The demo always works.
You set up a LangChain pipeline, plug in a few tool calls, point it at a sample Confidential Information Memorandum, and watch a language model summarize the business description, extract the financials, and surface the key investment risks. It works smoothly. Your audience is impressed. You tell them it's production-ready.
Then you hand it to an analyst covering fifty deals simultaneously and it falls apart within a week.
I have watched this failure mode play out three times in the last two years at Snow Mountain AI, where I lead AI development on a platform that processes financial documents and coordinates multi-agent workflows for private equity dealflow operations. The first time we watched a production agent confidently invent a revenue figure that didn't exist in the source document. The second time, two agents deadlocked waiting on each other's outputs for eleven minutes before the orchestration layer timed them out. The third time, a retrieval system that worked perfectly on sample documents started silently degrading as document volume grew past 50,000 pages — and we didn't catch it for three weeks.
None of these failures were exotic. All of them were predictable in retrospect. What makes multi-agent systems for financial applications harder than most enterprise software is not any single difficult problem. It is the combination: you're operating in a domain where hallucination has catastrophic consequences, at a document scale that exposes every architectural assumption you made, with real-time coordination requirements that reveal every timing bug you didn't know you had.
Here's what building this actually looks like.

Why Private Equity Is a Particularly Hard Domain for Multi-Agent AI
Before getting into architecture, it's worth understanding why private equity produces such a difficult AI deployment context — because the domain shapes every design decision.
Private equity dealflow generates massive volumes of highly heterogeneous unstructured documents. A single deal process involves:
- Confidential Information Memoranda (CIMs): 50-150 page documents with inconsistent structure, mixed narrative and financial content, embedded tables that may or may not be machine-readable, and management representations that require cross-referencing against third-party data
- LBO models: Excel workbooks with custom assumptions, non-standard sheet structures, and formulas that encode business logic not explicitly stated anywhere in the text
- Legal documents: Purchase agreements, representations and warranties, disclosure schedules that reference other documents by pointer rather than by content
- Third-party diligence reports: Market research, customer interviews, technical diligence, each with its own format and citation conventions
- Investor communications: LP letters, board deck presentations, portfolio reporting packages
A financial AI system needs to work across all of these simultaneously, understand how they relate to each other, extract and verify specific claims, and surface inconsistencies between sources. The retrieval problem alone — "given this question about portfolio company margins, find the relevant passages across this set of documents" — is considerably harder than it looks.
Two additional constraints that don't exist in most enterprise software domains:
Hallucination is catastrophic, not merely annoying. When an AI assistant in a productivity application gets something wrong, someone corrects it and moves on. When an AI system claims a company's EBITDA margin is 28% when the CIM clearly states 21%, and that claim propagates through a financial model that informs an investment committee presentation, the consequences are material. I have seen financial AI demos where the presenter didn't notice the model had invented a metric. I have worked to build systems that make that failure mode impossible by design — or at least by audit trail.
The document universe is adversarial in a specific way. CIMs are marketing documents. They are written to present businesses in the most favorable light while remaining technically accurate about the disclosed facts. A multi-agent system trained on general text will often take CIM language at face value in ways that an experienced analyst would not. "Adjusted EBITDA" in a CIM is not EBITDA. "Market-leading position" is a claim that requires evidence. Teaching agents to treat financial source documents with calibrated skepticism rather than faithful summarization is an ongoing alignment problem, not a solved one.
The Architecture We Actually Use
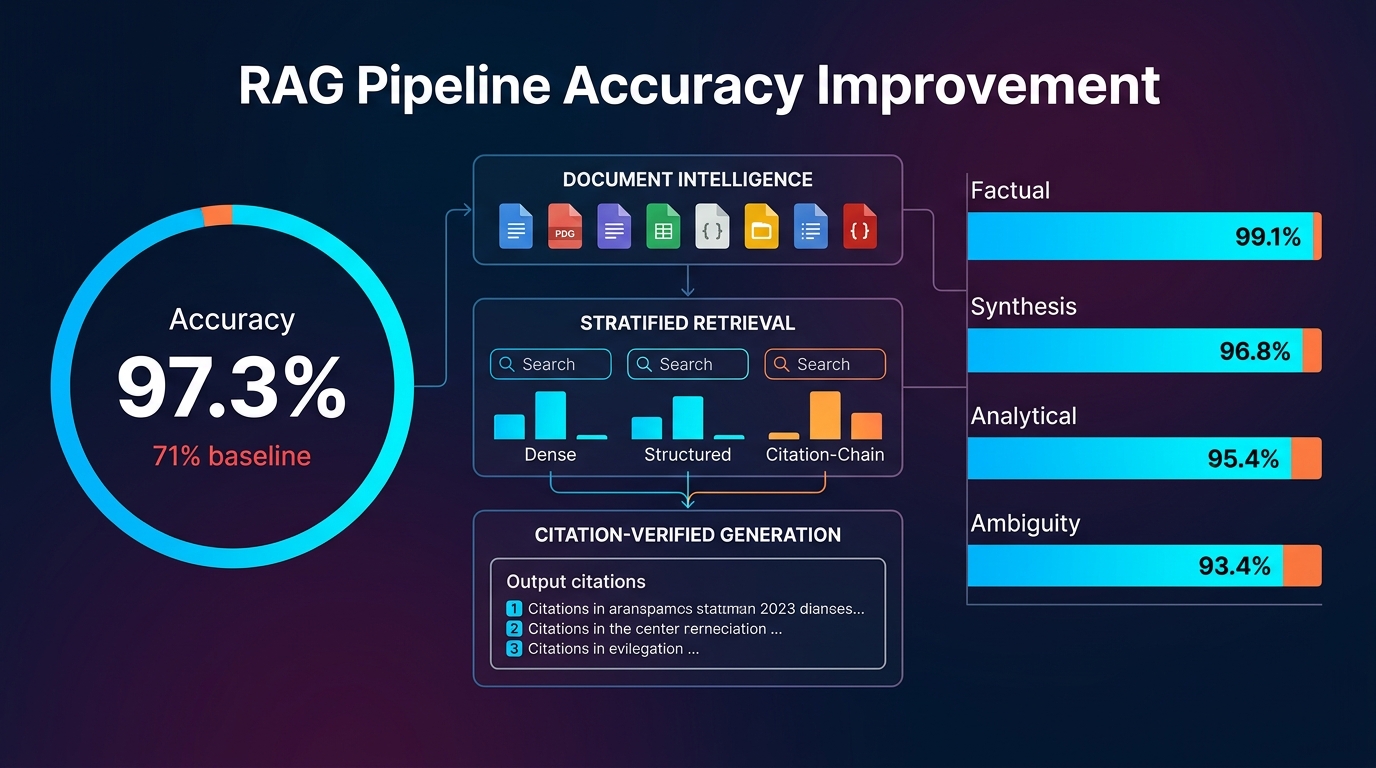
Our current architecture at Snow Mountain AI has three layers: a document intelligence layer, a retrieval layer, and an orchestration layer. They're distinct for a reason — we've refactored the boundaries between them three times as we learned where the coupling creates fragility.
Document intelligence layer. Raw documents enter a processing pipeline that handles format normalization, structure extraction, and chunking before anything involving language models. This is not glamorous work. It is absolutely critical.
PDF parsing in the financial document context is a solved problem in theory and an ongoing problem in practice. CIMs are often exported from PowerPoint, which means text extraction requires handling text boxes, embedded images with text that needs OCR, and tables with merge cells that flattened-text parsers represent incorrectly. We use a custom pipeline that routes documents through different parsers based on detected document structure, applies confidence scoring to extracted tables, and flags content for human review when extraction quality falls below threshold.
Chunking strategy for financial documents is different from general-purpose RAG chunking. Fixed-size character or token chunks destroy financial tables and create chunks that are semantically misleading — a chunk that ends in the middle of a revenue breakdown looks different to an embedding model than the same content with its full context. We use hierarchical chunking: documents are first segmented by detected semantic structure (section headers, table boundaries, figure captions), and only then divided into retrieval-unit chunks that respect semantic boundaries. Each chunk carries metadata about its document source, section hierarchy position, and detected content type (narrative, table, exhibit, footnote).
Retrieval layer. The retrieval layer implements what I'd describe as stratified retrieval rather than naive nearest-neighbor search. A question about "revenue growth" in deal X needs to retrieve:
- Relevant passages where revenue figures appear explicitly
- Table rows that contain the specific numerical data
- Management commentary on revenue performance
- Any third-party market sizing or revenue benchmarks from separate documents
These four retrieval tasks are different problems. Semantic similarity search retrieves the first and third well. The second requires hybrid retrieval that can match structured numerical content. The fourth may require searching a separate document corpus with different indexing parameters.
We run multiple specialized retrievers in parallel and use a re-ranking model to merge results before passing context to a language model. The re-ranker was not in our initial architecture. We added it after we identified a systematic failure mode where the most semantically similar chunk was frequently not the most relevant one for financial queries — because financial questions are often technically specific in ways that don't map cleanly to semantic distance in the embedding space.
Query routing is the piece that took the longest to get right. An analyst's question — "what's driving gross margin compression in the portfolio company's manufacturing segment?" — needs to be decomposed into sub-queries, routed to appropriate retrievers, and reassembled into a coherent context window before a language model touches it. Getting that decomposition right requires a routing model that understands financial query structure, which in turn required a labeled dataset of financial questions with their optimal retrieval strategies. We built that dataset from analyst interaction logs over the first six months of production use. The routing model trained on it is now one of the highest-leverage components in the system.
Orchestration layer. This is where the multi-agent architecture becomes visible to users, and where most of the interesting engineering problems live.
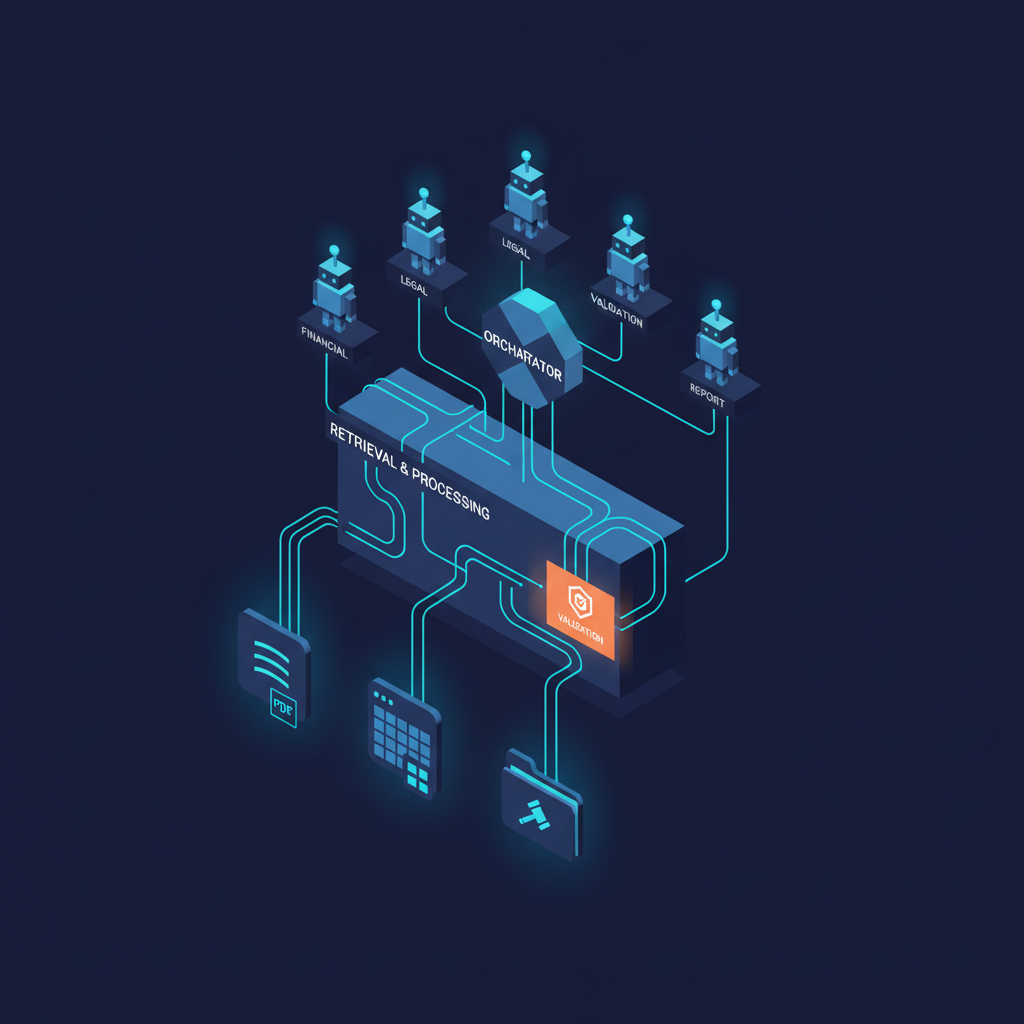
We use a hierarchical orchestrator pattern. A primary orchestrator agent receives high-level tasks ("prepare a deal summary for the investment committee on Acme Manufacturing"), decomposes them into subtasks, assigns subtasks to specialized sub-agents, monitors execution, and synthesizes outputs. Sub-agents include:
- A financial extraction agent that specializes in numerical data from CIMs and models
- A legal risk agent that reviews legal documents for standard risk flags and non-standard representations
- A market context agent that retrieves and synthesizes competitive positioning information
- A consistency validation agent that cross-checks claims across multiple sources
- A report generation agent that assembles synthesized content into structured output formats
This decomposition is not arbitrary. Each agent has a specific prompt template, tool set, and output schema that limits what it can do and what it can claim. The financial extraction agent's output schema requires source citation for every numerical claim — no citation, no output. This is a hard constraint, not a soft instruction.
Coordination Patterns and Where They Break
The two coordination patterns that emerge in financial AI orchestration are sequential pipelines and parallel fan-out, and both have failure modes that only appear at production scale.
Sequential pipelines are appropriate when each step depends materially on the output of the previous one. Due diligence orchestration is often naturally sequential: you extract the business description before you search for relevant market data, because you need to know what market to search for. Sequential pipelines are easy to reason about and easy to debug — when something goes wrong, you can inspect the intermediate outputs and identify exactly where the chain broke.
The failure mode in sequential pipelines is error propagation. If the financial extraction agent misidentifies a revenue figure in step two, every downstream agent that references that figure inherits the error. In long chains, errors compound. We addressed this through checkpoint validation — a lightweight validation agent that checks output schemas and confidence signals between sequential steps, and halts execution and escalates to human review when it detects anomalies. Checkpoint validation adds latency. It also prevents about 15% of analyst reviews from being based on bad upstream data, which we know from our incident logs.
Parallel fan-out is appropriate when subtasks are genuinely independent. Extracting financial metrics from a CIM and reviewing the legal disclosure schedule can happen simultaneously — neither output depends on the other. Parallel fan-out reduces end-to-end latency dramatically for complex tasks.
The failure modes in parallel fan-out are concurrency bugs and context contamination. Concurrency bugs are the obvious problem: agents that share state (like a document cache or a session context object) can produce non-deterministic behavior when run in parallel. We learned to treat agent state as strictly immutable during execution and pass data through explicit message structures rather than shared objects. This discipline was not in our initial design. We added it after our second major production incident.
Context contamination is subtler. When two parallel agents both retrieve from the same document corpus, their retrieval results can overlap in ways that confuse the synthesizing agent downstream. If the financial extraction agent and the consistency validation agent both retrieve the same passage about EBITDA margins — and retrieve it slightly differently because of non-deterministic retrieval ordering — the synthesizing agent may be presented with what appears to be two different sources making the same claim, when it's actually the same source twice. We handle this with deduplication and source provenance tracking in the synthesis step, but it took us a while to identify the failure mode precisely because the symptoms looked like model hallucination rather than retrieval collision.
What RAG for Financial Documents Actually Requires
The Retrieval-Augmented Generation literature has produced excellent techniques for question-answering over general document collections. Financial documents require several adaptations that are either underemphasized or absent from the standard literature.
Table retrieval is a first-class problem. Financial documents are dense with tables. Income statements, EBITDA bridges, segment breakdowns, headcount by function — all of these encode critical information in tabular format. Standard text-chunk-based RAG simply does not handle this well. A chunk containing a partial table is semantically malformed. A chunk containing a table with no surrounding narrative context is uninterpretable without the section header and column labels.
We represent tables as structured objects in our vector store, not as text chunks. Each table is indexed with its header structure, the columns and row labels, and any narrative context from the surrounding section. Queries that require numerical extraction go to a hybrid retriever that combines semantic similarity for table headers with exact-match lookup for cell values. This required custom indexing code. It is not available as a plug-and-play feature in any retrieval framework I know of.
Financial terminology disambiguation. The same term means different things in different document types. "Revenue" in a CIM management discussion is different from "revenue" in an LBO model assumptions sheet, which is different from "total revenue" in an audited financial statement. Naively treating these as equivalent in a retrieval index produces confusing results when a query retrieves all three.
We maintain a domain-specific financial ontology that maps surface terms to their semantic types, and apply it during indexing to annotate chunks with their intended financial concept. Queries are expanded against this ontology before retrieval. The ontology has about 2,000 term entries and is updated quarterly as we encounter new document types. Maintaining it is operational overhead that few ML architecture articles discuss. It is one of the most valuable things in our system.
Temporal context matters in financial retrieval. A question about "current margins" means something different against a CIM from 2023 versus an LP update letter from Q4 2025. Documents in a deal corpus span different time periods and may contain contradictory claims that are both true at different points in time. We tag every document chunk with its document date and document type, and temporal context is treated as a first-class filter in every retrieval query. When temporal context is ambiguous or when multiple documents from different dates address the same topic, the retrieval results are explicitly flagged as temporally heterogeneous before the language model sees them.
What Breaks at Scale
At 10 documents and 5 agents, a multi-agent system for financial analysis can be built in a week and it will work. At 50,000 documents and 20 concurrent orchestration workflows, everything you assumed about the system becomes a hypothesis that the production environment will test.
The three things that break most predictably:
Retrieval quality degrades with scale in non-linear ways. At small document volumes, your embedding model's vector space is sparsely populated and retrieval is relatively precise. As you add documents — and financial document collections grow fast once you're processing live dealflow — the vector space becomes dense and ambiguous. Queries that returned precise, relevant results at 5,000 documents return noisy, plausible-but-wrong results at 50,000 documents, because the nearest-neighbor geometry changes with corpus size.
The solution is not a better embedding model (though that helps at the margins). The solution is architectural: finer-grained retrieval with more aggressive filtering, re-ranking that is calibrated on your specific document distribution, and ongoing evaluation against a labeled test set of queries that you run against production retrieval whenever you update any component of the retrieval pipeline. We run a weekly retrieval evaluation. The metrics dashboard goes to me every Monday. This is not optional.
Agent coordination latency accumulates. A sequential pipeline with six agents, each taking 8-12 seconds for a retrieval-and-generation step, produces a 60-75 second end-to-end latency for a complex task. That's marginal for a one-off deal summary. It's unacceptable when analysts are running 20 parallel deal reviews and expect sub-30-second responses for standard queries. Reducing coordination latency required moving from sequential pipelines to parallel fan-out wherever task dependencies permitted, aggressive caching of retrieval results across agent invocations within the same session, and accepting that some real-time tasks need to be restructured as asynchronous workflows with push notification rather than synchronous queries with waiting users.
LLM APIs are not infinitely reliable at production throughput. Third-party API rate limits, intermittent latency spikes, and the occasional service degradation produce failure modes that look identical to agent bugs when they first appear. We built retry logic and graceful degradation from day one. We also built observability into the orchestration layer from day one — every agent call is logged with timing, token counts, model version, and output hash. When something goes wrong in production, we need to distinguish "agent logic failure" from "retrieval failure" from "API failure" within minutes, not hours.
The Human-in-the-Loop Question
Every enterprise multi-agent deployment eventually forces an answer to the question: at what points in the workflow does a human need to be present?
The answer for financial AI is not "everywhere" (which makes the system useless) and not "nowhere" (which makes the system dangerous). It is at the points where:
- The orchestrator's confidence in its output falls below a domain-specific threshold
- Detected inconsistencies across sources have not been resolved by the consistency validation agent
- The requested task falls outside the defined scope of any available sub-agent
- The output will be used to support an investment decision above a certain materiality threshold
We define these thresholds explicitly in the orchestration layer's configuration, and we review them quarterly against our incident log. The materiality threshold — above which human review is required regardless of model confidence — was the hardest parameter to set. We erred toward conservatism and have gradually relaxed it as we accumulated evidence about where the system performs reliably and where it doesn't.
The practical insight: human-in-the-loop design is not just about safety. It's also about building the evidence base that lets you reduce human intervention over time. Every human review that overrides an agent output is a labeled training example. A system designed to capture those corrections and feed them back into the pipeline is a system that gets better as analysts use it. A system that treats human intervention as a failure mode to be minimized is a system that stays stuck.
What I Didn't Expect
Three things surprised me in building this system:
The research foundations in multi-agent coordination from the academic literature transferred less directly to production LLM orchestration than I expected. Academic multi-agent systems have clean interfaces, explicit belief models, and formal communication protocols. LLM agents have none of these things by default — you build approximations of all of them, and the approximations leak. The intuitions from classical agent research are valuable, but the implementation requires rethinking almost everything.
The financial AI work at Snow Mountain AI has fed back into the medical AI work I did at Ai-Bharata in ways I didn't anticipate. RAG for heterogeneous financial documents and RAG for mixed clinical and imaging records have more in common than they appear to — both require structured-unstructured retrieval, both operate in domains where hallucination has severe consequences, both involve documents that are technically accurate and contextually misleading. Domain expertise transfers more than domain knowledge does.
The hardest engineering problem in multi-agent orchestration is not technical. It is getting analysts — experienced professionals who have built their own mental models and workflows over years of practice — to develop accurate intuitions about where the AI system is reliable and where it isn't. This is the same physician trust and calibration problem I encountered in medical AI deployment, in a different domain with different stakes. I described it in a previous post as appropriate reliance, and the framing holds. The goal is not maximum deference to the AI. It is calibrated collaboration, where analysts understand the system's failure modes well enough to catch the errors that matter.
Where This Goes
Enterprise multi-agent systems for financial applications are at roughly the same stage medical AI for diagnostics was in 2019: good enough to deploy, immature enough that most deployments will be limited by factors that have nothing to do with the AI itself.
The retrieval infrastructure will improve significantly over the next 18 months. Models trained specifically on financial documents with domain-appropriate alignment constraints are entering production for the first time. The tooling for evaluation — measuring retrieval quality, agent coordination reliability, and end-to-end accuracy — is maturing from research prototype to something teams can actually use in production.
The coordination patterns will standardize. Right now, every team building multi-agent financial AI is inventing its own orchestration layer, its own checkpoint validation approach, its own concurrency model. That's appropriate for an early market where nobody knows the right answers yet. It's expensive in aggregate, and I expect the next two years to produce a consolidation around a small number of patterns that have been tested at production scale.
Related posts: Multi-Agent Orchestration at Scale — the engineering patterns for scaling multi-agent systems. Multi-Agent Coordination Protocols — coordination patterns for multi-agent systems. AI Agents That Spend Money — AI agent commerce as a multi-agent financial application. Legal AI Agents — legal AI as a domain-specific multi-agent deployment.
What won't get easier is the domain expertise problem. Building a multi-agent system for private equity that a general software engineering team can maintain is harder than building one that financial domain experts can maintain. The gap between "the model says 28% margins" and "that's wrong because management adjustments aren't included in this particular metric in this particular document type" is a gap that requires someone in the loop who knows the domain. The system can automate the extraction. It cannot automate the judgment.
That tension — between automation ambition and domain complexity — is where the interesting work lives for the next several years. I'll keep building on both sides of it from my work at Snow Mountain AI, and expect that the tools and patterns we're developing will eventually be valuable well beyond private equity.
The demo will keep working. The hard part is everything after.
Dr. Vinayaka Jyothi is a hardware security researcher, AI engineer, and entrepreneur. He is Head of AI at Snow Mountain AI, building multi-agent orchestration platforms and financial AI systems, and was Founder and CTO of Ai-Bharata, a medical imaging AI company that deployed across 270+ healthcare institutions in India. He holds a Ph.D. in Electrical Engineering from NYU Tandon School of Engineering with 502 citations and an h-index of 12, and holds eleven patents in hardware trust and AI systems. The open-source MedicalAI framework he developed has been downloaded over 45,000 times on PyPI.