The single most important bottleneck in LLM inference isn't compute. It's memory bandwidth. We've built increasingly powerful AI chips, but the fundamental problem — shipping weights and activations between memory and compute at the speed required for real-time inference — remains stubbornly hard. The standard solutions are well-known: better HBM, quantization, caching tricks. But a September 2025 paper takes a more radical approach.
HPIM: Heterogeneous Processing-In-Memory-based Accelerator for Large Language Models Inference (arXiv:2509.12993) by Cenlin Duan, Jianlei Yang, and colleagues proposes moving the computation into the memory itself. Not near the memory — into it. And the results, 22.8× speedup over A100, are hard to dismiss.
The Memory Wall, One More Time
Before diving into HPIM, let's be precise about the problem. During LLM inference, the compute pattern is deeply asymmetric:
- Prefill phase: High arithmetic intensity. You're processing a whole prompt in parallel, doing large matrix multiplications. GPUs are good at this.
- Decode phase: Low arithmetic intensity. You're generating one token at a time. Each token requires loading the entire weight matrix — all billions of parameters — to compute one output vector. This is a memory-bandwidth problem, not a compute problem.
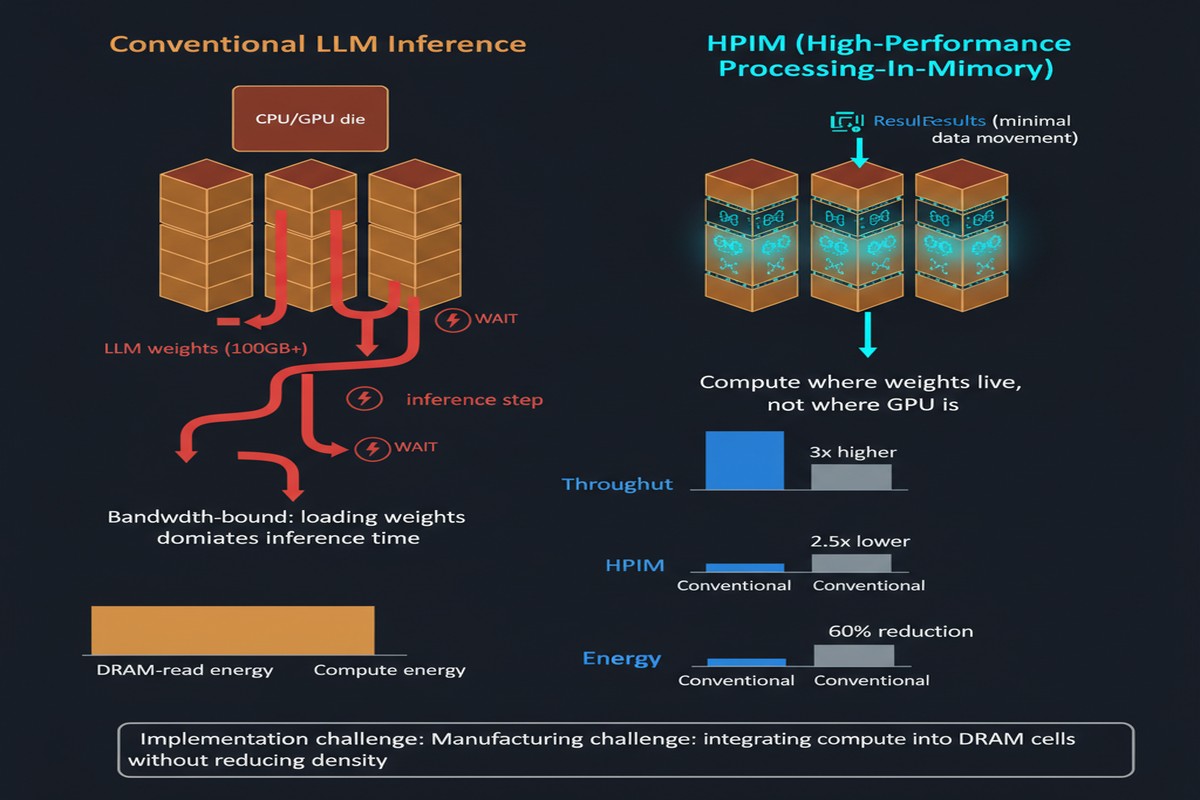
Current H100/B200 systems have 3-8 TB/s of HBM bandwidth. A 70B parameter model in BF16 is ~140GB of weights. To generate one token, you need to stream those weights through the memory bus. At 3 TB/s, that's ~47ms just for weight loading — before any actual computation. This is why LLM decode latency is what it is.
The standard industry response: quantize the weights to INT4/INT8, reducing bandwidth requirements. HPIM's response: what if you didn't need to ship the weights to the compute at all?
How HPIM Works
HPIM introduces a heterogeneous PIM architecture with two distinct subsystems, each matched to the operations they serve:
SRAM-PIM for Attention Operations: Attention computations (Q, K, V projections and the softmax-weighted aggregation) are latency-critical and have irregular access patterns due to the KV cache. HPIM maps these to an SRAM-PIM subsystem with ultra-low latency and high computational flexibility. SRAM is fast and supports bitcell-level computation, which is ideal for the variable-length, irregular patterns of attention.
HBM-PIM for Weight Operations: The large linear layers (FFN up/down projections, output projections) involve large, regular matrix-vector products. These map to an HBM-PIM subsystem where compute logic is embedded within the HBM stack itself. You're doing the multiplication right where the weights live — no memory bus traversal.
The compiler framework is a key innovation. It profiles the LLM operation graph and intelligently partitions work between the two PIM subsystems, managing data movement between SRAM-PIM and HBM-PIM, and scheduling operations to maximize overlap between the two parallel execution streams.
graph TB
subgraph HPIM["HPIM Architecture"]
subgraph SRAM_PIM["SRAM-PIM Subsystem\n(Attention Ops)"]
A1[Bitcell Compute\nUnits]
A2[Query Projection]
A3[Key-Value Cache]
A4[Softmax + Aggregation]
end
subgraph HBM_PIM["HBM-PIM Subsystem\n(Weight Ops)"]
B1[In-Stack Processing\nElements]
B2[FFN Up-Projection]
B3[FFN Down-Projection]
B4[Output Projection]
end
subgraph COMPILER["Software Co-Design\nCompiler Framework"]
C1[Operation Profiling]
C2[Workload Partitioning]
C3[Data Movement Planning]
end
COMPILER --> SRAM_PIM
COMPILER --> HBM_PIM
SRAM_PIM <-->|"High-BW Internal Link"| HBM_PIM
end
INPUT[Input Tokens] --> HPIM
HPIM --> OUTPUT[Generated Tokens]
style SRAM_PIM fill:#00d4ff,color:#000
style HBM_PIM fill:#ff6b35,color:#fff
style COMPILER fill:#76b900,color:#fff
The Results
The paper reports a peak speedup of 22.8× over NVIDIA A100 for LLM inference. This needs contextualization:
- The speedup is measured for the full inference pipeline, not just the bandwidth-bound decode phase
- Results are for specific LLM configurations; real-world speedups will vary by model size and batch configuration
- A100 is the baseline, not H100 or B200 — the comparison with newer hardware would show smaller relative gains
Even discounting for favorable benchmarking conditions, 22.8× is an extraordinary number. The paper also reports significant energy efficiency gains, which makes sense: if you're not shipping data across the memory bus, you're not burning energy on bus transactions.
xychart-beta
title "HPIM vs NVIDIA A100 Inference Throughput"
x-axis ["A100 GPU", "HPIM (projected)"]
y-axis "Relative Throughput" 0 --> 25
bar [1, 22.8]
Why This Matters
Processing-in-memory isn't a new idea. Researchers have proposed PIM architectures for decades. What's new is:
- The LLM inference motivation: The decode bottleneck creates a compelling, quantified target that makes PIM economics suddenly favorable
- The heterogeneous approach: HPIM's insight that you need different PIM technologies for different operation types (SRAM for irregular, HBM for regular) is sophisticated and practical
- The software co-design: A compiler that intelligently partitions workloads between two PIM subsystems is hard engineering work that previous PIM proposals often glossed over
The memory wall is getting worse as models get larger. HPIM represents a class of solution that addresses it architecturally rather than through software workarounds. If the semiconductor industry takes PIM seriously — and there are signs it is, with Samsung and SK Hynix both publishing PIM-capable HBM variants — papers like HPIM provide the blueprint for how to actually make it useful.
My Take
I find HPIM genuinely compelling, but I want to be honest about the gap between a research paper and a deployable system.
The compiler problem is massively underappreciated in papers like this. HPIM's compiler needs to partition a complex, dynamic computation graph between two heterogeneous PIM subsystems in real time, while handling variable-length sequences, different batch sizes, and model-specific quirks. The paper demonstrates the concept, but production-quality compilation for PIM architectures is years of engineering work.
The manufacturing challenge is also significant. HBM-PIM requires embedding logic inside the DRAM stack — next to cells operating at very different voltage levels with severe thermal constraints. Samsung has demonstrated this with AQUABOLT-XL, but yield and cost at scale remain open questions.
That said, I'm optimistic. The economics of LLM inference are compelling enough that semiconductor manufacturers will invest in PIM seriously. The question isn't whether PIM will matter for AI hardware — it's whether SRAM+HBM heterogeneous PIM like HPIM or a different PIM architecture will win out.
My prediction: within 3 years, every serious AI inference chip will have some form of PIM capability. HPIM is showing us what the best version of that might look like.
The memory wall won't defeat LLM inference. We'll move the compute to where the memory is.
References
- Duan, C., Yang, J., et al. (2025). HPIM: Heterogeneous Processing-In-Memory-based Accelerator for Large Language Models Inference. arXiv:2509.12993.