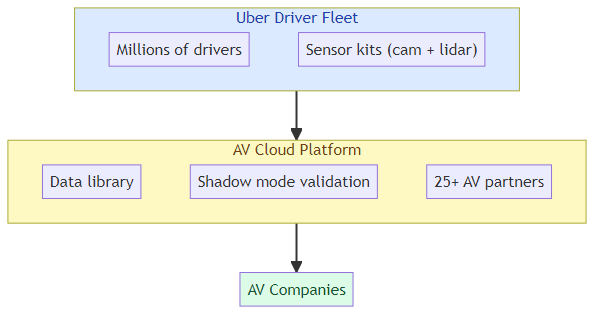
Uber abandoned its own self-driving car ambitions in 2016. Now it's found a more clever way back into the autonomous vehicle space: turning its millions of human drivers into a sensor grid.
The strategy is straightforward and elegant: Uber is equipping driver vehicles with sensor kits — cameras, lidar, radar — and selling the resulting data to autonomous vehicle companies that need training data. They already have 25 AV company partners including Wayve (which operates in London). Partners can run their trained AV models in "shadow mode" against real Uber trips, simulating performance without deploying actual vehicles.
This isn't just a pivot — it's a completely different business model that leverages Uber's unique asset: millions of vehicles operating in the real world, every day, covering routes that no AV company could afford to map independently.
The Data Economics of AV Training
Training autonomous vehicles requires massive amounts of real-world driving data. Not just any driving data — data that captures the long tail of edge cases: the unusual intersection, the unexpected pedestrian behavior, the specific weather conditions that only occur in certain geographies at certain times of year.
Building this data from scratch is expensive. Waymo spends billions building and operating its own fleet. Most AV companies can't afford to do that.
Uber's proposition: instead of building your own fleet, rent access to ours. The 25+ AV company partnerships suggest there's genuine demand from companies that would rather pay Uber for data access than build their own physical data collection infrastructure.
The Shadow Mode Innovation
The most interesting technical aspect of Uber's approach is the "shadow mode" capability. When an AV company's model is running against Uber trip data in shadow mode, it processes the sensor inputs and makes driving decisions — but those decisions don't control the vehicle. The human driver is still in charge.
This means AV companies can validate their models against real-world scenarios without the risk or cost of operating their own test vehicles. It's the equivalent of having a continuous, global validation environment for AV algorithms.
The value: shadow mode data tells you how your model would have handled a situation, compared to how the human driver actually handled it. You can identify failure modes without any physical risk.
Why Uber's Business Model Is Actually Clever
After abandoning its own AV program, Uber could have simply become a customer of AV companies — offering to be the ride-hailing platform for their vehicles. Instead, it found a position that may be more valuable: data broker between physical world sensors and AV training systems.
This works because:
- Uber has existing relationships with drivers and vehicles — no new fleet investment needed
- The sensor data has value to multiple AV companies simultaneously — network effects
- The data is continuously refreshed — every trip adds new scenarios
- Uber controls the relationship with drivers, not AV companies — positioning as infrastructure
The Privacy and Regulatory Question
Uber's own CTO acknowledged the regulatory hurdles: "We have to make sure every state has clarity on what sensors mean, and what sharing it means."
The concerns are legitimate:
- Passengers in Uber vehicles may not know they're being used as data collection nodes
- Drivers may not have given informed consent for their vehicles to be sensor-equipped
- Location data from millions of trips represents a significant privacy surface
- State-by-state regulatory variation makes national deployment complex
The regulatory path will determine whether this becomes a genuine business or remains a pilot. Uber needs regulatory clarity in every state before they can deploy sensor kits broadly.
What This Means for AV Companies
For AV companies, Uber's data offering is a double-edged sword:
Advantage: Cheap access to real-world training data without building fleet infrastructure. Shadow mode validation without physical risk. Geographic coverage that would take years to build independently.
Disadvantage: Dependency on a third party for data. No direct control over data quality, timing, or coverage. Competitive implications — if your competitor also has Uber data access, the data advantage is neutralized.
The companies that benefit most are those still building their training data foundation. Waymo, which has already invested heavily in its own fleet, has less to gain from Uber's data than an earlier-stage AV startup that hasn't built physical data collection infrastructure yet.
The Deeper Pattern: Physical World Data as a Service
Uber's sensor cloud is part of a broader pattern emerging in AI infrastructure: physical world data as a service.
We've seen this in other domains:
- Satellite imagery companies (Planet Labs, Maxar) selling earth observation data to AI models
- Medical device companies selling surgical procedure data for robot training
- Agricultural equipment companies selling field condition data for precision farming AI
The common thread: companies with existing physical world presence discover their operational data has value beyond their original use case. They become data suppliers to AI training pipelines.
For builders: if your company operates in the physical world and collects sensor data, there may be a data monetization path you haven't considered. The question isn't just "how do we use this data to improve our own operations" but "who else would pay for access to this data to train AI systems?"
Uber found an elegant answer to that question. The AV industry is the beneficiary.
Related posts: Physical AI Agents — the frontier of AI operating in the physical world. AI Agent Commerce — the infrastructure for autonomous agents in commercial contexts. Image AI App Growth — the data monetization patterns in consumer AI.


