformative.
The Core Architecture
A standard transformer layer consists of a self-attention block followed by a feed-forward network (FFN). The FFN typically has two linear layers with a nonlinearity between them, and it is responsible for most of the model's parameter count and computation. In a dense model, this FFN processes every token identically.
In an MoE layer, the FFN is replaced by N expert FFNs (where N might be 8, 16, 64, or even more), plus a router network. The router looks at the representation of each token and outputs a routing decision — typically, scores for each expert, from which the top-k are selected (with k often equal to 1 or 2). The token is processed by those k experts, and the results are combined (usually as a weighted average).
The critical insight is that the model has many more total parameters (all those expert FFNs), but each forward pass only uses a fraction of them (just the selected experts for each token). If you have 8 experts and select the top 2, you are using 2/8 = 25% of the expert parameters per token. Your total parameter count might be 8x larger than a comparable dense model, but your per-token computation is roughly comparable to the dense model.
This is sometimes called the "sparse activation" property of MoE models. The sparsity is what enables scale.
Mixtral and the Open MoE Moment
Mistral AI's release of Mixtral 8x7B in December 2023 brought MoE architecture to the open-source community in a compelling way. Mixtral has 8 experts per layer, each with 7B parameters, and selects 2 experts per token — giving it roughly 46.7B total parameters but approximately 12.9B active parameters per forward pass. It outperformed Llama 2 70B on most benchmarks while using roughly half the inference compute. This was a striking demonstration that MoE was not just a theoretical advantage but a practical one.
Mixtral's release prompted a wave of open MoE work. The architecture details — how to implement efficient routing, how to handle expert load balancing, how to manage the distributed training of models where different experts may be on different devices — became widely shared knowledge. Subsequent releases like DeepSeek-MoE and Qwen's MoE variants refined the approach further.
DeepSeek-MoE introduced a fine-grained expert design where a larger number of smaller experts (64 experts, selecting 6) replaced fewer larger experts, finding that the increased routing granularity improved quality. They also introduced the concept of "shared experts" — a subset of experts that always process every token — to prevent loss of general-purpose processing capability that fine-grained routing might otherwise fragment.
GPT-4 and Frontier MoE
OpenAI has never officially confirmed the architecture of GPT-4, but multiple reports from people with apparent knowledge of the system suggest it uses an MoE design with approximately 8 experts and roughly 220B total parameters. If accurate, this would explain both GPT-4's exceptional capability (large total parameter count) and its inference economics (much smaller active parameter count per token).
This would be entirely consistent with the direction of the field: MoE is now the obvious way to build very capable models that can also be served economically. The tradeoff is not free — serving an MoE model requires loading all expert weights, even if only a few are activated per token — but the inference efficiency benefits for generation are substantial.
Google's Gemini architecture, particularly Gemini 1.5, reportedly uses a MoE design as well. The 1M token context window and competitive benchmark performance of Gemini 1.5 Pro make more sense from an architectural perspective if MoE is reducing the per-token computation to manageable levels.
Routing and Its Challenges
The routing mechanism is where much of the interesting research in MoE lives. Several problems have needed to be solved.
Expert collapse. A naive router tends to concentrate traffic on a small number of popular experts, while others are rarely used. This defeats the purpose of having many experts. Early MoE models addressed this with load-balancing auxiliary losses that penalize uneven expert utilization. These work but introduce a tradeoff: the load-balancing loss fights against the model learning to use experts most effectively, which would naturally concentrate some routing.
Token dropping. In distributed training, expert capacity is typically capped to prevent stragglers (one expert with very high load). Tokens routed to an expert beyond its capacity are dropped — they pass through without expert processing. This degrades performance and complicates training dynamics. More recent approaches use "expert choice" routing, where experts choose which tokens to process rather than tokens choosing which experts, which naturally enforces even utilization without loss.
Communication overhead. In distributed training (and inference) where experts are on different devices, routing requires communicating token representations across the network. For very large models with many experts across many devices, this communication overhead can be significant. The design of efficient collective communication primitives for MoE models is an active systems research area.
Expert specialization. Do experts actually specialize, and if so, in what? Analysis of trained MoE models has found that experts do develop preferences: some tend to process syntactically similar tokens (punctuation, conjunctions), while others activate more on domain-specific content. The specialization is real but less clean than the "expert on French history vs. expert on Python code" intuition suggests. Understanding and guiding this specialization is an open research question.
MoE vs. Dense: Practical Tradeoffs
For practitioners choosing between MoE and dense architectures, several considerations apply.
Inference throughput vs. latency. MoE models have better throughput (tokens per second at high batch sizes) than comparable-quality dense models, because the active compute per token is lower. But they have higher latency at small batch sizes (like interactive single-user use), because the model still needs to load all expert weights even when only a few are activated. This makes MoE particularly attractive for high-volume API providers and less attractive for edge or single-user deployment.
Memory requirements. An MoE model with 8 experts and 2 selected per token might have 4x the total parameters of a comparable-quality dense model, but only 2/8 = 0.25x of them activated per token. You still need to fit all the weights in memory somewhere (they need to be available for routing decisions), even if most are idle at any given moment. For serving, this means MoE requires more aggregate GPU memory than a dense model of comparable inference compute cost.
Fine-tuning complexity. Fine-tuning MoE models is more complex than fine-tuning dense models because the routing decisions themselves may shift during training, potentially destabilizing the load balance. Some practitioners freeze the router during fine-tuning to avoid this. LoRA fine-tuning of MoE models can be applied either to the expert weights only, the router, or both, with different implications for downstream performance.
The Future of MoE
The architecture continues to evolve. Conditional computation — the idea of activating different parts of a model based on what is being processed — is broader than just the FFN layers. Attention MoE (sparse attention patterns conditioned on content) and hierarchical routing (routing at multiple levels of granularity) are areas of active exploration.
Perhaps most interesting is the possibility of MoE architectures where different experts are served from different hardware — allowing effective model sizes that cannot fit on any single cluster but are served by routing tokens across distributed expert pools. This "model parallelism via routing" approach could enable future models with trillions of total parameters that remain economically servable.
The lesson of MoE for the field is that scale and efficiency are not simply in tension. With the right architecture, you can have more capacity than a dense model while spending less per query. That tradeoff is increasingly being exploited at every tier of the model size distribution.


