
Gemini Robotics: When Language Model Scale Finally Meets the Physical World
The vision has been clear for years: take the reasoning capabilities of large language models, extend them to perception and action, and get robots that can understand natural language instructions and manipulate the physical world intelligently. The execution has been harder.
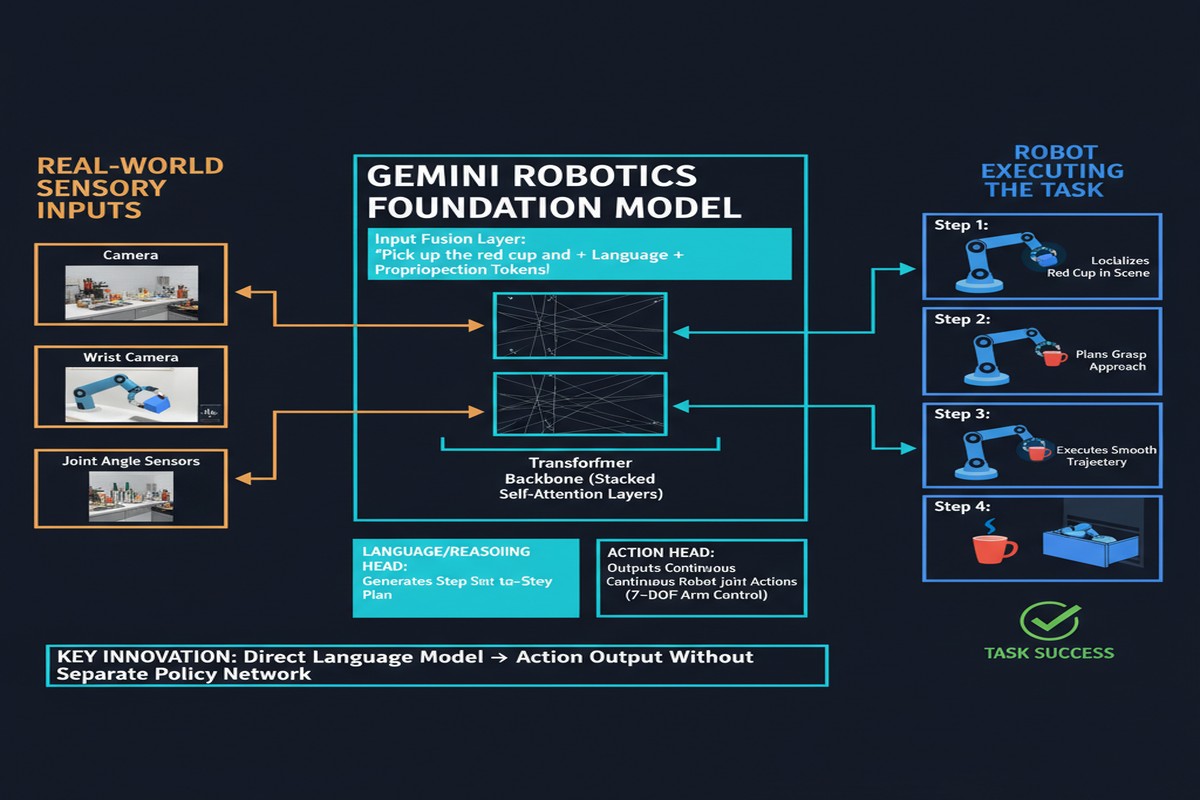
Gemini Robotics (arXiv: 2503.20020, Mar 2025) from Google DeepMind represents the most serious attempt yet to build a robotics foundation model on top of frontier language model capabilities. It's built on Gemini 2.0, designed for direct robot control, and introduces architecture innovations that address the core problems that have limited previous Vision-Language-Action (VLA) models.
The Architecture: Two Models, Complementary Roles
The Gemini Robotics family consists of two specialized models:
graph TD
subgraph Gemini Robotics Family
A[Gemini Robotics-ER\nEmbodied Reasoning] --> B[Spatial understanding\nObject detection\nTrajectory prediction\nGrasp prediction\n3D bounding boxes\nMulti-view correspondence]
C[Gemini Robotics\nVision-Language-Action] --> D[Direct robot control\nAction generation\nInstruction following\nMulti-embodiment support]
end
E[Camera Input] --> A
E --> C
F[Language Instruction] --> A
F --> C
A -->|Spatial features| C
C --> G[Robot Actions]
style A fill:#2563eb,color:#fff
style C fill:#7c3aed,color:#fff
Gemini Robotics-ER (Embodied Reasoning): An enhanced version of Gemini 2.0 with specialized spatial and temporal understanding for robotic contexts. It adds capabilities like:
- Object detection with precise localization
- Grasp pose prediction
- Robot trajectory visualization
- 3D bounding box prediction
- Multi-view correspondence (understanding how the scene looks from different camera angles)
Gemini Robotics (the VLA model): Built on top of Gemini Robotics-ER, this model generates direct robot control actions — motor commands, joint angles, end-effector positions — from camera inputs and language instructions.
The Motion Transfer Mechanism
The headline technical contribution of Gemini Robotics 1.5 (arXiv: 2510.03342, Oct 2025) is Motion Transfer: a mechanism that enables learning from heterogeneous, multi-embodiment robot data.
The fundamental problem: robots come in different body configurations. A manipulation arm differs from a bipedal robot differs from a mobile manipulator. Training data collected on one robot type doesn't directly transfer to another — the action spaces are different, the morphology is different, the dynamics are different.
Motion Transfer addresses this by factoring robot control into:
- Motion primitives: Abstract, embodiment-agnostic descriptions of intended movements ("reach toward object," "grasp with precision grip," "retract arm")
- Embodiment-specific mapping: How each robot's specific morphology executes the abstract motion
By learning motion primitives that transfer across embodiments, Gemini Robotics can train on data from multiple different robot types and generalize the underlying movement intentions to new robot platforms.
flowchart LR
A[Data from Robot A\n7-DOF arm] --> M[Motion Transfer\nAbstract Motion Primitives]
B[Data from Robot B\nMobile manipulator] --> M
C[Data from Robot C\nBipedal robot] --> M
M --> D[Generalist Policy]
D --> E[Deploy on new\nRobot type D]
style M fill:#2563eb,color:#fff
style D fill:#059669,color:#fff
What Gemini Robotics Can Do
The paper demonstrates a wide range of manipulation capabilities:
Dexterous manipulation: Precise grasping of small objects, handling of fragile items, assembly tasks requiring millimeter-level accuracy.
Instruction following: Multi-step tasks from natural language instructions — "put the red block on top of the blue block, then place both in the box." The language model backbone provides genuine semantic understanding rather than keyword matching.
Long-horizon tasks: Tasks requiring 20-50 sequential steps, maintaining state across the sequence and recovering from manipulation failures.
Novel object generalization: The model handles objects not seen during training by leveraging its visual understanding from Gemini's pretraining.
Human-robot interaction: Understanding and responding to gestures, pointing, and conversational guidance during task execution.
The Comparison to Physical Intelligence's π₀
Released in close temporal proximity, Physical Intelligence's π₀ (arXiv: 2410.24164) and its successor π₀.₅ (arXiv: 2504.16054) represent the other major approach to generalist robot policies:
| Feature | Gemini Robotics | π₀/π₀.₅ |
|---|---|---|
| Foundation | Gemini 2.0 (large, general) | PaliGemma + Flow Matching |
| Training data | Heterogeneous multi-embodiment | 10,000+ hours of robot data |
| Architecture | VLA + Motion Transfer | Vision-Language-Action with flow |
| Focus | Google's robots + platform | General-purpose deployment |
| Compute | Large (Gemini-scale) | Moderate |
Both approaches use large-scale pre-training and flow-based action generation. The key difference is foundation: Gemini Robotics bets on Gemini's general intelligence transferring to robotics; π₀ bets on massive robot-specific pretraining.
Why This Matters for Embodied AI
Robots that can understand natural language, generalize to new objects and environments, and transfer capabilities across embodiments are transformative for:
Manufacturing automation: Instead of programming precise movements for every task, give robots natural language instructions. Reconfigure robot tasks by talking to them.
Healthcare and elder care: Robots that can respond to natural instructions from patients, perform gentle manipulation tasks, and adapt to individual needs.
Logistics and warehousing: Warehouse robots that understand "put fragile items in the top-right section" rather than requiring QR code scanning for every placement decision.
Domestic robots: The "robot in the home" dream requires exactly the kind of instruction-following and novel-object generalization that Gemini Robotics demonstrates.
The Real Challenge: Sim-to-Real and Safety
The paper presents impressive results, but the robotics field has been here before: impressive lab results followed by disappointing real-world deployment.
The key challenges Gemini Robotics doesn't fully solve:
Sim-to-real gap: Training on robot data collected in controlled lab environments. Real-world deployment faces different lighting, novel object arrangements, physical variations in objects (used items vs. pristine lab items), and unpredictable human interactions.
Contact-rich manipulation: Grasping and manipulation tasks that require precise force control — like unscrewing a cap, opening a stuck drawer, or handling liquids — remain challenging.
Safety guarantees: A robot that can misinterpret an instruction and apply force to a fragile object or a human is a liability, not a product. The paper's safety evaluation is limited.
My Take
Gemini Robotics is technically impressive and strategically important. Google has the infrastructure (Gemini's scale, cloud compute, robot hardware) to make generalist robot policies a product, not just a research demo. The Motion Transfer mechanism is the right idea for the multi-embodiment problem.
But I want to be honest about where this actually is: lab-quality demonstrations on carefully designed tasks with ideal lighting and known object placements. The gap between "impressive lab demo" and "reliable deployment in a real kitchen" remains substantial.
The most important contribution may be normalizing high-quality VLA models as a research category. Two years ago, getting a robot to follow natural language instructions for multi-step manipulation was genuinely hard. Gemini Robotics makes it look almost easy. That's the right trajectory — even if "almost easy" is still much harder than it appears.
Physical intelligence is the next AI frontier. The question isn't if generalist robot policies will work — it's how fast and how robustly. Gemini Robotics is a serious bet that the answer is faster than anyone expected.
Paper: "Gemini Robotics: Bringing AI into the Physical World", arXiv: 2503.20020, Mar 2025. Also: "Gemini Robotics 1.5", arXiv: 2510.03342, Oct 2025.
Explore more from Dr. Jyothi


