
World Models for Embodied AI: The Internal Simulator That Changes Everything
What separates a robot that can execute pre-programmed movements from one that can actually think about what it's doing? One answer, increasingly supported by the robotics AI research community, is the world model — an internal representation that lets an agent simulate what will happen in its environment before committing to an action.
"A Comprehensive Survey on World Models for Embodied AI" (arXiv: 2510.16732, Oct 2025) synthesizes the rapidly growing literature on world models — what they are, how they're built, what they enable, and where they fall short. It's the kind of survey that makes a research area legible to practitioners, and this one does it for one of the most important frontiers in AI.
What Is a World Model?
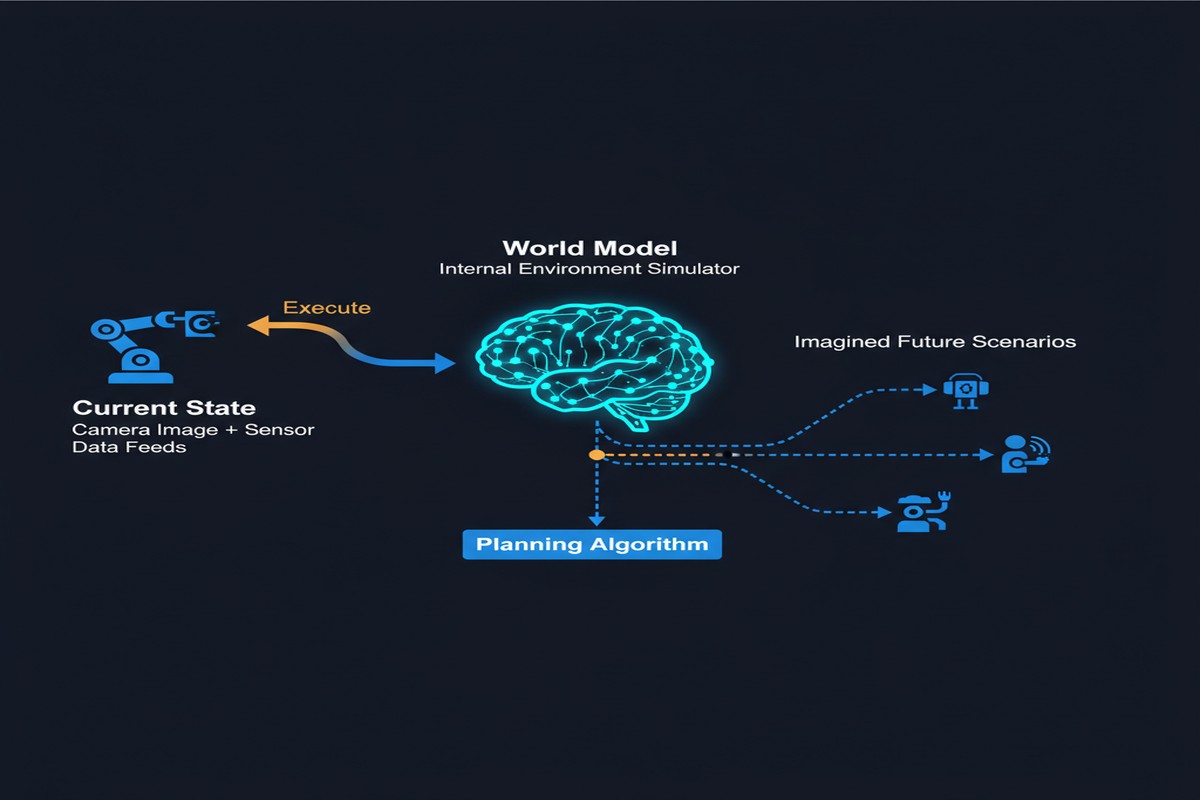
A world model is a learned internal representation of how an environment works. Given the current state of the world and an action, a world model predicts the resulting next state.
flowchart LR
A[Current State s_t\nCamera image, sensor data] --> W[World Model]
B[Proposed Action a_t\nMotor command, tool use] --> W
W --> C[Predicted Next State s_{t+1}]
W --> D[Predicted Reward r_t]
C --> E[Planning Algorithm]
E -->|Evaluate many\naction sequences| F[Optimal Action]
F -->|Execute| G[Robot / Agent]
style W fill:#2563eb,color:#fff
style E fill:#7c3aed,color:#fff
This might sound simple, but the implications are profound:
Planning with imagination: Instead of trial-and-error in the real world (which is slow, costly, and potentially dangerous), an agent with a good world model can simulate thousands of action sequences internally and choose the best one.
Sample efficiency: Learning from real-world experience is expensive. A good world model can generate synthetic training data by simulating environment dynamics, dramatically reducing the need for real interactions.
Generalization: World models encode causal structure ("pushing objects moves them," "liquids flow downward"), which generalizes to new objects and environments in ways that behavior cloning alone cannot.
The World Model Taxonomy
The survey organizes world models along several key dimensions:
By Representation
Implicit world models: The "model" is embedded in the policy itself — the policy implicitly learns environment dynamics as part of learning behavior. DreamerV3 is the canonical example.
Explicit world models: A separate model explicitly predicts next states, separate from the action selection policy. This enables cleaner planning and easier interpretation.
Language-grounded world models: Using language models as the world model. LLMs encode rich commonsense knowledge about how the world works — "if you push a glass off a table it will fall and break" — which can be used for high-level planning even without precise physics simulation.
By Input Modality
Video prediction models: Predict future video frames from current frames and actions. Directly applicable to vision-based robot control.
State prediction models: Predict structured state representations (object positions, joint angles) rather than raw pixels. More efficient but requires state extraction.
Multimodal world models: Handle visual, tactile, proprioceptive, and language inputs — needed for dexterous manipulation where touch feedback is essential.
By Planning Horizon
Short-horizon (reactive): Predicting 1-10 steps ahead. Useful for obstacle avoidance, real-time control.
Long-horizon (deliberative): Predicting 100+ steps ahead. Necessary for complex manipulation tasks, navigation, household tasks.
Key Research Directions
Video Generation as World Models
Recent large-scale video generation models (Genie, WorldDreamer) can be fine-tuned for robotic domains. The ability to generate photorealistic videos of "what would happen if I push this object left" provides a rich world model without explicit physics simulation.
The challenge: video generation models are computationally expensive and don't naturally produce structured state representations that planning algorithms need. Converting between video and action space is non-trivial.
Language as World Model Prior
Large language models encode substantial commonsense physics — they "know" that glass is fragile, that balancing objects requires careful placement, that water seeks the lowest point. This knowledge can serve as a prior for world models, especially for high-level task planning.
The limitation: LLMs don't have precise physical intuitions. They can reason that "pushing a ball will make it move" but can't predict exactly how far or in what direction. Language world models work for high-level planning; physics simulation is still needed for precise manipulation.
Hierarchical World Models
The most promising architectural direction: world models that operate at multiple abstraction levels simultaneously.
flowchart TD
A[Task Instruction:\n'make a cup of tea'] --> B[High-Level World Model\nSubgoal planning\nSequence: fill kettle, boil, steep]
B --> C[Mid-Level World Model\nManipulation planning\nGrasp kettle, carry to sink, etc.]
C --> D[Low-Level World Model\nMotor control\nJoint angles, force modulation]
style B fill:#7c3aed,color:#fff
style C fill:#2563eb,color:#fff
style D fill:#059669,color:#fff
High-level world models plan in terms of objects and goals. Mid-level models plan in terms of manipulation primitives. Low-level models handle precise motor control. Each level plans within its abstraction and passes goals down to the level below.
The Survey's Critical Assessment
What I appreciate most about this survey is its honesty about limitations:
Current world models fail for contact-rich manipulation: Pushing, grasping, and inserting objects requires precise force prediction. Current learned world models predict geometry but not forces well. This limits their usefulness for the manipulation tasks that matter most in robotics.
Long-horizon consistency is poor: World models that predict accurately 5 steps ahead degrade badly at 50 steps. The compounding of prediction errors over long horizons is a fundamental limitation — small errors early become large errors later.
Generalization to novel objects is limited: World models trained on household objects don't automatically generalize to industrial settings. The distribution shift problem applies to world models as much as to policies.
Computational cost: Running a world model in the inner loop of planning is expensive. Real-time robot control with complex planning requires fast world models — an engineering challenge as significant as the research challenge.
Why This Matters for the Field
World models connect two communities that have historically operated separately: model-based reinforcement learning (which has the right theory but struggles with complex environments) and deep learning for robotics (which has empirical success but limited reasoning).
The survey's synthesis reveals that world models are becoming the shared technical infrastructure for embodied AI. Whether you're working on manipulation, navigation, household assistance, or industrial automation — world models that predict environment dynamics are the common thread.
The long-term vision: embodied AI systems that can be given a natural language description of a task, simulate many possible approaches using their world model, select the best approach, and execute it with physical precision. This vision requires all the components the survey maps — language grounding, multi-modal perception, hierarchical planning, contact-rich physics simulation.
My Take
This is a useful survey for anyone trying to understand where embodied AI is heading. The synthesis across video prediction, language models, and physics simulation is well done.
My opinion on the field: world models are necessary but not sufficient for general physical intelligence. The gap between simulating "pushing objects moves them" and successfully manipulating a real kitchen environment remains enormous. World models that work on tabletop manipulation in controlled lighting will fail on a factory floor with variable conditions and novel tool configurations.
The contact-rich manipulation limitation is the critical gap. Most practically important manipulation tasks — assembly, repair, food preparation, medical procedures — require precise force control that current world models don't handle. Solving this requires either dramatically better physics simulation or a fundamentally different approach to learning contact dynamics.
The survey would benefit from more discussion of safety implications. A world model that predicts incorrect dynamics can lead a robot to apply dangerous forces or make catastrophically wrong decisions. Uncertainty quantification in world models — knowing when the model doesn't know — is an underexplored research direction that should be a priority.
World models are the right foundation for physical intelligence. Getting them to work reliably in the real world is the work that remains.

Paper: "A Comprehensive Survey on World Models for Embodied AI", arXiv: 2510.16732, Oct 2025.
Explore more from Dr. Jyothi


