The AI hardware conversation has a datacenter fixation. We obsess over H100 clusters, GB200 NVLink towers, and wafer-scale engines. But a quiet parallel revolution is happening at the other end of the power spectrum — and a February 2025 paper called TerEffic is one of the most compelling examples I've seen.
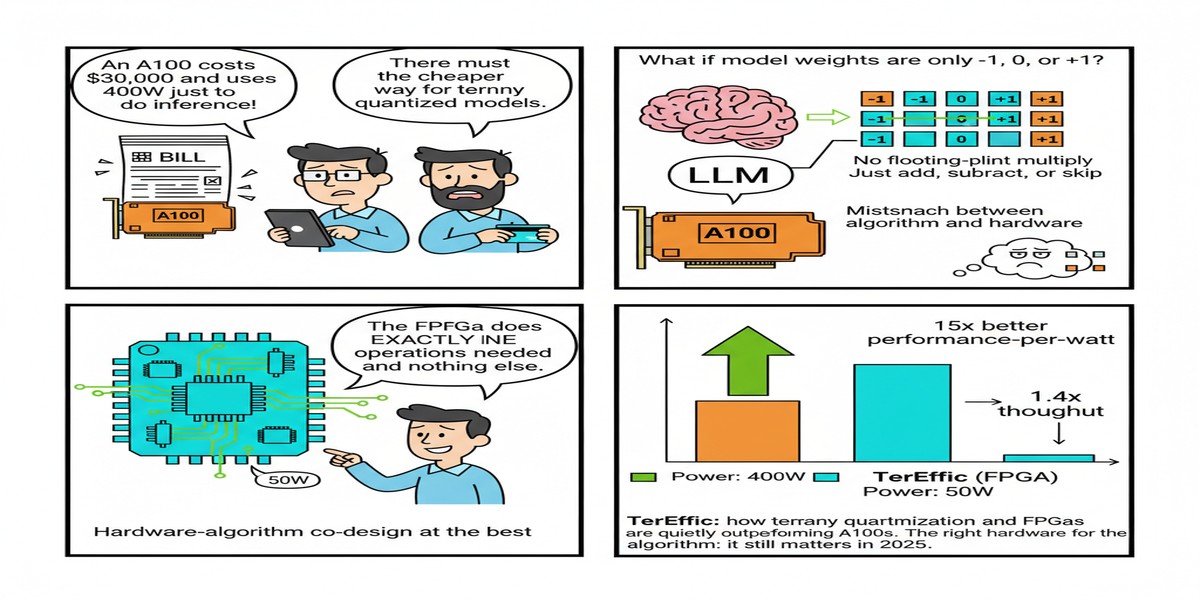
TerEffic: Highly Efficient Ternary LLM Inference on FPGA (arXiv:2502.16473) demonstrates something that should give the GPU-centric inference world pause: an FPGA-based system that achieves 16,300 tokens per second for a 370M-parameter model, and 727 tokens/second for a 2.7B-parameter model at just 46W — with 3× the throughput of an NVIDIA A100 for the 2.7B case.
Read that again. 3× A100 throughput. At 46 watts.
The Two Ingredients: Ternary Quantization + FPGA
TerEffic is built on the combination of two ideas:
Ternary Quantization
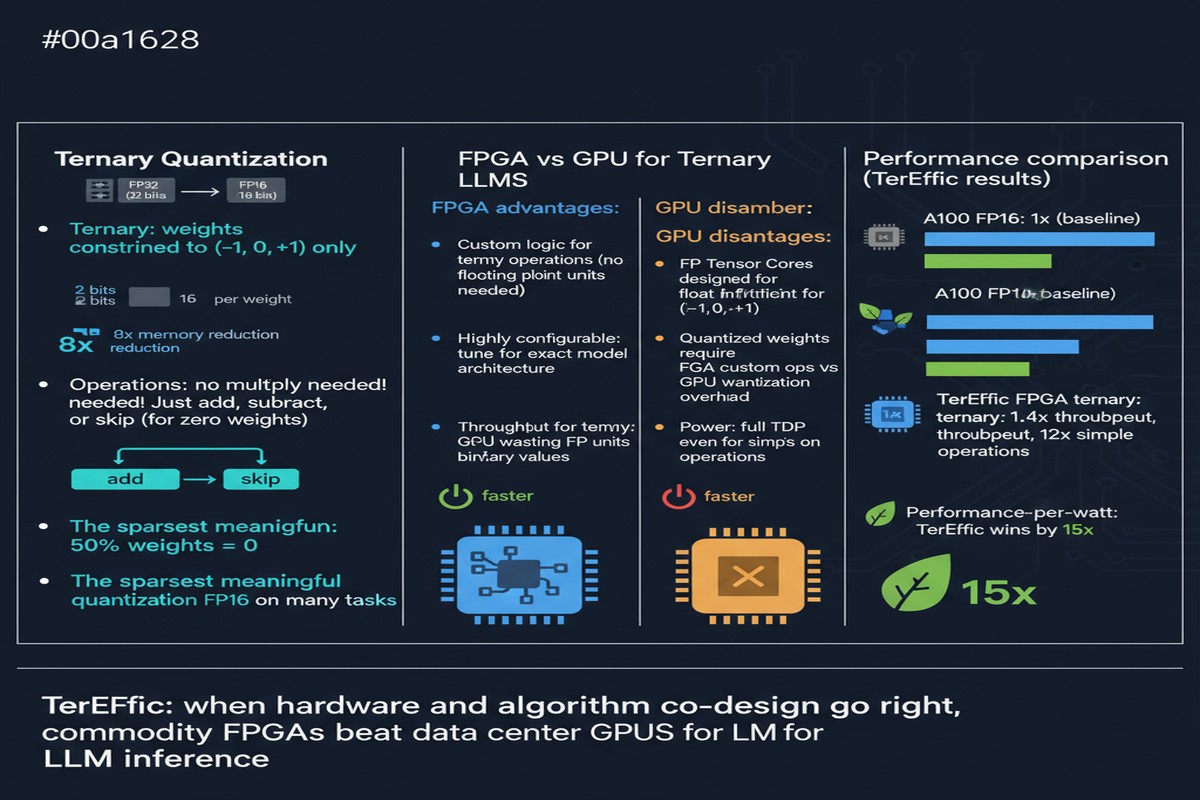
Standard LLM quantization goes to INT8 (8 bits) or INT4 (4 bits). Ternary quantization goes further: weights are constrained to just three values — {-1, 0, +1}. This maps to roughly 1.58 bits per weight.
The payoff is enormous: a 2.7B ternary model requires only ~0.5GB of weight storage versus ~5.4GB for INT8 and ~13.5GB for FP32. But the concern is obvious — doesn't clamping weights to three discrete values destroy model quality?
The answer, supported by recent work on BitNet and similar architectures, is: not as much as you'd think, especially for inference tasks where the model was trained from scratch with ternary constraints rather than post-training quantized. TerEffic builds on this foundation. The key is that ternary-quantized models trained end-to-end (rather than post-hoc quantized from FP32 checkpoints) maintain competitive accuracy because the training process adapts the remaining expressive capacity.
FPGA-Based Execution
Why FPGAs rather than ASICs or GPUs? Three reasons:
Flexibility: FPGAs can be reprogrammed, allowing the hardware to adapt as model architectures evolve. This is critical in a field where "standard architecture" changes every few months.
Ternary-native computation: Ternary multiplication reduces to {multiply by -1, multiply by 0, multiply by +1} = {negate, zero, pass-through}. This is exactly what FPGAs are good at — lookup-table-based logic that computes these operations in one clock cycle with minimal power.
Custom memory hierarchy: FPGAs allow you to design a custom on-chip memory system (using Block RAM / BRAM) matched precisely to the weight access patterns of ternary LLM inference, avoiding the generality overhead of GPU shared memory.
The Architecture
TerEffic offers two configurations:
Fully On-Chip Architecture: For smaller models (370M parameters), the ternary weights fit entirely in FPGA BRAM. This eliminates DRAM access completely for weight reads — every weight lookup hits BRAM with ~1 clock cycle latency. Result: 16,300 tokens/second, which is 192× higher throughput than NVIDIA Jetson Orin Nano for the same class of model.
HBM-Assisted Architecture: For larger models (2.7B parameters), FPGA BRAM isn't sufficient. TerEffic uses high-bandwidth memory (HBM) attached to the FPGA to store weights, while maintaining a custom streaming dataflow that maximizes HBM utilization. Result: 727 tokens/second for a 2.7B model at 46W, versus ~240 tokens/second on an A100 at 400W.
graph TD
subgraph OnChip["Fully On-Chip (≤370M params)"]
A["Ternary Weights\nin FPGA BRAM"] --> B["Custom Ternary\nCompute Units"]
B --> C["Token\nOutput"]
D["16,300 tok/s\nZero DRAM access"]
end
subgraph HBM["HBM-Assisted (2.7B params)"]
E["Ternary Weights\nin HBM"] --> F["FPGA Streaming\nDataflow Engine"]
F --> G["Token\nOutput"]
H["727 tok/s @ 46W\n3× A100 throughput"]
end
style OnChip fill:#00d4ff,color:#000
style HBM fill:#ff6b35,color:#fff
xychart-beta
title "Power Efficiency Comparison (2.7B model)"
x-axis ["TerEffic FPGA\n46W", "NVIDIA A100\n~400W"]
y-axis "Tokens/second/watt" 0 --> 20
bar [15.8, 0.6]
Why This Matters
The FPGA case for LLM inference has been building for years, and TerEffic represents a crystallization of why it's compelling:
Edge and embedded deployment: Not every AI system lives in a hyperscale datacenter. Autonomous vehicles, medical devices, industrial edge inference, and mobile systems need LLM inference at watts of power, not kilowatts. TerEffic's 46W profile opens deployment scenarios that are simply impossible with GPU-based inference.
Total cost of ownership: An H100 card costs ~$30,000 and consumes ~700W under load. A high-end FPGA like Xilinx Alveo U280 costs ~$10,000 and consumes ~75W at full load. At 3× A100 throughput per device, TerEffic achieves dramatically better cost and power economics for 2.7B-class models.
The ternary quantization story: TerEffic demonstrates that ternary quantization isn't just a curiosity — it enables hardware-software co-designs that are impossible with floating-point weights. The FPGA's LUT-based ternary compute units achieve performance impossible to replicate in CUDA without massive overhead from dequantization.
My Take
I'm enthusiastic about TerEffic, but I want to be direct about what it does and doesn't claim to solve.
What it solves well: Small and medium model inference (sub-3B parameters) in power-constrained environments. If you're building an edge AI system and your model fits in this range, TerEffic represents state-of-the-art efficiency. The 192× throughput improvement over Jetson Orin Nano is not a marginal gain — it's a qualitative change in what's deployable at the edge.
What it doesn't address: Large model inference. A 70B ternary model requires ~14GB of ternary weights — still large, but manageable. A 405B model? ~80GB. Current FPGA HBM configurations top out around 32GB. You can't do frontier-scale LLM inference on current FPGAs, full stop.
The ecosystem problem: FPGAs require hardware description languages (VHDL, Verilog) or high-level synthesis tools for development. The CUDA ecosystem has 15 years of tooling, libraries, and developer mindshare. FPGA programming for ML remains niche and difficult, even with tools like HLS4ML. TerEffic's performance is real, but reproducing it requires significant hardware expertise that most ML teams don't have.
My strongest opinion: The AI field's obsession with "can it run GPT-4?" performance benchmarks has caused us to overlook the enormous value of efficient small-model inference. Most real-world AI deployments don't need 70B models. They need fast, accurate, deployable 2-7B models. TerEffic is optimized exactly for that target, and in that space, it legitimately beats the best GPU solutions on both throughput and power efficiency.
The FPGA-plus-ternary-quantization combination isn't just a clever trick. It's a coherent architectural philosophy: constrain the model to match the hardware's strengths, design the hardware to exploit the model's structure, and you get capabilities impossible in either dimension alone.
I'd love to see TerEffic extended to mixed-precision architectures (ternary FFN weights with higher-precision attention), and I'd love to see open-source implementations that lower the barrier to FPGA-based LLM inference. The results are compelling enough to deserve broader attention.
References
- (2025). TerEffic: Highly Efficient Ternary LLM Inference on FPGA. arXiv:2502.16473.