A customer service system has 5 specialized agents. Each handles a category: billing, technical support, orders, general inquiries, and escalation. They share a knowledge base, route between each other, and escalate to humans. The system works well.
Now the company expands. Each agent now has 3 tool integrations. New agents get added every quarter. Traffic varies by 10x between peak and off-peak. Some agents need GPU compute, others need databases, others need real-time APIs. An agent fails, and its tasks must be redistributed. Logs from 5 agents are manageable; logs from 50 are chaos.
This is multi-agent orchestration at scale. And it's where agentic engineering becomes systems engineering.
The Orchestration vs. Choreography Spectrum
Before scaling, decide on the coordination model:
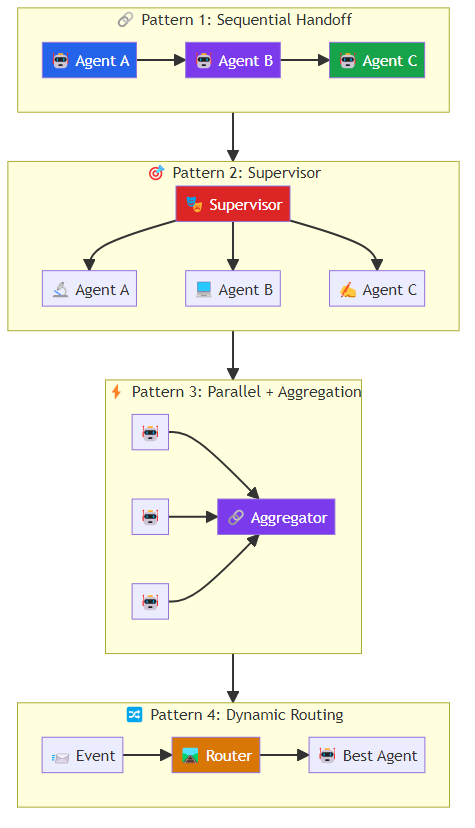
Orchestration: a central coordinator directs all agent activity. Tasks are assigned, results are collected, and flow is managed centrally.
Choreography: agents coordinate autonomously through events and messages. Each agent reacts to events and publishes results that other agents consume. No central controller.
Most production systems use hybrid: a lightweight orchestrator assigns work and handles cross-cutting concerns (routing, monitoring, security), while agents handle intra-task coordination autonomously.
Orchestration (for coordination):
- Task assignment and routing
- Cross-agent routing decisions
- Resource allocation and capacity management
- Security and access control
- Observability and audit
Choreography (for execution):
- Intra-task agent communication
- Tool-to-tool data flow
- Local failure recovery
- Peer-to-peer handoffs
The Orchestration Layer
The orchestration layer handles the cross-cutting concerns that individual agents shouldn't manage:
Task Distribution and Routing
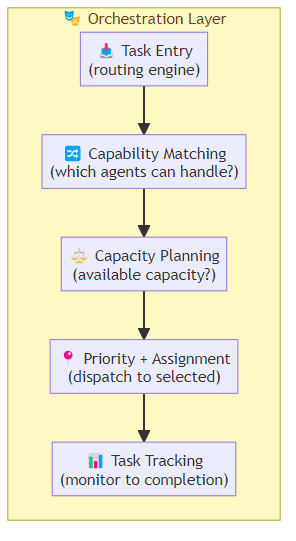
The orchestrator receives tasks and routes them to the appropriate agent(s):
Task arrives → Routing Engine
→ Agent capability matching (which agents can handle this task type?)
→ Capacity check (which agents have available capacity?)
→ Priority evaluation (urgent tasks take precedence)
→ Assignment (dispatch to selected agent(s))
→ Tracking (monitor progress until completion)
Routing strategies:
- Static routing: map task types to agent capabilities (simple, predictable)
- Dynamic routing: use a classifier or learned model to route based on task content
- Load-based routing: route to least-busy agent with required capability
- Cost-based routing: route to cheapest agent that meets quality requirements
Resource Allocation
Agents consume resources: compute, memory, API calls, tokens. The orchestrator must allocate these efficiently:
Resource pool management:
- Per-agent resource quotas (prevent one agent from starving others)
- Dynamic reallocation (scale resources based on demand)
- Priority-based allocation (high-priority tasks get reserved capacity)
- Preemption (pause lower-priority work when higher-priority arrives)
Capacity planning for multi-agent systems:
- Estimate peak concurrent agents needed
- Model resource consumption per agent type (LLM-heavy vs. tool-heavy vs. data-heavy)
- Add 30-50% buffer for burst traffic
- Design for graceful degradation (which agents to scale first under pressure)
Fault Tolerance and Recovery
When an agent fails, the orchestrator must handle recovery:
Agent failure detected:
1. Isolate the failed agent (stop routing new tasks)
2. Identify affected tasks (in-progress tasks assigned to failed agent)
3. Retry strategy (re-assign to same-agent-type, different instance)
4. Fallback strategy (route to fallback agent, or human escalation)
5. Quarantine failed agent (for investigation before return to service)
Circuit breaker pattern: if an agent's error rate exceeds threshold, stop routing to it temporarily. This prevents cascading failures from spreading.
Cross-Agent Communication
When one agent needs results from another:
Direct messaging: agent A sends a message to agent B via the orchestrator's message bus. Guaranteed delivery, acknowledgments, retries.
Shared state: agents write to and read from shared data stores. Eventual consistency, simpler but requires careful conflict resolution.
Fan-out patterns: one agent's output feeds into multiple downstream agents. The orchestrator manages the fan-out coordination.
Scaling Patterns
Horizontal Scaling (More Instances)
Run multiple instances of the same agent type. The orchestrator routes traffic across instances based on availability:
Agent Type: billing_agent
Instance 1 (us-east-1): available
Instance 2 (us-east-1): available
Instance 3 (eu-west-1): available
→ Route to least-loaded available instance
Stateful agents require sticky routing (same user/session → same instance) to maintain session continuity. Stateless agents can be routed arbitrarily.
Vertical Scaling (Bigger Instances)
Some agents need more resources. GPU-heavy agents (for real-time inference) need GPU instances. Memory-heavy agents (for large context) need high-memory instances. The orchestrator must route to the right instance type.
Multi-Region Deployment
For global deployments, run agents in multiple regions. Route to the nearest available agent to minimize latency. Handle region failures by redirecting to backup regions.
Observability at Scale
Multi-agent observability requires aggregation and correlation:
Distributed tracing across agents: trace context propagates through every agent involved in a task. The full execution tree is visible in a single trace.
Aggregated metrics: metrics from all agent instances roll up into aggregate views. Per-agent, per-type, per-region, per-customer — whatever slices matter for operations.
Anomaly detection at system level: detect failures that only appear at scale: cascade patterns (one agent failure causing others), oscillation patterns (tasks ping-ponging between agents), resource contention (agents competing for shared resources).
Log aggregation and search: with 50+ agents producing logs, centralized logging with structured search is essential. Index by session ID, task type, agent name, time range.
The Bottom Line
Multi-agent orchestration at scale is systems engineering applied to AI agents. The patterns are known from distributed systems — orchestration vs. choreography, fault tolerance, resource allocation, observability — but the implementation must account for what makes agents different: probabilistic behavior, LLM unpredictability, tool call complexity, and context management.
Build the orchestration layer with the same rigor you apply to the agents themselves. Define routing strategies, capacity models, failure recovery procedures, and observability requirements before you scale.
The agents that scale are the ones with an orchestrator designed for scale.
Related posts: Multi-Agent Coordination Protocols — coordination patterns for multi-agent systems. Scaling AI Agents — scaling architecture from POC to production. AI Agents in Production — the engineering practices for production deployment.