Multi-agent systems fail for many reasons, but one of the most consistent failure modes I see is mismatched orchestration patterns. Teams pick a pattern because it looks clean in a diagram, or because it is what the tutorial used, or because "swarm" sounds sophisticated. Then they discover in production that their architecture cannot handle the actual failure modes of their task domain.
Orchestration patterns are not interchangeable. Each encodes different assumptions about task structure, agent reliability, communication overhead, and failure recovery. Choosing the wrong pattern does not just reduce performance — it can make a system behave in ways that are fundamentally hard to debug and impossible to reason about.
Let me walk through the major patterns, their trade-offs, and when to use each.
Pattern 1: Pipeline (Sequential)
The simplest multi-agent pattern: agents execute in sequence, each receiving the output of the previous agent as input. Agent A processes raw input and produces Artifact 1. Agent B takes Artifact 1 and produces Artifact 2. Agent C takes Artifact 2 and produces the final output.
When it works: Tasks with clear, separable stages where each stage has a well-defined input and output format. Document processing pipelines (extract → summarize → classify → route), code generation pipelines (spec → code → test → review), and data enrichment pipelines are natural fits.
Failure mode: Error propagation. A mistake in stage 1 propagates and compounds through all subsequent stages. By stage 4, the agent is working from corrupted input and producing outputs that are internally coherent but externally wrong. The final output often looks plausible even when the upstream error was significant.
Mitigation: Add validation gates between stages. Each stage should check its input before processing, not just produce its output. A simple structural check — "does this input have the expected fields?" — catches many upstream errors before they compound. In LangGraph, this is straightforward to implement as an intermediate node that inspects the state object, identifies any missing required keys, and returns a structured error that halts the pipeline before the next stage wastes compute on corrupted input.

Pattern 2: Supervisor (Centralized Control)
A manager/supervisor agent receives the task, breaks it into subtasks, assigns subtasks to specialized worker agents, collects results, and synthesizes the final output. The supervisor maintains global state and decides when the task is complete.
When it works: Tasks that require dynamic decomposition — where the subtask breakdown cannot be determined until you start working on the problem. Research tasks with unknown scope, debugging tasks where the problem structure is unknown, analysis tasks where the right analytical approach depends on early findings.
Failure mode: Single point of failure in the supervisor. If the supervisor makes a poor decomposition decision early, or if it loses track of context in a long task, the entire workflow produces poor results. The supervisor also tends to become a bottleneck — every worker agent must wait for supervisor coordination.
Implementation in LangGraph: The supervisor pattern maps cleanly onto a graph where the supervisor node holds a typed state object tracking the full task, the list of subtasks it has decomposed the work into, a log of completed subtasks with their outputs, and a slot for the final synthesis. On each invocation, the supervisor either performs the initial decomposition if no subtasks exist yet, checks whether all subtasks are done and signals readiness for synthesis, or identifies and assigns the next pending subtask. A conditional routing function reads the supervisor's decision and directs the graph to the appropriate worker node or to the synthesis step.
Pattern 3: Swarm (Decentralized, Emergent)
Swarm patterns eliminate the central supervisor. Agents observe the shared environment and self-select tasks based on their capabilities and what work remains. OpenAI's Swarm framework and similar implementations treat agent handoffs as a first-class primitive — any agent can pass the conversation to any other agent when it determines that a specialist would be more effective.
When it works: High-volume tasks where many similar subtasks need to be processed and the assignment logic is simple. Customer service routing is a canonical example: a triage agent routes to specialized agents, and any agent can escalate or re-route based on what they discover. The advantage is throughput — no supervisor bottleneck, agents can work in parallel without coordination overhead.
Failure mode: Deadlocks, infinite handoff loops, and task loss. Without a central coordinator, it is possible for tasks to bounce between agents indefinitely, for two agents to simultaneously claim the same task, or for tasks to be dropped when all agents assess the work as outside their specialization. Swarm systems also lack clear state — there is no single place to look to understand where a task is in its lifecycle.
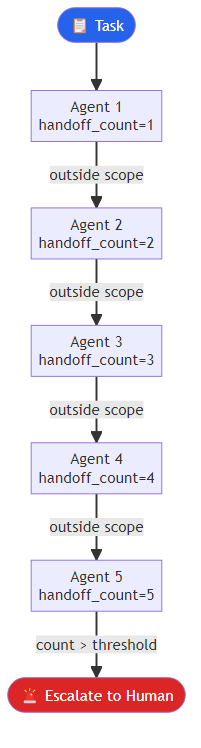
Critical requirement: Swarm systems need explicit handoff protocols with loop detection. A handoff decision function should inspect the list of agents that have already handled the current task and immediately escalate to a human if that list exceeds a threshold — say, five handoffs. Below that threshold, the function applies simple routing logic based on task properties to select the next agent. This prevents the runaway handoff chains that cause tasks to disappear into the system.
Pattern 4: Hierarchical (Nested Supervisors)
An extension of the supervisor pattern where supervisors manage sub-supervisors, who manage workers. This mirrors organizational hierarchies and is appropriate for genuinely large, complex tasks.
When it works: Enterprise-scale automation where different departments or functional areas have distinct workflows and the top-level task requires coordination across all of them. Think of a "build and launch a product feature" task: a top-level supervisor coordinates product, engineering, and QA supervisors, each of which manages their own specialized workers.
Failure mode: Latency and cost. In a three-level hierarchy, every worker action requires bubbling up through two supervisor layers. Communication overhead scales with hierarchy depth, and each supervisor node adds both latency and token cost. Hierarchical systems also tend to have the most complex debugging profiles — tracing a failure back to its root cause requires traversing multiple layers of agent reasoning.
Design principle: Keep hierarchies shallow. Two levels (supervisor + workers) handle most realistic use cases. Three levels should be rare and deliberate. Four levels is a design smell.
Pattern 5: Debate and Critic
Multiple agents independently produce solutions to the same problem, then critique each other's outputs. A synthesis agent (or a final round of the generating agents) produces a final answer that incorporates the critiques.
When it works: High-stakes decisions where correctness matters more than speed. Complex analysis tasks where different analytical framings might reach different conclusions. Code review. Research synthesis. Any task where "two heads are better than one" intuition applies.
Research support: The 2023 paper "Improving Factuality and Reasoning in Language Models through Multiagent Debate" (Du et al., NeurIPS) demonstrated measurable improvements on arithmetic reasoning, strategic reasoning, and bias reduction tasks when multiple agents debated before producing a final answer. The key finding was that debate helps most when agents are initialized with diverse prompts or different model configurations — a debate between two identically configured agents reduces to repeated sampling, not genuine deliberation.
Failure mode: Cascade bias. If one agent's initial response is confident and plausible but wrong, other agents tend to update toward that response rather than maintaining independent assessment. This is a multi-agent analog of anchoring bias. Mitigate by preventing agents from seeing each other's initial responses until all have produced independent answers.
Choosing the Right Pattern: A Decision Framework
| Criteria | Pipeline | Supervisor | Swarm | Hierarchical | Debate |
|---|---|---|---|---|---|
| Task structure known in advance | Yes | Partially | No | Partially | Yes |
| High throughput required | Yes | No | Yes | No | No |
| Correctness > speed | No | Partially | No | No | Yes |
| Complex task decomposition | No | Yes | No | Yes | No |
| Simple failure recovery required | Yes | Partially | No | No | Yes |
A practical rule of thumb: start with the simplest pattern that could work, and add complexity only when you have evidence that simpler approaches fail. Most tasks that seem to require swarm or hierarchical orchestration actually work fine with a supervisor and three to five specialized workers. The additional complexity of more sophisticated patterns rarely pays for itself until you have genuinely large-scale parallelism requirements or organizational-scale task hierarchies.
The pattern you choose sets the ceiling on what your system can reliably do. Choose deliberately.
Explore more from Dr. Jyothi