A customer service agent pilot achieved 40% automation rate and 4.2/5 satisfaction score. The team wants to expand. The CFO wants to roll out to all channels by Q3. Legal has 14 open questions about liability. IT is concerned about infrastructure capacity. And the AI team is already dealing with edge cases the pilot never surfaced.
This is the enterprise deployment problem. It's not an AI problem — it's a change management, governance, and operations problem that AI enables but doesn't solve.
The Pilot-to-Production Gap
Pilots succeed in controlled conditions. Limited user population, human oversight on every decision, small scale, enthusiastic early adopters, and high attention from the AI team. Production exposes everything pilots hide:
Scale reveals failure modes: a pilot handling 50 conversations/day encounters different failure patterns than one handling 50,000. Rare edge cases become frequent. Latent bugs become visible. The agent's behavior under load is different from its behavior in a sandbox.
User diversity breaks assumptions: pilot users are often power users or enthusiasts who adapt to the agent's quirks. Production users are everyone — from tech-phobic customers to adversarial actors. The agent must handle the full distribution.
Governance requirements emerge: pilots operate under informal oversight. Production requires formal governance frameworks: who is accountable for agent decisions, what audit trails are required, how are failures escalated, what compliance obligations apply.
Operational model needs redesign: pilot success doesn't transfer to production if the operational model (monitoring, maintenance, improvement cycles) isn't designed for scale.
Building the Governance Framework
Enterprise AI governance for agents has four components that must be designed together:
1. Accountability Structure
Define who is accountable for agent decisions at every level:
Executive: accountable for agent program ROI, risk posture, and strategic alignment
→ Sets acceptable risk thresholds, approves expansion scope
Product Owner: accountable for agent behavior quality and user outcomes
→ Defines success criteria, owns improvement roadmap, approves capability changes
AI/ML Team: accountable for technical implementation and safety
→ Designs the agent, implements guardrails, monitors performance, handles incidents
Operations: accountable for agent availability and operational health
→ Manages uptime, handles escalations, coordinates with IT
Legal/Compliance: accountable for regulatory compliance and liability
→ Reviews capabilities for compliance risk, defines audit requirements
Accountability must be explicit and documented before deployment. When something goes wrong, you need to know who decides what happens next.
2. Audit and Traceability Requirements
Regulated industries (finance, healthcare, legal) require audit trails for agent decisions. The infrastructure must support:
Decision logging: every agent decision (action taken, reasoning, context, tools used) logged with timestamp and session ID. Immutable, searchable, retained per compliance requirements.
Human review capability: the ability to reconstruct any session from the logs. Not just what the agent did, but what it knew when it did it.
Compliance reporting: automated generation of reports for regulatory review. What decisions were made, by what authority, with what outcome.
For non-regulated industries, audit requirements are lighter but still valuable: debugging support, customer dispute resolution, and continuous improvement analysis all benefit from session replay capability.
3. Risk Classification and Approval Workflow
Not all agent capabilities carry the same risk. Classify by potential impact:
Class A — Low Risk (auto-deploy eligible):
- Read-only information lookup
- Non-critical recommendations
- Routine formatting and summarization
Class B — Medium Risk (review required):
- Customer communication generation
- Non-financial transactions
- Personalized recommendations
Class C — High Risk (explicit approval required):
- Financial transactions or commitments
- External communications (emails, messages)
- Decisions affecting user accounts or access
- Actions with irreversible consequences
Class D — Restricted (policy review required):
- Decisions affecting regulated activities
- Access to sensitive personal data beyond use case
- Cross-system integrations with external dependencies
Each class has different approval requirements, monitoring intensity, and fallback protocols.
4. Incident Response and Rollback Procedures
When an agent fails in production, the response must be fast and coordinated:
Incident levels:
- P1: Agent causing harm (sending wrong emails, incorrect decisions with financial impact). Immediate rollback, full incident review.
- P2: Agent degraded (error rate spike, latency spike, availability issues). Reduced mode activation, monitoring intensification.
- P3: Agent anomalous (behavior drift, unusual patterns, elevated escalation rate). Investigation mode, enhanced monitoring.
Rollback procedures: pre-documented, tested, rehearsed. When a rollback is needed, the team shouldn't be figuring out how while users are affected.
The Organizational Change Dimension
Deploying agents changes organizational dynamics. Anticipate and manage:
Role evolution: agents augment rather than replace human work. Customer service agents become escalation handlers and quality reviewers. Analysts become insight curators and context providers. The work changes, it doesn't disappear.
Trust building: users need to trust the agent enough to use it, but not so much that they stop supervising it. Calibrated trust — confidence that matches actual reliability — is the goal.
Change resistance: teams that feel threatened by agent capabilities will find ways to work around them. Involve affected teams early, communicate transparently about what changes and why, and create paths for people to add value in the new model.
Skill development: agents require new skills to operate and improve. Prompt engineering, agent monitoring, failure analysis, and improvement iteration are new competencies that need training and practice.
Operational Model for Scale
Production agents require operational infrastructure that pilots don't need:
Monitoring: real-time dashboards for availability, quality, cost, and safety. Alert thresholds set for all key metrics. On-call rotation for incident response.
Maintenance: agent improvement is continuous. Bug fixes, prompt updates, tool additions, capability expansions — all require testing and deployment infrastructure.
Performance review: weekly analysis of agent performance metrics. What worked, what didn't, what changed, what needs attention. This feeds the continuous improvement cycle.
Capacity planning: agent usage grows. Infrastructure must scale. Cost grows with usage. Plan capacity before it's a crisis.
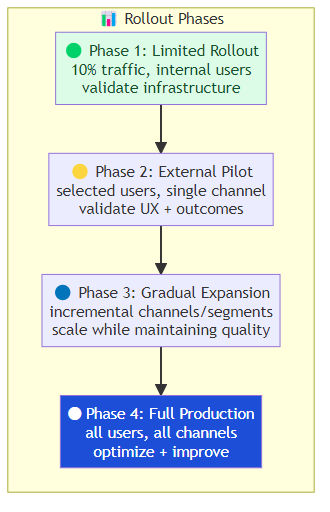
The Rollout Sequence
Don't deploy everywhere at once. Use a phased rollout with explicit success criteria at each phase:
Phase 1 — Limited rollout (10% of traffic, internal users):
Goal: validate infrastructure, test operational processes, find edge cases
Duration: 2-4 weeks
Success criteria: <1% P1 incidents, monitoring operational, team confident
Phase 2 — External pilot (selected external users, single channel):
Goal: validate user experience, measure actual business outcomes, build trust
Duration: 4-8 weeks
Success criteria: user satisfaction maintained, automation rate met, escalation acceptable
Phase 3 — Gradual expansion (incremental channels and user segments):
Goal: scale to full coverage while maintaining quality
Duration: 3-6 months
Success criteria: quality metrics stable across segments, cost per task decreasing
Phase 4 — Full production (all users, all channels):
Goal: optimize efficiency and continuous improvement
Duration: ongoing
Success criteria: ROI positive, team efficiency improved, quality continuous
The Bottom Line
Enterprise agent deployment is a change management project with an AI component, not an AI project with organizational side effects. Build the governance framework before deployment. Define accountability explicitly. Design the operational model for scale. Roll out in phases with explicit success criteria.
The teams that succeed with enterprise agent deployment don't start with the technology — they start with the organizational readiness. Then they deploy the agent.
Related posts: AI Agents in Production — the engineering practices for production deployment. Enterprise AI Agent ROI — the business case for enterprise agentic adoption. Human-in-the-Loop Agents — oversight frameworks for enterprise deployment.


