
π₀.₅: Teaching Robots to Generalize to the Open World Without Infinite Training Data
The fundamental problem with robot learning is generalization. You can train a robot to perform a task perfectly in the lab — pick up the red block, fold this shirt, open this specific cabinet. But real environments are not lab environments. The lighting is different. The objects have different configurations. Unexpected obstacles appear. The task description is ambiguous.
Every robot learning paper makes the same implicit assumption: "assume we can train on enough data from the target environment." But you can't always do that. The open world is infinite, and you can't have a robot in every kitchen collecting data before it helps with dinner.
π₀.₅ (arXiv: 2504.16054, Apr 2025) from Physical Intelligence addresses this head-on. Built on top of the π₀ architecture (the generalist robot policy trained on 10,000+ hours of robot data), π₀.₅ extends to open-world generalization through co-training on heterogeneous data sources — not just robot demonstrations, but video data, web data, and high-level semantic prediction.
The Problem: Distribution Shift in the Open World
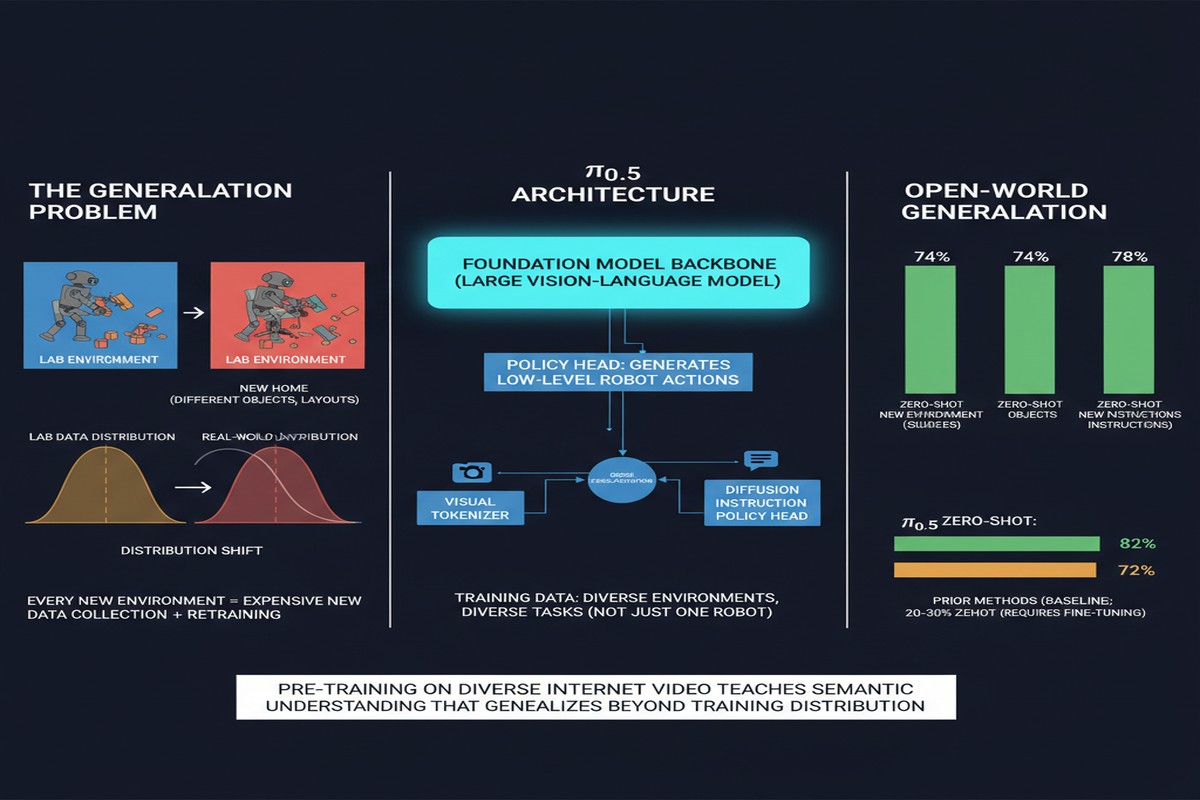
Training a robot policy on expert demonstrations from controlled environments creates a specific failure mode: the policy learns to associate observations from the training distribution with the correct actions. Outside that distribution — different object placements, novel objects, different environmental conditions — the policy fails silently or spectacularly.
This is called distribution shift, and it's the bane of deployed robotics systems:
graph LR
subgraph Training Environment
A[Known objects] --> B[Fixed positions]
B --> C[Controlled lighting]
C --> D[Expert policy trained]
end
subgraph Real World
E[Novel objects] --> F[Arbitrary positions]
F --> G[Variable lighting]
G --> H[Policy fails]
end
D -.->|Distribution shift| H
style H fill:#ef4444,color:#fff
style D fill:#059669,color:#fff
The only way to handle distribution shift robustly is either:
- Data coverage: Train on enough data to cover the real-world distribution (impractical for the open world)
- Generalization: Train on diverse enough data that the policy learns generalizable representations, not surface statistics
π₀.₅ pursues option 2 through a carefully designed co-training strategy.
What π₀.₅ Adds to π₀
The original π₀ was trained exclusively on robot demonstrations — 10,000+ hours of expert robot data across many manipulation tasks. This produced a remarkably capable generalist policy that could handle many tasks across multiple robot embodiments.
π₀.₅ adds three key training data sources:
1. Heterogeneous Multi-Robot Data
π₀.₅ trains on data from multiple different robot types simultaneously, using the same flow-matching architecture. Each robot has different morphology, different action spaces, and different task specializations. By co-training across this heterogeneity, the model learns task-relevant representations that are less tied to specific robot configurations.
2. High-Level Semantic Prediction
π₀.₅ introduces a new training objective: predicting high-level semantic properties of scenes beyond just predicting robot actions. This includes:
- Object identity and category
- Spatial relationships between objects
- Task-relevant affordances ("this object can be grasped here")
- Scene state estimation
Training the model to predict these semantic properties alongside robot actions forces it to develop richer scene representations — representations that generalize beyond the specific visual statistics of training data.
flowchart TD
A[Camera Image] --> B[π₀.₅ Encoder\nShared Representation]
B --> C[Action Head:\nRobot motor commands]
B --> D[Semantic Head:\nObject categories, spatial relations, affordances]
B --> E[Task Head:\nHigh-level task state]
C --> F[Robot Control]
D --> G[Scene Understanding]
E --> H[Task Monitoring]
style B fill:#2563eb,color:#fff
style D fill:#7c3aed,color:#fff
The semantic head is not used at deployment — only the action head drives the robot. But training with the semantic objective shapes the representation learning in ways that improve generalization.
3. Web Video Data
Perhaps the most ambitious addition: co-training on web video data showing humans performing manipulation tasks. YouTube cooking videos, home organization videos, factory footage — all provide examples of manipulation in diverse, realistic environments.
The challenge: web video doesn't have robot action labels. You can't directly supervise the policy on "what action should the robot take at this frame." π₀.₅ uses the video data to train the representation learning components (the visual encoder and scene understanding) rather than the action prediction components. This provides exposure to visual diversity — novel objects, environments, lighting conditions — that purely robot data cannot provide.
Open-World Generalization Results
The paper evaluates π₀.₅ on explicitly out-of-distribution tasks — tasks not seen during training:
Novel object generalization: π₀.₅ handles objects not seen during training with substantially higher success rates than π₀. The semantic prediction training and visual diversity from web video contribute to more robust object recognition under distribution shift.
Novel environment transfer: When deployed in homes and offices not represented in training data, π₀.₅ maintains reasonable performance while π₀ degrades significantly.
Instruction following for novel tasks: Given natural language instructions for task variations not seen in training, π₀.₅ successfully generalizes where previous models fail.
Cross-robot generalization: The multi-embodiment co-training improves performance when the policy is adapted to new robot platforms with limited fine-tuning data.
xychart-beta
title "Task Success Rate: In-Distribution vs Out-of-Distribution"
x-axis ["In-Distribution\nKnown Tasks", "Novel Objects", "Novel Environments", "Novel Instructions"]
y-axis "Success Rate %" 0 --> 90
line [78, 31, 24, 29]
line [82, 61, 58, 67]
Blue: π₀. Orange: π₀.₅. Out-of-distribution improvement is substantial.
The Architecture: Flow Matching for Robot Control
Both π₀ and π₀.₅ use flow matching for action generation — a continuous normalizing flow approach related to diffusion models. Rather than predicting discrete actions, the model learns to transform random noise into smooth robot trajectories.
This is technically important for manipulation: robot actions must be smooth and continuous (jerky motions damage robots and objects). Flow matching naturally generates smooth trajectories because the denoising process operates in continuous action space.
The visual backbone is PaliGemma, Google DeepMind's vision-language model — providing rich visual features that leverage internet-scale image-language pretraining for grounding.
The Strategic Picture: Physical Intelligence vs. Big Labs
Physical Intelligence (the startup behind π₀) is taking a notable approach: build the best robot policy models, make them available to robot manufacturers, and become the "foundation model provider" for the robotics industry.
Compare with:
- Google DeepMind (Gemini Robotics): Vertically integrated — building the model and the robots
- Physical Intelligence: Foundation model provider to the ecosystem
The π₀.₅ paper's emphasis on open-world generalization is directly aligned with the commercial pitch: a policy that works in your factory/kitchen/hospital, not just the lab where it was trained.
This is analogous to how LLM providers differentiate: OpenAI with a closed vertically integrated approach, versus open-weight models that others build applications on.
Why This Matters
Open-world generalization is the key capability separating "robotics demos" from "deployed robotics products." Every impressive robotics demo you've seen lives in a controlled environment. Every failed robotics deployment fails because the real world didn't match the training distribution.
π₀.₅'s co-training approach — diverse robot data + semantic prediction + web video — is the right recipe for addressing this. It's not revolutionary in concept (we've known for years that visual diversity and semantic supervision improve generalization), but it's the most rigorous implementation of these ideas in a robotics context to date.
My Take
π₀.₅ is a technically strong paper with clear commercial motivation. The open-world generalization results are the most important numbers in the paper — and they're genuinely encouraging. A 2x improvement in novel-environment success rates is not incremental.
The web video co-training is the most creative contribution. Using YouTube as a source of manipulation demonstrations (without action labels) to improve visual representation is clever and scalable — YouTube will never run out of humans performing household tasks.
I want to see longer-horizon evaluation. The tasks in the paper are mostly short-horizon (pick and place, small object manipulation). Real household assistance involves sequences of 20-50 steps with state maintenance. Does π₀.₅'s generalization hold over long horizons? That's the paper that needs to come next.
The manipulation-with-contact challenge remains. π₀.₅ shows impressive generalization for pick-and-place and simple manipulation. For contact-rich tasks — opening jars, using kitchen appliances, handling liquids — the paper doesn't evaluate extensively. Those are the tasks that matter most for domestic deployment.
Physical Intelligence is making the right bets. Open-world generalization is the frontier that determines whether robotics becomes a general-purpose technology or remains a specialized automation tool.

Paper: "π₀.₅: a Vision-Language-Action Model with Open-World Generalization", arXiv: 2504.16054, Apr 2025. Physical Intelligence.
Explore more from Dr. Jyothi


