Ask most AI hardware engineers about the bottleneck in transformer inference, and they'll tell you one of two things: either "the memory bandwidth" (for decode) or "the softmax in attention" (for long-context prefill). Both are right. And they're related: attention's softmax operation requires computing exponentials across the full context length, producing intermediate values that need to be stored and accessed — creating a nasty combination of compute-heavy and memory-intensive operations that GPUs aren't well-suited to handle.
HASTILY: Hardware-Software Co-Design for Accelerating Transformer Inference Leveraging Compute-in-Memory (arXiv:2502.12344) is a February 2025 paper that attacks this problem from an angle I haven't seen combined this elegantly before: a CIM architecture with novel compute units that handle both the computation and the memory access in the same physical structure.
The Problem HASTILY Solves
Let me be specific about the bottleneck. In multi-head attention:
- You compute Q, K, V projections (matrix-vector products — bandwidth-bound for decode, compute-bound for prefill)
- You compute attention scores: Q×Kᵀ scaled by √d — involves all K vectors in the context
- You apply softmax to the attention scores — requires exp() for each element, then normalization
- You weight V vectors by attention scores — another bandwidth-intensive operation
Step 3 is the problem child. Softmax requires:
- Computing exp(xᵢ) for all i — nonlinear, can't be fused with matrix ops trivially
- Finding the maximum value for numerical stability (a reduction over the full context)
- Normalizing by the sum of exponentials (another reduction)
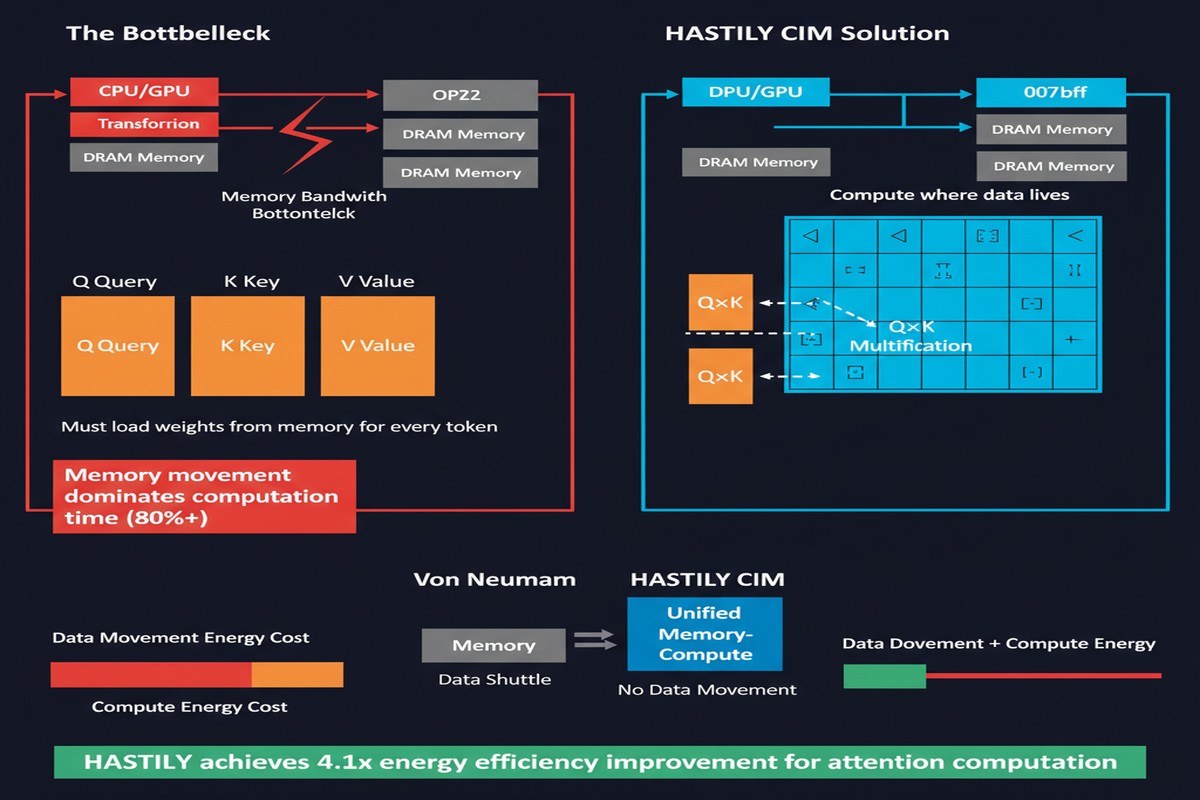
On GPUs, these reductions across the context dimension become bottlenecks as context length grows. FlashAttention and FlashAttention-2 addressed this brilliantly in software by fusing operations and minimizing HBM access. HASTILY addresses it in hardware.
The UCLM: One Unit, Two Jobs
The central innovation in HASTILY is the Unified Compute and Lookup Module (UCLM) — a custom CIM unit that integrates two capabilities in the same SRAM array:
Lookup functionality: The exponential function exp(x) is precomputed and stored as a lookup table within the SRAM array. Instead of computing exp(x) with dedicated arithmetic units, you read the value from the table — a single SRAM read, which is fast and energy-efficient.
Multiply-accumulate functionality: The same SRAM array can also execute multiply-accumulate operations directly, performing in-memory compute for the weighting step (attention scores × V vectors).
By co-locating both capabilities in one structure, HASTILY eliminates the data movement that would otherwise occur between separate compute and memory units. The softmax intermediate values never leave the SRAM — they're computed (via lookup), used for weighting, and consumed, all within the UCLM.
graph TD
subgraph UCLM["Unified Compute & Lookup Module (UCLM)"]
direction TB
A["SRAM Array"] --> B["Lookup Path\nexp(x) table read"]
A --> C["MAC Path\nIn-memory multiply-accumulate"]
B --> D["Softmax Numerator\nexp(qₖ·kᵢ/√d)"]
C --> E["Weighted V\nΣ aᵢ·vᵢ"]
D --> F["Normalization\n÷ Σexp(...)"]
F --> G["Attention Output"]
E --> G
end
H["Q, K, V Projections"] --> A
G --> I["FFN Layer"]
style A fill:#00d4ff,color:#000
style UCLM fill:#e8f4f8,color:#000
The Hardware-Software Co-Design
HASTILY doesn't just introduce new hardware — it co-designs the software stack to exploit the hardware's capabilities.
The compiler layer maps transformer operations to UCLM operations, deciding which computations use the lookup path, which use the MAC path, and how to schedule operations to maximize pipeline utilization. The key insight is that attention computation has a natural dataflow structure that maps efficiently to the UCLM's dual functionality:
- Lookup path: handles exp() in softmax and other nonlinear functions
- MAC path: handles all the weighted sums in attention and FFN layers
The paper analyzes the attention computation graph and shows that this mapping captures essentially all the computation in the attention block without requiring data to leave the SRAM array.
Why SRAM-Based CIM for Attention?
You might wonder: if HBM-PIM is good for weight operations (as in HPIM, which I covered earlier), why use SRAM-PIM for attention?
The answer is access pattern. HBM-PIM works well for large, regular weight matrices because HBM is designed for bulk sequential access. Attention's KV cache has irregular access patterns — in dynamic contexts, different tokens are accessed with different frequency, and long-context attention requires full random access across potentially millions of KV pairs. SRAM, with its lower latency and more flexible addressing, is the right memory technology for attention's access pattern.
HASTILY's design reflects a sophisticated understanding of which CIM technology matches which computation. This hardware-computation matching is the core systems insight.
The Results
The paper reports significant energy and area efficiency gains compared to GPU-based attention computation, with particular advantages for long-context inference where the softmax normalization step becomes increasingly expensive as context grows.
The energy efficiency of UCLM-based softmax is particularly notable: because the lookup path requires only an SRAM read (rather than exponential computation via FP32 arithmetic units), it consumes orders of magnitude less energy per activation than GPU-based softmax.
flowchart LR
A["Long Context\nInference\n(32K+ tokens)"] --> B{"Compute\nPath?"}
B -->|"GPU"| C["Exponential ops\non FP32 units\n+ HBM access\n= High energy"]
B -->|"HASTILY"| D["SRAM lookup\n+ in-memory MAC\n= Low energy"]
style C fill:#ff4444,color:#fff
style D fill:#00d4ff,color:#000
Why This Matters
The transformer architecture has dominated NLP and increasingly vision tasks since 2017. The attention mechanism at its core has well-known scaling challenges — O(n²) in context length for naive implementations, with heavy memory pressure even with FlashAttention optimizations.
Software has worked incredibly hard to mitigate this: FlashAttention (tiled attention computation), GQA (grouped-query attention), sliding window attention, sparse attention patterns. Each of these reduces the computational and memory cost of attention — but they're workarounds for a hardware-software mismatch.
HASTILY proposes fixing the hardware-software mismatch at the hardware level. By building CIM units that are specifically designed for attention's compute pattern, you make software workarounds less necessary. The underlying computation becomes efficient, not just the approximations.
This matters beyond just performance numbers. As models push toward million-token contexts (and they will — long-context reasoning is genuinely useful), attention becomes the dominant compute cost. A hardware architecture designed for attention is increasingly the right foundation.
My Take
I'm genuinely excited about HASTILY's architectural ideas, and I'll tell you exactly what I think is right and what needs more work.
What's right: The UCLM concept is elegant. Combining lookup and MAC in the same SRAM array eliminates a data movement bottleneck that is otherwise unavoidable. The hardware-software co-design philosophy — design the hardware to match the computation, design the compiler to exploit the hardware — is the correct approach for post-GPU AI acceleration.
What needs work: The paper evaluates HASTILY on relatively small context lengths and model sizes. The critical question for 2026-era models is: how does HASTILY scale to 128K+ context lengths and 70B+ parameter models? At those scales, the KV cache alone requires many gigabytes of SRAM — which simply doesn't fit in on-chip SRAM. You'd need to spill to HBM, partially defeating the purpose.
My opinion on the field: Papers like HASTILY represent the right direction for AI hardware — purpose-built compute units matched to the actual computational patterns of modern AI. The era of "just throw more FP32 units at it" is ending. The future is heterogeneous: different compute units (GEMM accelerators, attention-specific CIM units, softmax lookup units) working together, orchestrated by smart compilers that route operations to the right hardware.
HASTILY is a research paper demonstrating a concept, not a chip you can buy. But the concept is sound, and I'd expect to see UCLM-like structures appear in commercial AI accelerators within the next 2-3 years. Some form of hardened softmax support already exists in TPU v6e. The direction is clear.
The future of AI acceleration isn't one big chip. It's many specialized compute structures, connected by smart data flow.
References
- (2025). HASTILY: Hardware-Software Co-Design for Accelerating Transformer Inference Leveraging Compute-in-Memory. arXiv:2502.12344.