The first version of our financial RAG system at Snow Mountain AI hit 71% accuracy on our evaluation set.
We shipped it anyway, with human review requirements for every output. At 71%, the system was fast enough to pre-populate analyst workflows and slow enough, in the failure mode sense, that everything it produced needed checking. Useful, but not transformative.
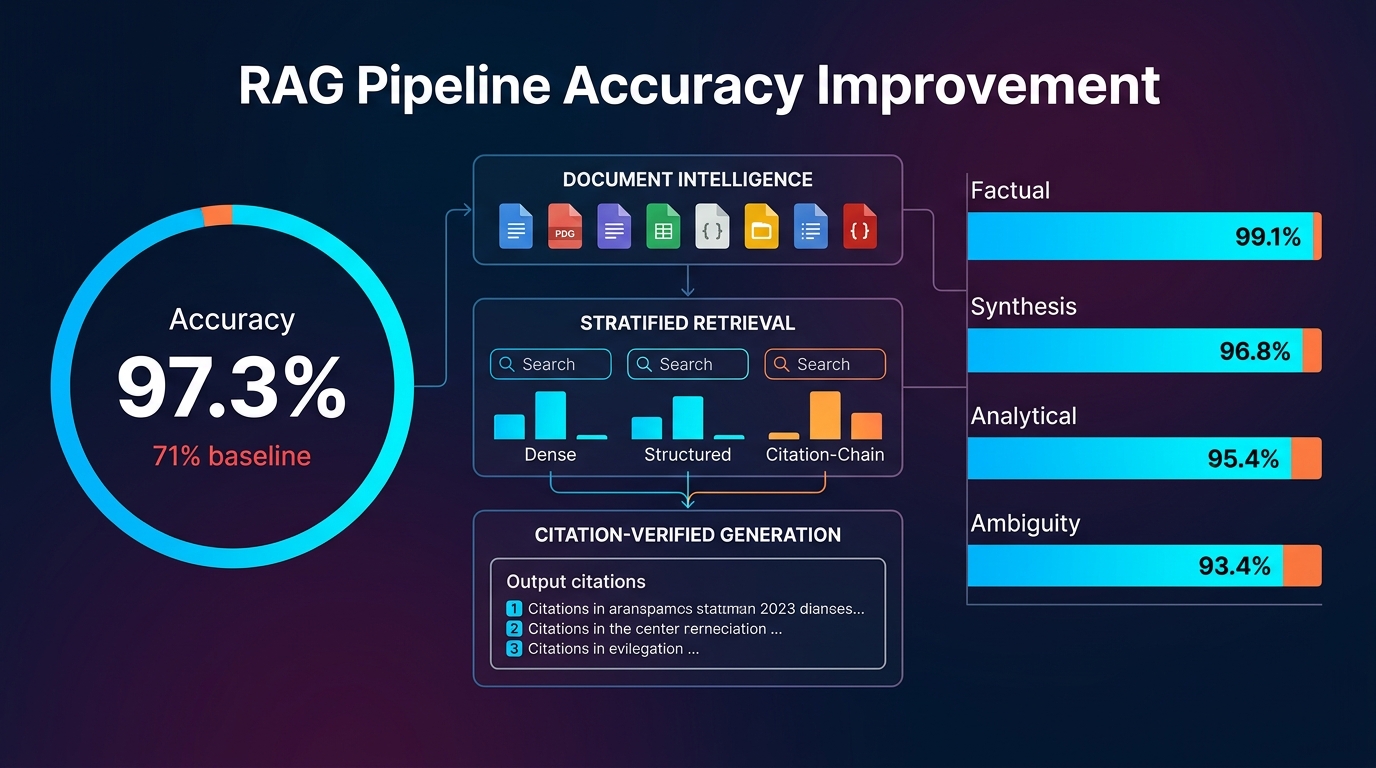
The path from 71% to 97.3% — the accuracy we achieved on complex financial queries across a corpus of 1,000+ documents — took eighteen months, three architectural rewrites, and a series of failure mode analyses that forced us to stop treating RAG as a unified problem and start treating it as a stack of interacting problems, each requiring its own solution.
Here's what that path looked like, and why almost every general-purpose RAG pattern we started with needed to be replaced or substantially modified for financial documents.

Why Financial RAG Is Not Like RAG on Generic Documents
The tutorials that explain RAG — chunk your documents, embed the chunks, retrieve by similarity, inject into the prompt, generate — describe a workflow that works reasonably well on Wikipedia extracts, technical documentation, and FAQ databases. Apply that workflow unchanged to financial documents and you'll get a system that produces confident-sounding answers with accuracy in the 60-75% range, depending on how you measure. That accuracy profile looks fine on demos and fails badly on production usage.
Understanding why requires understanding what financial documents actually are.
Confidential Information Memoranda (CIMs) are 50-150 page marketing documents structured to highlight strengths and technically-accurately-but-charitably represent the business being sold. They contain narrative sections, financial exhibits, and management representations that need to be cross-referenced against each other. The financial statements in a CIM are typically unaudited management accounts. The same metric — "Adjusted EBITDA" — can mean completely different things between two CIMs in the same industry, with the differences buried in footnotes. Generic RAG treats text as text. A CIM requires reading each section in the context of its genre conventions.
LBO models are Excel workbooks where the most important information — the assumptions that drive the returns analysis — is often not written anywhere in English. The model structure encodes business logic. Cells reference other cells. Sensitivities are in tabs that aren't labeled in any obvious way. Extracting meaning from an LBO model requires understanding how the model is structured before you can identify what questions it can answer.
Legal documents — purchase agreements, representations and warranties, disclosure schedules — use defined terms that control interpretation of entire sections. A disclosure schedule reference without the definition of the defined term it qualifies is meaningless and potentially misleading. Generic RAG systems routinely retrieve disclosure schedule excerpts and generate interpretations that are confidently wrong because the relevant definition wasn't in the retrieved chunks.
Third-party diligence reports have their own internal logic: management interviews that need to be weighted differently from primary data, claims that are "management representations" versus "verified findings," market sizing assertions that may have sourcing footnotes that contradict the headline number. These distinctions matter enormously for investment decisions and are completely lost in a naive chunking approach.
The shared pattern across all of these: financial documents have structure that encodes meaning beyond what's in the text content. A RAG system that treats them as bags of words — even sophisticated semantic bags via dense embeddings — is throwing away essential context.
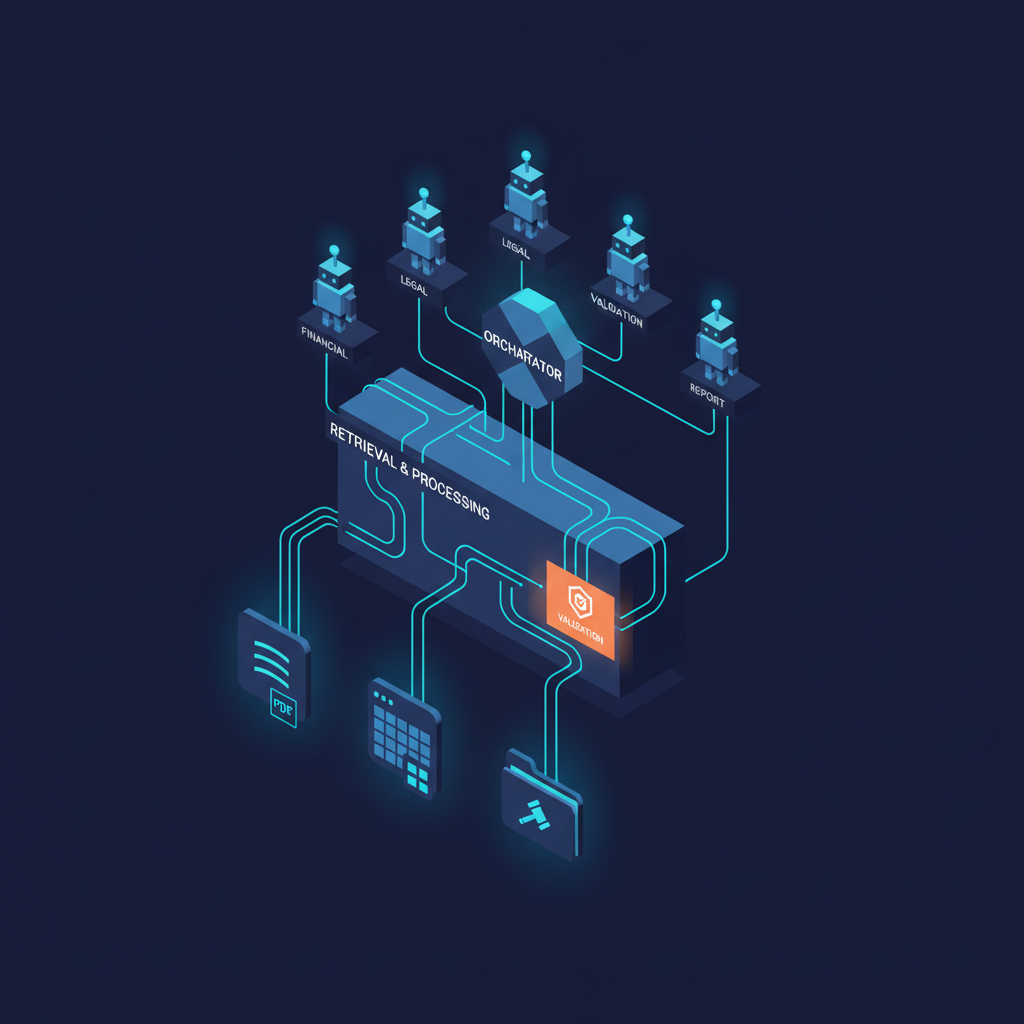
The Architecture We Actually Use
After significant iteration, our Snow Mountain AI RAG architecture for financial documents has three components that look conventional in their names but are substantially different in their implementation from generic RAG patterns.
Layer 1: Document Intelligence (Where Most Systems Fail)
The most important insight from our architectural journey: the accuracy ceiling of your RAG system is determined almost entirely by the quality of your document processing pipeline. You cannot retrieve accurately what you have not represented accurately.
We process incoming documents through a routing-and-enrichment pipeline before any vector database interaction:
Format detection and routing. Different document types require different processing approaches. PDFs exported from PowerPoint (common for CIMs) have text boxes, embedded images with text that needs OCR, and tables that flattened text parsers represent incorrectly. PDFs generated from Word documents have better text extraction characteristics but still require careful table parsing. We classify document types on ingestion and route them to appropriate parsing pipelines. Using one parser for all PDF inputs is one of the most common and most consequential RAG mistakes.
Table extraction with structure preservation. Financial tables are primary data, not decorative. A table showing quarterly revenue by segment across three years contains information that is not recoverable from flattened text — the column headers, row labels, and cell relationships encode the meaning. We use a custom table extraction pipeline that produces structured representations (JSON objects with explicit header-cell relationships) rather than flattened text strings. These structured representations are stored separately from the narrative text chunks and retrieved through a different pathway.
Semantic section classification. We classify document sections by their function — "management representation," "historical financial exhibit," "market analysis," "legal disclosure" — because the same words have different epistemic status depending on section type. A revenue claim in an audited financial statement and a revenue claim in a management case section of a CIM are not equivalent, and a system that treats them equivalently will produce systematically overconfident outputs. Section classification labels are attached to every chunk as metadata and used in retrieval scoring.
Cross-document entity normalization. When multiple documents reference the same company, metric, or time period, we normalize those references to a canonical entity identifier. This sounds straightforward and is technically complex. "EBITDA," "Adjusted EBITDA," "Management EBITDA," and "Company-Defined Adjusted EBITDA" are four different things that a normalized representation needs to track separately. We maintain a per-deal ontology that maps document-specific terminology to canonical entity representations.
Layer 2: Retrieval (Where Most Systems Are Overconfident)
Generic RAG retrieval works by embedding a query and finding the nearest chunks in embedding space. This approach has a systematic failure mode on financial documents: it retrieves thematically relevant chunks that don't actually contain the information needed to answer the query.
Ask "what is the company's EBITDA margin for fiscal year 2024?" and a naive embedding-based retrieval will confidently surface chunks that discuss EBITDA margin — the discussion sections, the market context sections, the management commentary sections — while potentially missing the financial exhibit that contains the actual numbers.
Our retrieval architecture has three parallel pathways that are combined before context injection:
Dense retrieval (standard semantic similarity) handles conceptual queries where the relevant information might use different terminology than the query. This pathway is important for regulatory and legal queries where the relevant text might use technical defined terms that don't appear in the natural-language question.
Structured data retrieval bypasses the vector database entirely for quantitative queries. When a query is classified as requesting specific financial metrics, we route it directly to our structured data store — the JSON representations of extracted tables — and execute structured lookups that return exact values with their source table context. This is what gets us from 71% to 90%+ on financial metric queries. The key insight: you cannot embed your way to reliable exact number retrieval. Numbers need to be stored and retrieved as numbers.
Citation-chain retrieval handles queries that require understanding document-level relationships: "what does the purchase agreement say about the representations disclosed in the disclosure schedule?" This pathway uses explicit document structure relationships (we track cross-document and intra-document references extracted during processing) rather than semantic similarity.
The three pathways produce independent result sets that are merged by a scoring function that weights results based on query classification, source document type, section classification labels, and retrieval pathway confidence. This ensemble approach consistently outperforms any single pathway alone — and more importantly, it degrades more gracefully on novel query types because the failure modes of each pathway are different.
Layer 3: Generation with Verification
The generation layer is where most of our accuracy improvement came from — not from better prompting, but from building explicit verification steps that separate retrieval quality assessment from answer generation.
Pre-generation retrieval audit. Before generating an answer, we run a classifier that asks: "does the retrieved context actually contain the information needed to answer this query?" If the answer is no — if we've retrieved thematically relevant context but not the specific data requested — we return a structured "insufficient context" response rather than generating an answer. Early in our development, we allowed the model to attempt generation on insufficient context, and it reliably produced confident-sounding wrong answers. Suppressing generation on low-confidence retrieval is the single most important hallucination mitigation intervention we made.
Citation-required generation format. Every generated claim is required to be supported by a specific citation: document name, section, table or paragraph reference, extracted value. This format requirement serves two functions: it forces the model to anchor claims to retrieved context rather than generating from parametric knowledge, and it produces outputs that analysts can verify in seconds by checking the cited source. Citations that the model cannot provide become empty citation slots, which flag outputs for human review.
Financial claim extraction and validation. After generation, we extract all quantitative claims from the output and validate them against our structured data store. If a generated output claims a company had 23% EBITDA margin and our structured data store shows 21% from the same source document, that's a discrepancy that triggers an automatic review flag. This cross-validation step catches a class of errors that neither retrieval improvement nor generation improvement alone eliminates: errors where the model "translates" a number from the context with a small rounding or transformation error.
Measuring What Actually Matters
Our 97.3% accuracy figure requires definition, because "accuracy" in RAG evaluation is not a single thing.
We measure on a curated evaluation set of 847 questions across four query categories, each with human-verified ground-truth answers:
Factual retrieval (38% of queries): Questions with exact answers in the document corpus — specific financial metrics, dates, party names, deal terms. Accuracy is binary: the generated answer matches the ground truth or it doesn't. This is where structured data retrieval matters most.
Synthesis queries (29% of queries): Questions that require combining information from multiple sections or documents — "what is the revenue CAGR implied by the financials compared to the management case projection?" Accuracy is evaluated on a 3-point scale by financial analysts on our team who check each output against the source documents.
Analytical queries (21% of queries): Questions that require applying financial reasoning to retrieved context — "is the adjusted EBITDA reconciliation consistent with the income statement?" These require understanding financial logic, not just retrieval.
Ambiguity identification (12% of queries): Questions where the honest answer is "the documents don't contain enough information to answer reliably, and here's what they do say." A system that confidently answers these questions is worse than one that correctly identifies the ambiguity.
The 97.3% figure aggregates across all four categories. Our performance is strongest on factual retrieval (99.1%) and weakest on ambiguity identification (93.4%), which reflects an ongoing challenge: teaching the system to be appropriately uncertain is harder than teaching it to be accurate on answerable questions.
What Still Breaks (And Why)
I want to be specific about our current failure modes, because the accuracy improvement story is real and the remaining failure modes are also real.
Temporal reasoning across document vintages. When a deal process involves multiple CIM versions, an updated model, and a revised management case, queries that span document vintages require understanding which version of a figure is "current" and when numbers changed. Our document processing timestamps documents and tracks version relationships, but temporal reasoning across version chains is an unsolved problem. We handle this with explicit version metadata requirements and human review flags on queries that touch multi-vintage data.
Tables with complex merge structures. Some financial tables have hierarchical row structures, merged cells, and footnote references that our table extraction pipeline cannot reliably parse. The table extraction confidence scoring flags these cases, and they fall into the human review pathway — but they represent a tail of document types where structured data retrieval degrades to dense retrieval quality.
Private market valuation methodology disputes. Analytical queries that require adjudicating between different valuation methodologies — where the answer depends on which set of assumptions is correct, not just on what the documents say — are beyond the scope of what any RAG system should be expected to answer reliably. We return these explicitly as "requires analyst judgment" rather than attempting generation.
The Practical Lessons
Two years of building financial RAG has crystallized into a set of convictions that I'd apply to any high-stakes RAG implementation:
Separate retrieval accuracy from generation quality. These are different problems with different solutions. Most RAG improvement work focuses on generation (better prompts, better models, chain-of-thought). Most RAG accuracy problems are retrieval problems — wrong or insufficient context — that no amount of generation improvement can fix.
Build domain-specific evaluation before you build the system. We didn't have a proper financial RAG evaluation framework when we started. We built the system, encountered failures in production, and rebuilt the evaluation framework retroactively. This cost us six months. Define your accuracy metrics and evaluation set first, instrument them from day one, and use them to make architectural decisions.
Invest in document intelligence in proportion to document structure complexity. The more structure-dependent your domain's documents are, the more your accuracy ceiling is determined by how well you've preserved that structure. Financial documents are among the most structure-dependent document types that exist. The document intelligence investment is not glamorous work. It's the most important work.
Explicit uncertainty beats confident wrong. A system that says "I cannot reliably answer this from the available documents" is more valuable to a financial analyst than a system that says "the company's EBITDA margin was 23%" when it was actually 21%. Build and measure your system's ability to express calibrated uncertainty. It's a better accuracy metric than raw retrieval hit rate.
The Snow Mountain AI work continues. The 97.3% accuracy figure represents the current state of a system that's been in production for over a year, processing real deals, with real consequences for error. The path there wasn't clean. But the architectural principles that emerged from walking it are now clear enough that I'd apply them with confidence to the next financial RAG system we build — and to any other high-stakes domain where document structure carries meaning that naive RAG throws away.
The accuracy is achievable. The path to it is less about prompt engineering and more about engineering.