
Every few years, a class of AI hardware ideas goes from "interesting physics paper" to "plausible engineering project." We've seen this with FPGAs (from embedded controllers to LLM inference engines), with in-memory computing (from DRAM research to commercial PIM chips), and now — I believe — with photonic computing.
Hardware-Efficient Photonic Tensor Core: Accelerating Deep Neural Networks with Structured Compression (arXiv:2502.01670) is a February 2025 paper that represents this transition for optical computing. It's not saying "light can do matrix multiplication in principle." It's saying "here's a concrete photonic tensor core architecture with structured compression that makes it hardware-efficient and accurate." That's a different conversation.
Why Photonics for AI?
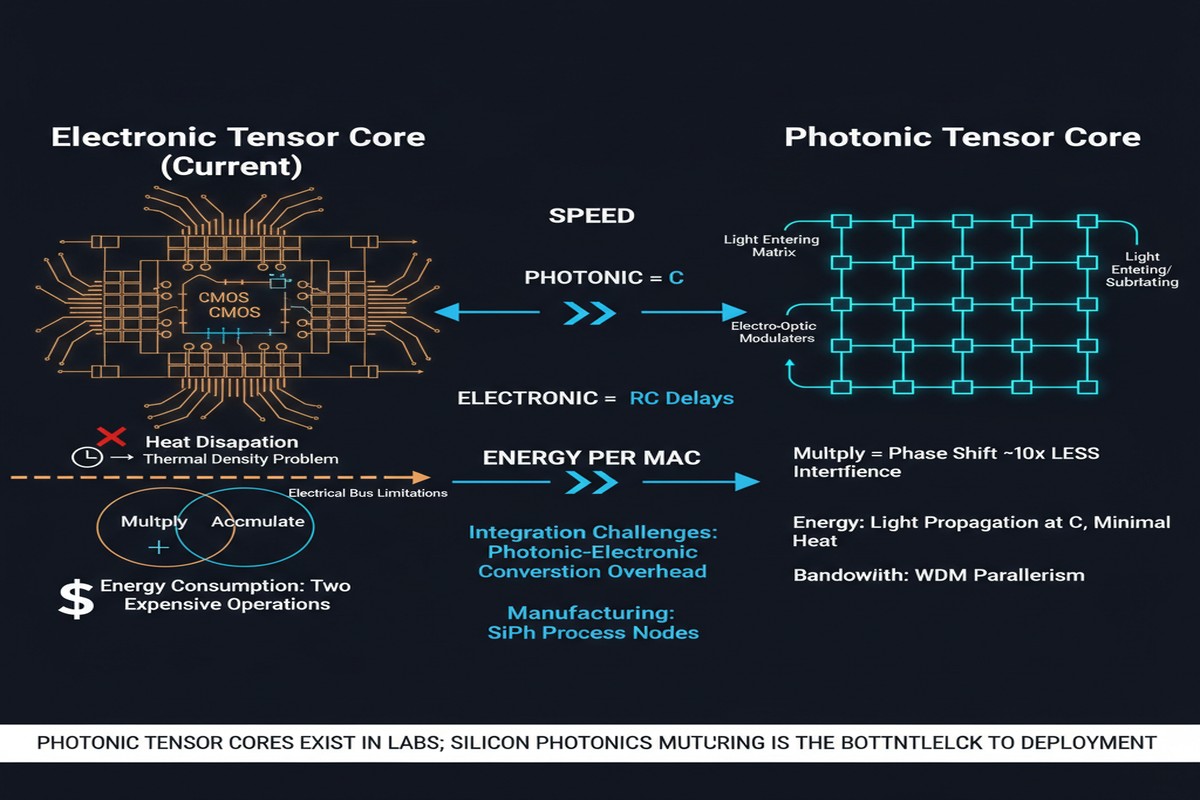
Let me first motivate why anyone is doing this. Photonic computing uses light — photons — instead of electrons for computation. The advantages are compelling in theory:
- Speed: Photons travel at c (the speed of light) with negligible propagation delay
- Bandwidth: Wavelength-division multiplexing (WDM) allows many signals to travel simultaneously on different wavelengths through the same waveguide — natural parallelism
- Energy: Photonic interconnects consume far less energy than electronic ones; matrix multiplications on analog photonic hardware can approach the fundamental energy limits imposed by physics
The challenge: photonic hardware is extraordinarily hard to manufacture with high precision. Integrated photonic devices require nanometer-scale fabrication tolerances. Nonlinear optical operations (needed for activation functions) are hard. And perhaps most fundamentally, photonic systems are analog — they accumulate noise, and the noise characteristics are very different from digital electronics.
The Photonic Tensor Core Architecture
The paper proposes a photonic tensor core that performs matrix-vector multiplication (the core operation in neural network layers) using optical interference. The key hardware components:
Optical weight matrices: Weights are encoded as phase shifts in an integrated optical mesh — typically a Mach-Zehnder Interferometer (MZI) mesh. An MZI can implement a 2×2 unitary matrix; arrays of MZIs implement larger unitary matrices; and combinations of unitary matrices with diagonal phase screens implement arbitrary linear transformations.
Structured Compression (StrC-ONN): Here's the core innovation. A standard photonic matrix requires O(N²) MZIs for an N×N weight matrix. For large neural network layers, this is physically infeasible — the chip area grows with the square of the layer size. The paper introduces structured compression that reduces the MZI count by up to 74.91% while maintaining competitive accuracy.
The compression works by constraining the weight matrices to a structured family (combinations of sparse and low-rank decompositions) that maps efficiently onto the photonic hardware. Think of it as a hardware-aware neural network compression technique, but the hardware is an optical chip rather than a digital ASIC.
graph LR
subgraph Traditional["Standard Photonic NN"]
A["Input\n(optical)"] --> B["N×N MZI Mesh\nO(N²) components"]
B --> C["Photodetector\n(optical→electrical)"]
C --> D["Output"]
end
subgraph StrC["StrC-ONN Compressed"]
E["Input\n(optical)"] --> F["Sparse\nMZI Block"]
F --> G["Low-Rank\nMZI Block"]
G --> H["Phase\nScreen"]
H --> I["Photodetector"]
I --> J["Output"]
end
style Traditional fill:#888,color:#fff
style StrC fill:#00d4ff,color:#000
The Performance Numbers
The paper reports:
- 74.91% reduction in trainable parameters (the MZI count reduction, which maps to hardware area)
- Competitive accuracy on standard benchmarks (within acceptable bounds for the task)
- Projected 3.56× improvement in power efficiency compared to uncompressed photonic architectures
That last number deserves unpacking: 3.56× better power efficiency than the uncompressed photonic baseline, which is already substantially more energy-efficient than comparable electronic accelerators for matrix multiplication. The absolute comparison against GPUs is not the paper's primary focus — it's about making photonic hardware practical through compression.
flowchart TD
A[Photonic Tensor Core\nUncompressed] -->|"StrC-ONN"| B[Photonic Tensor Core\nStructured Compression]
B --> C["74.91% fewer MZIs\n= smaller chip area"]
B --> D["3.56× power efficiency\nimprovement"]
B --> E["Competitive accuracy\nmaintained"]
style B fill:#00d4ff,color:#000
style C fill:#76b900,color:#fff
style D fill:#76b900,color:#fff
The Real Challenges
I want to be genuinely honest about where photonic computing stands, because there's a tendency in the field to overstate near-term readiness.
Manufacturing tolerances: An MZI requires phase control at nanometer precision. Phase errors accumulate — in a large MZI mesh, even small fabrication errors produce significant output errors. The paper acknowledges this; StrC-ONN's structured approach actually helps here by providing a more constrained, error-tolerant architecture. But this remains the central manufacturing challenge.
Nonlinearity: Neural networks require nonlinear activation functions. Photonic hardware does linear transformations extremely well. Nonlinear operations require either electro-optic conversion (electronic nonlinearity applied to an optical signal) or exotic nonlinear optical materials. The paper's architecture includes opto-electronic conversion at layer boundaries, which somewhat undermines the "pure optical" efficiency argument.
ADC/DAC bottlenecks: Converting between digital inputs and analog optical signals at every layer boundary incurs energy and latency costs. High-precision ADCs (needed to maintain accuracy) are expensive in both area and power. This is an often-overlooked part of the photonic computing energy budget.
Thermal sensitivity: Silicon photonic devices are extremely sensitive to temperature variations. Phase shifts in MZIs drift with temperature, requiring active thermal stabilization — which consumes power and adds complexity.
None of these are insurmountable. But they are why photonic AI hardware is still in the research phase rather than the product phase.
Why This Matters
Despite the challenges, I think photonic computing is worth taking seriously, for reasons that go beyond this paper.
The physics argument is compelling. Electronic interconnects are approaching fundamental limits — resistance, capacitance, electron velocity. Optical interconnects already outperform electronic ones at long distances, and as chip-to-chip and within-chip interconnects become the bottleneck, photonics becomes increasingly attractive.
The energy argument is compelling. The AI industry's power consumption is growing rapidly. Photonic matrix multiplication approaches the Landauer limit (the theoretical minimum energy per computation), whereas electronic CMOS dissipates energy even in reversible operations. At the scale AI compute is reaching, orders-of-magnitude energy improvements are worth chasing.
The structured compression insight in this paper is particularly valuable because it bridges photonics and practical neural network compression. StrC-ONN isn't just about making photonic hardware more area-efficient — it's a hardware-software co-design approach that constrains the network architecture to match the hardware's natural structure. This is the right way to think about any novel hardware: design the software to exploit hardware strengths, not to fight hardware limitations.
My Take
I'm cautiously bullish on photonic AI, with the emphasis on cautiously.
The 3-5 year outlook: photonic co-processors for specific functions (especially dense matrix multiplication in dedicated inference accelerators) will become commercially available. You won't be replacing your H100s with photonic chips. You'll be adding photonic matrix units to hybrid electronic-photonic chips that do the linear algebra in light and everything else in electronics.
The 10-year outlook: if integrated photonics manufacturing matures — particularly nonlinear optics and thermal stabilization — photonic computing could genuinely disrupt the inference accelerator market. The energy efficiency argument alone is compelling enough to drive massive investment.
This specific paper (arXiv:2502.01670) is a solid engineering contribution. StrC-ONN's compression approach is genuinely clever, and the 74% area reduction it achieves is meaningful for making photonic hardware viable at practical scales. What I'd want to see next: actual fabricated silicon photonic chips demonstrating these compression benefits on real inference workloads, not simulation results.
The field is maturing. In 2025, photonic AI papers that show actual fabricated devices running real neural network inference are becoming more common. We're not there yet with StrC-ONN, but the research trajectory is positive.
Light as compute. I'm watching this space closely.
References
- (2025). Hardware-Efficient Photonic Tensor Core: Accelerating Deep Neural Networks with Structured Compression. arXiv:2502.01670.
- Shen, Y., et al. (2024). Integrated photonic deep neural network with end-to-end on-chip backpropagation training. arXiv:2506.14575.



