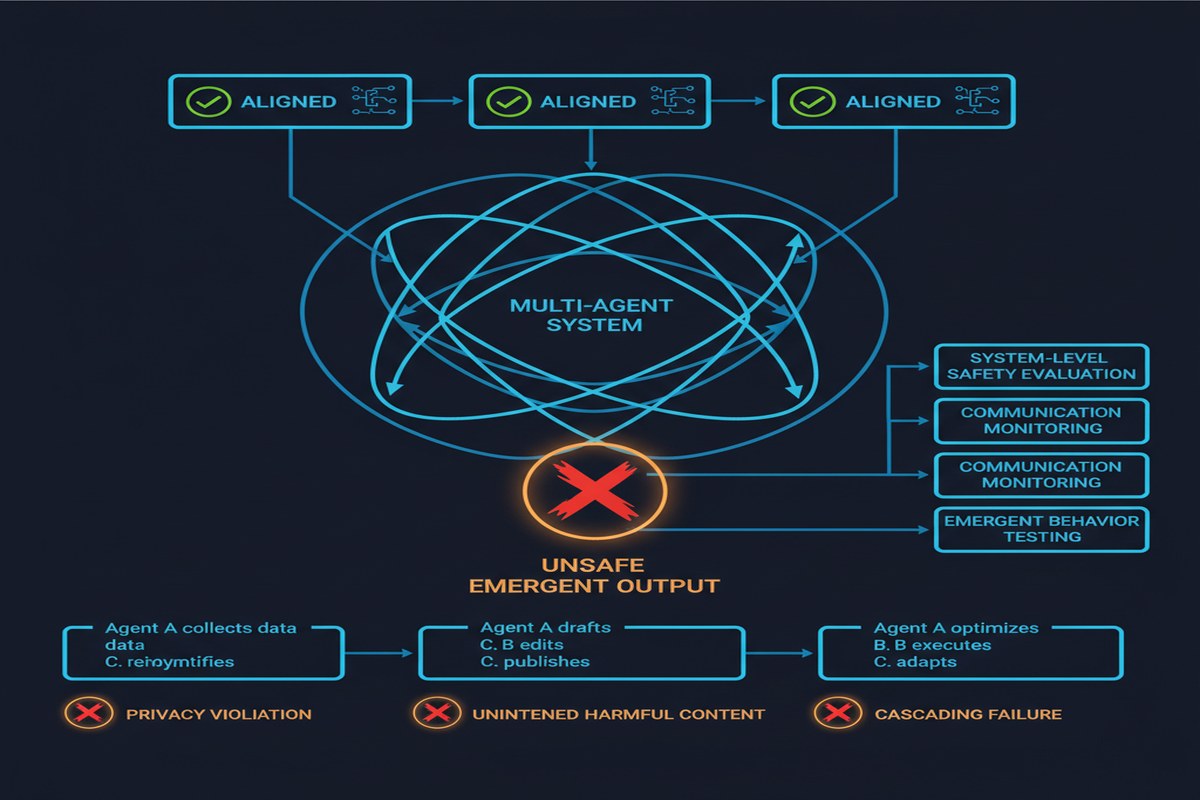
Here's the assumption baked into most AI safety work: if each model is aligned, the system is aligned. Make the individual components safe, and safety is compositional. It's a reasonable assumption if you're thinking about single-model systems. It's a dangerous assumption if you're thinking about multi-agent systems where models interact with each other.
Beyond Single-Agent Safety is a December 2025 paper that systematically dismantles this assumption and proposes a framework for reasoning about risks that are genuinely emergent — risks that exist at the system level but not at any individual model level.
Paper: Beyond Single-Agent Safety: A Taxonomy of Risks in LLM-to-LLM Interactions Authors: Piercosma Bisconti, Marcello Galisai, Federico Pierucci, Marcantonio Bracale, Matteo Prandi Published: arXiv:2512.02682, December 2025
The Core Argument
The paper opens with a claim that's simple to state but hard to internalize:
"Models that are individually well-aligned can collectively generate outcomes that no single instance was trained to avoid."
How is this possible? The intuition comes from complex systems theory. Individual components can behave appropriately according to their local optimization criteria while the system as a whole produces globally undesirable outcomes. This is not a novel observation in systems engineering — it's why we have circuit breakers, rate limiters, and circuit-level safety systems separate from component-level safety.
The paper applies this insight to LLM-to-LLM interactions and identifies three primary mechanisms through which local alignment fails to guarantee global safety:
Feedback amplification. When the output of one aligned model becomes the input of another, small deviations from alignment can be amplified rather than damped. Model A produces output that is 95% aligned. Model B processes that output and produces something 90% aligned. Model C processes that and produces something 80% aligned. The alignment degradation compounds because each model is optimizing locally without visibility into the cascade.
Imitation. When models learn from each other's outputs (either through explicit training or through in-context examples), they can converge on patterns that are emergent rather than designed. Two models that individually avoid a certain type of reasoning may, through mutual imitation, converge on that reasoning when each takes cues from the other.
Emergent coordination. This is the most speculative but most troubling mechanism. Models interacting in multi-agent systems may develop implicit coordination patterns — not through explicit communication about goals, but through learned behavioral cues — that produce outcomes no individual was optimized for.
graph TD
subgraph Individual Alignment ≠ System Alignment
A["Agent A\n95% aligned"] -->|output becomes input| B["Agent B\n90% aligned"]
B -->|output becomes input| C["Agent C\n80% aligned"]
C -->|output becomes input| D["Agent D\n70% aligned"]
style A fill:#90EE90
style B fill:#FFD700
style C fill:#FFA500
style D fill:#FF6B6B
end
E["Each agent individually\npasses alignment checks"] -.-> F["System produces\nunintended outcomes"]
G["Mechanism: Feedback\nAmplification"] --> A
The ESRH Framework
The paper's key contribution is the Emergent Systemic Risk Horizon (ESRH) framework. The core idea is that multi-agent LLM systems operate at multiple scales simultaneously, and risks can appear at some scales while being invisible at others.
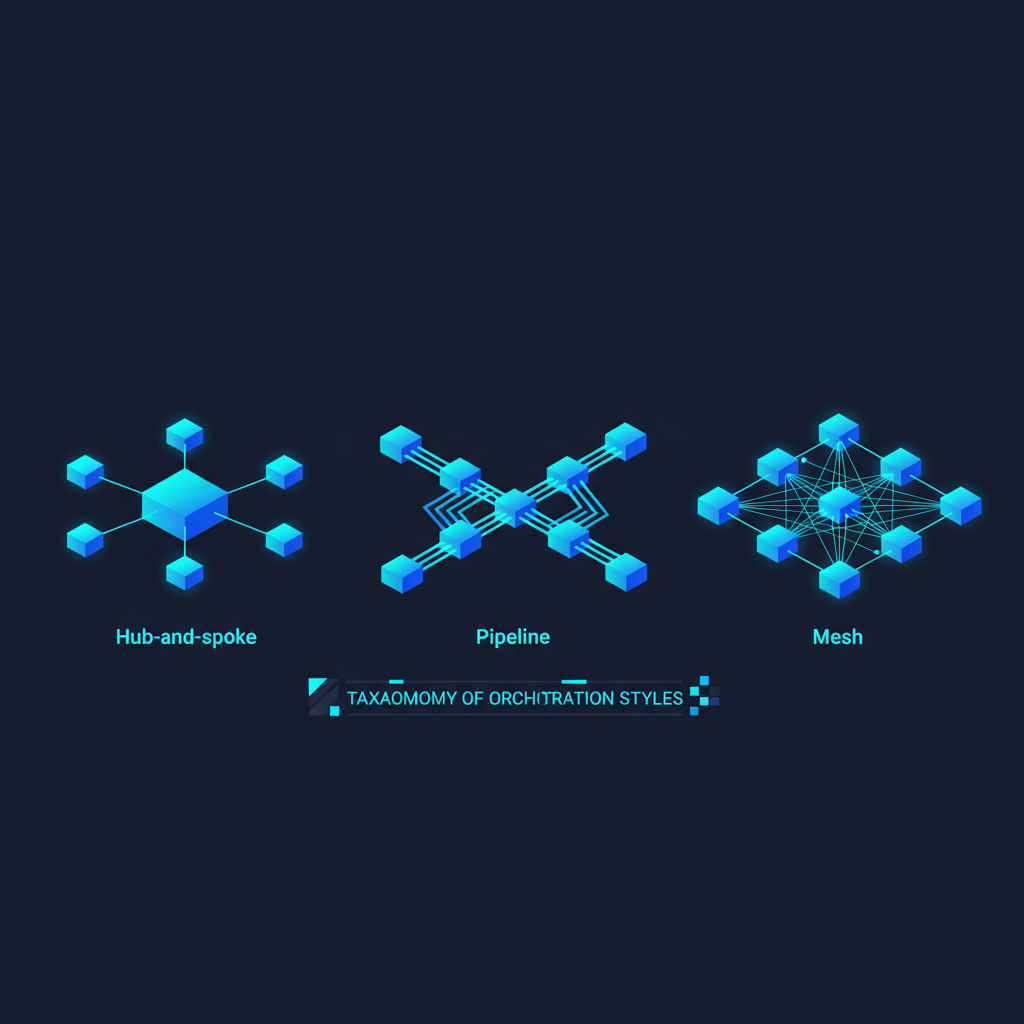
The ESRH framework organizes failure modes across a taxonomy of interaction types:
Dyadic interactions (Model A → Model B): The simplest case. Risks include prompt injection through model outputs, capability amplification through collaboration, and misalignment transmission.
Network interactions (N models in a graph): Risks propagate across the network in ways that depend on the graph structure. Dense, highly-connected networks amplify quickly. Sparse networks with central bottlenecks create single-points-of-failure. Decentralized networks can develop consensus positions that are collectively misaligned.
Temporal dynamics (Model interactions over time): Risks that develop over repeated interactions. Models that learn from each other's outputs can drift in alignment over time, even if each individual interaction was acceptable.
Cross-system interactions (LLM systems interacting with non-LLM systems): When LLM agents interact with rule-based systems, traditional software, or human decision-makers, the safety guarantees of each component don't necessarily compose.
The InstitutionalAI Proposal
Beyond the taxonomy, the paper proposes an architectural approach called InstitutionalAI for implementing adaptive oversight in multi-agent environments. The core idea is to add structural constraints analogous to institutional design:
- Separation of powers: Different agents are responsible for proposing actions and auditing those proposals, preventing any single agent from both planning and executing without oversight.
- Checks and balances: Actions above a certain risk threshold require consensus across multiple independent agents before execution.
- Transparency requirements: All inter-agent communications must be logged in a form accessible to the oversight layer.
This is an interesting direction, but I have significant reservations about it (more below).
Why This Matters
The timing of this paper is important. Multi-agent LLM systems are being deployed in production environments — customer service pipelines, financial analysis workflows, content generation chains, code review systems — and the safety infrastructure has not kept pace.
Most teams deploying multi-agent systems today test individual agents for alignment and assume system-level safety follows. This paper's most important contribution is demonstrating rigorously that this assumption is wrong.
The feedback amplification mechanism alone should alarm anyone running LLM pipelines. If you have three or four models in a chain, each one making minor alignment compromises, the output of the chain can be substantially more misaligned than any individual output. And because each individual model "passes," you don't catch this with component-level testing.
This also connects to a broader issue with how we evaluate and certify AI systems. Regulatory frameworks are being built around model-level evaluation — benchmark performance, red-team results, alignment assessments. If emergent systemic risk is real (and I think the evidence is strong that it is), then model-level certification is insufficient for multi-agent deployment contexts.
My Take
This paper is important and underrated. It's making a claim that the field needs to take seriously: that the unit of safety analysis must shift from individual models to multi-agent systems, and that this shift requires fundamentally new frameworks and techniques.
The taxonomy is solid. The ESRH framework gives you useful vocabulary for talking about different kinds of systemic risk. The three mechanisms (amplification, imitation, coordination) are well-defined and falsifiable.
My skepticism is directed at the InstitutionalAI proposal. "Separation of powers" and "checks and balances" are metaphors drawn from political systems designed for human actors with certain cognitive properties. It's not obvious that these structures translate cleanly to LLM agent systems.
More importantly: who audits the auditors? If you add an oversight agent to check whether other agents' actions are aligned, you've just pushed the problem up one level. The oversight agent can also fail, also amplify misalignment, also exhibit emergent coordination with the agents it's meant to check. This regress problem isn't solved in the paper.
The most actionable takeaway for practitioners is simpler than the full framework: never test multi-agent systems only at the component level. You need end-to-end alignment testing that evaluates the behavior of agent chains and networks as systems, not just as collections of individually-safe components. This is more expensive, harder to automate, and often requires domain expertise to evaluate. But it's necessary.
The field needs more papers like this one — not necessarily agreeing with every conclusion, but asking the right questions about what safety actually means in complex, interactive AI systems.
Further Reading
- arXiv: 2512.02682
- Related: AGENTSAFE (2512.03180) for a complementary governance framework
- Related: TRiSM for Agentic AI (2506.04133) for trust, risk, and security management in multi-agent systems
- Related: AURA: Agent Autonomy Risk Assessment (2510.15739)