
Paper: Revisiting the Test-Time Scaling of o1-like Models: Do they Truly Possess Test-Time Scaling Capabilities? arXiv: 2502.12215 | February 2025
The test-time compute narrative has become one of the dominant themes of the AI industry entering 2025-2026. The premise: allow a model to think for longer, and it will produce better answers. More tokens = more reasoning = higher quality. OpenAI's o1 and o3 are built on this principle. DeepSeek-R1 validated it for verifiable domains. The s1 paper showed you can replicate it with 1,000 examples.
But is the premise actually true in general?
This paper asks the question that was inconvenient to ask while the industry was celebrating the new reasoning model paradigm. It runs controlled experiments on o1-like models across a carefully chosen evaluation suite and finds that the test-time scaling story is more limited than the marketing suggests — specifically: scaling works reliably on verifiable tasks with clear ground truth but degrades, plateaus, or sometimes inverts on tasks that are harder to verify.
This is an important paper. It is also, in my view, one of the most honest contributions to the reasoning model literature.
The Central Question
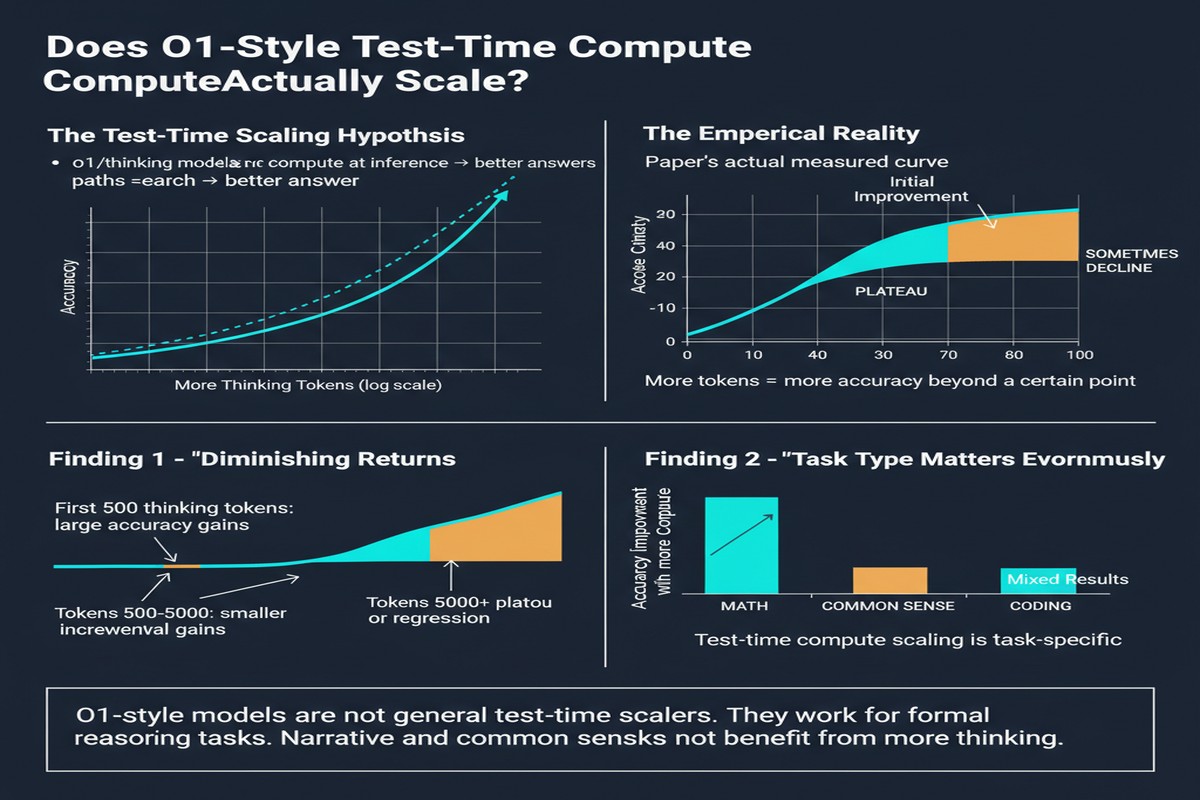
The claim of test-time scaling is: performance scales predictably with compute. More thinking tokens → better outputs. If this is true generally, the implication is transformative: you can always get a better answer by thinking longer, and the compute-quality tradeoff is a smooth, controllable dial.
The paper distinguishes two related but different claims:
- Weak test-time scaling: performance increases monotonically with compute up to some limit
- Strong test-time scaling: performance increases predictably and substantially across diverse task types
Most of the excitement has been about the strong form. This paper tests whether the strong form holds.
The Evaluation Design
The researchers evaluate o1-like models (using both published o1 variants and their own DeepSeek-R1-style models) across:
flowchart LR
A[Task Categories] --> B[Verifiable Tasks]
A --> C[Semi-Verifiable Tasks]
A --> D[Non-Verifiable Tasks]
B --> B1[Math competition]
B --> B2[Coding challenges]
B --> B3[STEM problem sets]
C --> C1[Structured reasoning]
C --> C2[Formal logic]
C --> C3[Multi-step planning]
D --> D1[Open-ended writing]
D --> D2[Complex reasoning]
D --> D3[Creative problem-solving]
style B fill:#4caf50,color:#fff
style C fill:#ff9800,color:#fff
style D fill:#f44336,color:#fff
For each task type, they measure performance as a function of allowed thinking tokens — effectively controlling the compute budget for reasoning.
What They Found
Verifiable tasks (green): strong scaling holds. On math competition problems, coding challenges, and STEM benchmarks, performance scales consistently with compute. More thinking tokens reliably produce better answers. This validates the core claim of DeepSeek-R1 and the s1 paper for this domain.
Semi-verifiable tasks (orange): scaling holds but weakens. On structured reasoning tasks with partial ground truth — formal logic, constrained planning — scaling behavior is less consistent. Performance improves with more thinking tokens in most configurations but shows more variance and occasional plateaus.
Non-verifiable tasks (red): scaling is unreliable. This is the uncomfortable finding. On open-ended writing, complex reasoning with no clear right answer, and creative problem-solving, longer thinking does not reliably produce better outputs. In some configurations, more thinking tokens produce outputs rated worse by human evaluators — the model overthinks, introduces unnecessary caveats, or generates sophisticated-sounding but less practically useful answers.
The "thinking too much" failure mode is particularly interesting. On tasks where the best answer is a direct, confident response, models trained to generate long reasoning chains can produce answers that are technically longer and more elaborated but are objectively less useful. The reasoning training optimizes for thinking-visible-to-the-verifier, which is not the same as thinking-useful-to-the-reader.
The Calibration Problem
A second finding is about calibration. o1-style models tend to express high confidence in their answers on both verifiable and non-verifiable tasks. But on verifiable tasks, confidence correlates with correctness (high-confidence answers are more often correct). On non-verifiable tasks, this correlation weakens significantly — the model is equally confident on outputs that human evaluators rate as excellent and as mediocre.
This miscalibration is concerning for deployment. If you're building a system that uses a reasoning model's confidence as a signal for when to escalate to human review, you can rely on that signal for math and code — but not for open-ended judgment tasks.
Why This Matters
1. The verifiable-vs-non-verifiable distinction is the most important boundary in AI deployment. This paper sharpens a boundary that practitioners have intuited but that the public discourse has not articulated clearly: reasoning model scaling works in domains with verifiable ground truth. For everything else, the scaling story requires much more skepticism.
2. RL training creates a verifiability bias. GRPO, PPO, and similar algorithms work by rewarding correct answers. This means the training signal is richest in verifiable domains. Models trained predominantly on verifiable tasks internalize reasoning patterns that are optimized for those domains — patterns that may not transfer to domains where "correctness" is harder to define.
3. The "more thinking = better" UX narrative is dangerous. o1 and o1-pro are marketed partly on the premise that "extended thinking" produces more reliable outputs. That narrative is accurate for math and code. If users extend this expectation to strategy, creative work, and judgment calls, they will be misled. The paper provides empirical grounding for a more nuanced user education message.
4. Calibration research deserves more investment. Knowing when a model is likely to be wrong is as valuable as making the model more right. The calibration findings here suggest that current reasoning models are poorly calibrated on non-verifiable tasks — a gap that needs to be addressed before these models are deployed for high-stakes judgment tasks.
My Take
I respect this paper for its willingness to complicate a comfortable narrative. The AI industry in 2025 was largely unified around the test-time scaling thesis, and questioning it was professionally awkward. The researchers ran the experiments anyway and reported honestly.
The finding about non-verifiable tasks matches my own operational experience. I've tested several o1-class models on strategic reasoning tasks — things like product strategy analysis, risk assessment, architectural tradeoffs — and observed the "overthinking" failure mode directly. The models produce impressive-sounding extended analyses that, when evaluated against expert judgment, are often less useful than a direct GPT-4 response. More thinking doesn't help when the problem doesn't have a ground truth to converge toward.
My interpretation of the findings: test-time compute scaling is a genuinely powerful technique for the domain it was designed for — verifiable, closed-form reasoning. The mistake is assuming it generalizes. We don't have a way to scale compute toward better open-ended judgment because we don't have a verifiable signal for what "better" means in that domain. Until we solve the reward signal problem for non-verifiable tasks, the scaling promise will remain domain-limited.
The practical implication for engineers: don't default to the longest-thinking model for every task. Use reasoning models for math, code, and structured problems. For writing, strategy, and complex judgment, the overhead of extended reasoning may not be warranted — and in some cases, a fast, direct model produces better outputs. Match the tool to the task type.
arXiv:2502.12215 — read the full paper at arxiv.org/abs/2502.12215


