
Here's a dirty secret about graph RAG in production: relation extraction is terrible.
The premise of knowledge graph RAG is that you extract (subject, predicate, object) triples from your documents, store them in a graph, and retrieve over the graph structure to answer complex questions. This works in demos on curated datasets. In production, it breaks because relation extraction — the step where you identify that "X founded Y" or "A is the parent company of B" — is unreliable at scale.
State-of-the-art relation extraction models achieve 60-75% F1 on academic benchmarks. On your messy real-world documents — with domain-specific terminology, implicit relationships, abbreviations, and context-dependent meanings — it's worse. Your knowledge graph is built on a foundation of extraction errors.
LinearRAG, published October 2025 by Luyao Zhuang and colleagues from Hong Kong Polytechnic University, proposes a radical solution: don't extract relations.
The Tri-Graph Architecture
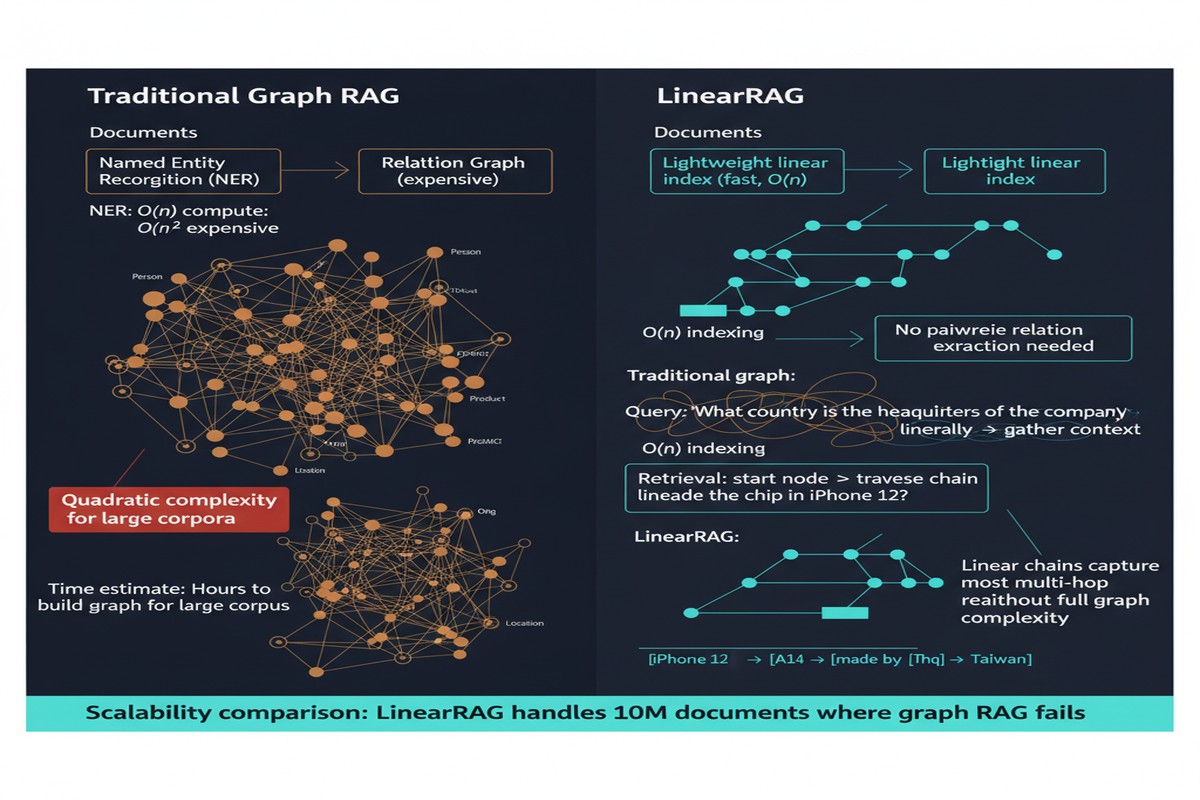
LinearRAG's central innovation is building a graph structure without requiring relation extraction. Instead of (entity, relation, entity) triples, it builds what the paper calls a Tri-Graph: three layers of interconnected representations.
graph TD
subgraph Document Corpus
D1[Document 1] & D2[Document 2] & D3[Document 3]
end
subgraph Tri-Graph Construction
D1 & D2 & D3 --> EI[Lightweight Entity Identification\nNER without relation extraction]
EI --> L1[Layer 1: Entity Nodes\nCore named entities with metadata]
L1 --> L2[Layer 2: Passage Nodes\nText chunks linked to entities]
L2 --> L3[Layer 3: Semantic Cluster Nodes\nSemantically similar passages grouped]
L1 --->|Co-mention links| L1
L2 --->|Semantic similarity links| L2
L3 --->|Hierarchical links| L3
end
subgraph Retrieval
Q[Query] --> A1[Phase 1: Entity Activation\nLocal semantic connections]
A1 --> A2[Phase 2: Passage Ranking\nGlobal importance scoring]
A2 --> A3[Answer Generation]
end
The three layers:
Layer 1 — Entity Nodes: Standard NER identifies entities in each document. No relation extraction — just "Infosys is in this document" and "Bengaluru is in this document," not "Infosys is headquartered in Bengaluru." Entity metadata (type, frequency, document co-occurrence) is stored.
Layer 2 — Passage Nodes: Text chunks are connected to the entities they contain. This creates entity-passage links without requiring relation extraction.
Layer 3 — Semantic Cluster Nodes: Groups of passages that are semantically similar (by embedding similarity) are connected, creating a hierarchical structure. This captures thematic coherence without explicit topic modeling.
The key insight: co-mention is sufficient for most retrieval tasks. If entity A and entity B appear frequently in the same passages, there's a relationship worth following, even if you don't know its precise type. LinearRAG captures this signal through graph structure without requiring error-prone predicate extraction.
Retrieval: Two-Phase, Scalable
The retrieval mechanism operates in two phases, designed for efficiency at scale:
Phase 1 — Entity Activation: The query is processed to identify entities. Matching entities in the Tri-Graph are activated, along with their connected passages and neighboring entities (via co-mention links). This is local graph traversal with bounded cost.
Phase 2 — Global Passage Ranking: Activated passages are ranked using a global importance score that combines local relevance (how directly the passage connects to query entities) with global significance (PageRank-style measure of passage centrality in the Tri-Graph). This phase is what the paper calls "linear" — it scales linearly with corpus size rather than quadratically like dense graph traversal.
The two-phase approach separates precision from recall concerns. Phase 1 ensures recall — you don't miss relevant passages that connect to query entities. Phase 2 ensures precision — you rank the most important passages to the top.
Why Relation Extraction Fails at Scale
I want to dwell on the relation extraction problem, because I think it's underappreciated.
Consider a simple sentence: "Google announced its acquisition of DeepMind in January 2014 for approximately $500 million."
A relation extractor needs to identify:
- (Google, acquired, DeepMind) — relatively easy
- (acquisition, date, January 2014) — temporal extraction, harder
- (acquisition, price, $500 million) — numerical extraction, harder
- (Google, is_acquirer_in, acquisition) — event-role extraction, harder still
For every sentence in your corpus. At scale, with domain-specific terminology. With implicit references ("the company" referring to Google three sentences back). With passive voice. With complex syntax.
Production-quality relation extraction at corpus scale remains an unsolved problem. LinearRAG is honest about this and designs around it.
graph LR
subgraph Why Relation Extraction Fails
RE[Relation Extraction] --> E1[Error Type 1:\nMissed relations\n~25-40% missing]
RE --> E2[Error Type 2:\nWrong predicate\n~15-20% wrong type]
RE --> E3[Error Type 3:\nWrong entity span\n~10-15% wrong entity]
E1 & E2 & E3 --> KG_Error[Knowledge Graph\nBuilt on ~50% correct triples]
end
subgraph LinearRAG
NER[Named Entity Recognition\n~85-90% accuracy] --> CG[Co-mention Graph\nSimpler, more reliable]
CG --> Better[Better retrieval foundation]
end
Performance Results
On four knowledge-intensive QA benchmarks, LinearRAG outperforms:
- Standard dense RAG by significant margins on multi-hop questions
- GraphRAG-style systems on most benchmarks, despite using simpler graph construction
- Previous linear-time graph retrieval approaches
The key comparison is against standard GraphRAG: LinearRAG performs better while being computationally cheaper and significantly more reliable to build. The paper includes a cost analysis showing substantially reduced construction time for large corpora.
What's Not Addressed
The paper's evaluation is on factoid QA benchmarks. Two limitations deserve attention:
Long-tail entities: NER accuracy drops significantly for rare, domain-specific entities. In medical documents, legal filings, or technical manuals, the entities that matter most are often the ones that general-purpose NER misses. The performance on specialized corpora is likely lower than the paper's benchmarks suggest.
Relation-critical queries: Some questions genuinely require knowing the type of relationship, not just the existence of co-mention. "Is A the parent company or subsidiary of B?" requires knowing the direction and type of the ownership relation. LinearRAG's co-mention approach can't distinguish between these cases. For queries where relation type matters, you need relation extraction.
The paper is honest about this — it positions LinearRAG for corpora where relation extraction is unreliable, not as a universal replacement.
My Take
LinearRAG is a pragmatic response to a real engineering problem. The decision to abandon relation extraction is bold, and the results justify it. By starting from what's actually reliable (NER is much better than relation extraction), the system builds a stronger foundation even if that foundation is less expressive.
The "linear" in LinearRAG refers to both the graph structure and the retrieval complexity — the system scales linearly rather than quadratically with corpus size. For large enterprise corpora with millions of documents, this is not a trivial property. Quadratic scaling in graph traversal is what makes many theoretical graph RAG systems impractical at real scale.
My recommendation: if you're considering graph RAG for a large, heterogeneous corpus and you've been deterred by the complexity and unreliability of relation extraction, LinearRAG is the place to start. It gives you most of the benefits of graph structure without the most fragile component.
For smaller, curated corpora where relation extraction quality can be validated, a full KG approach may still outperform. For production scale, LinearRAG's simpler, more reliable foundation is the right trade.
arXiv: 2510.10114



