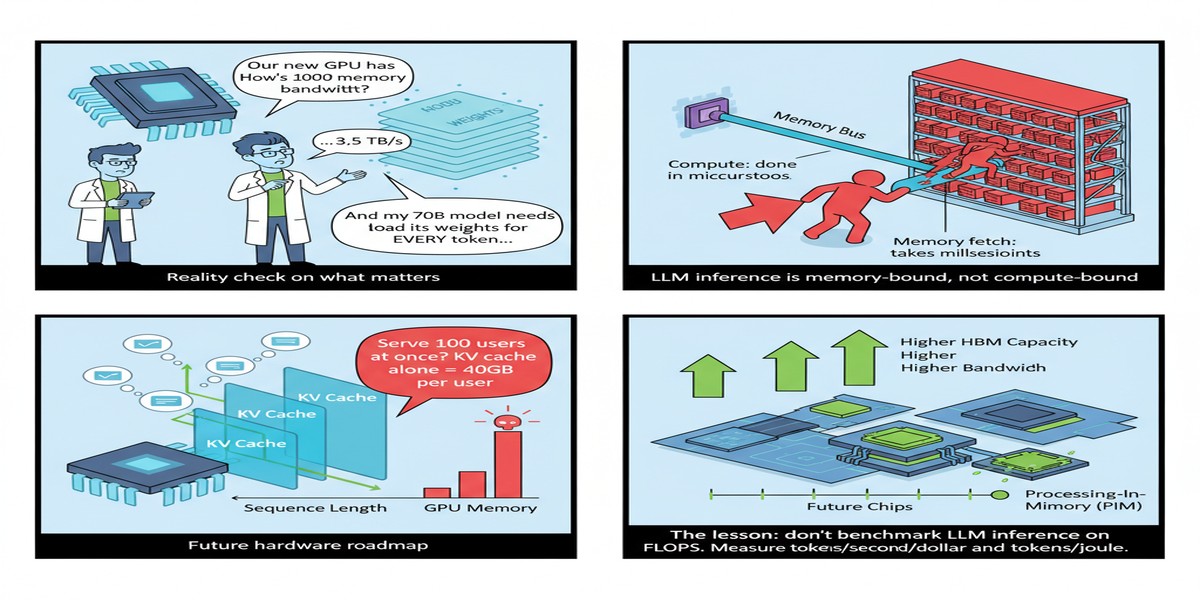
Every now and then, the field produces a paper that isn't about a single breakthrough but about the landscape — where we are, where the walls are, and what paths might lead through them. Challenges and Research Directions for Large Language Model Inference Hardware (arXiv:2601.05047), published in January 2026, is that paper for AI inference hardware. I read it with the attention I normally reserve for papers with flashier headlines, because this kind of structured roadmap is genuinely rare and valuable.
The authors map out the fundamental constraints on LLM inference hardware with specificity and intellectual honesty. This is the kind of paper that people will cite in grant proposals and chip design documents. Let me walk you through what they find and what I think it means.
The Three Walls
The paper organizes the fundamental constraints on LLM inference hardware around three interconnected walls:
1. The Bandwidth Wall
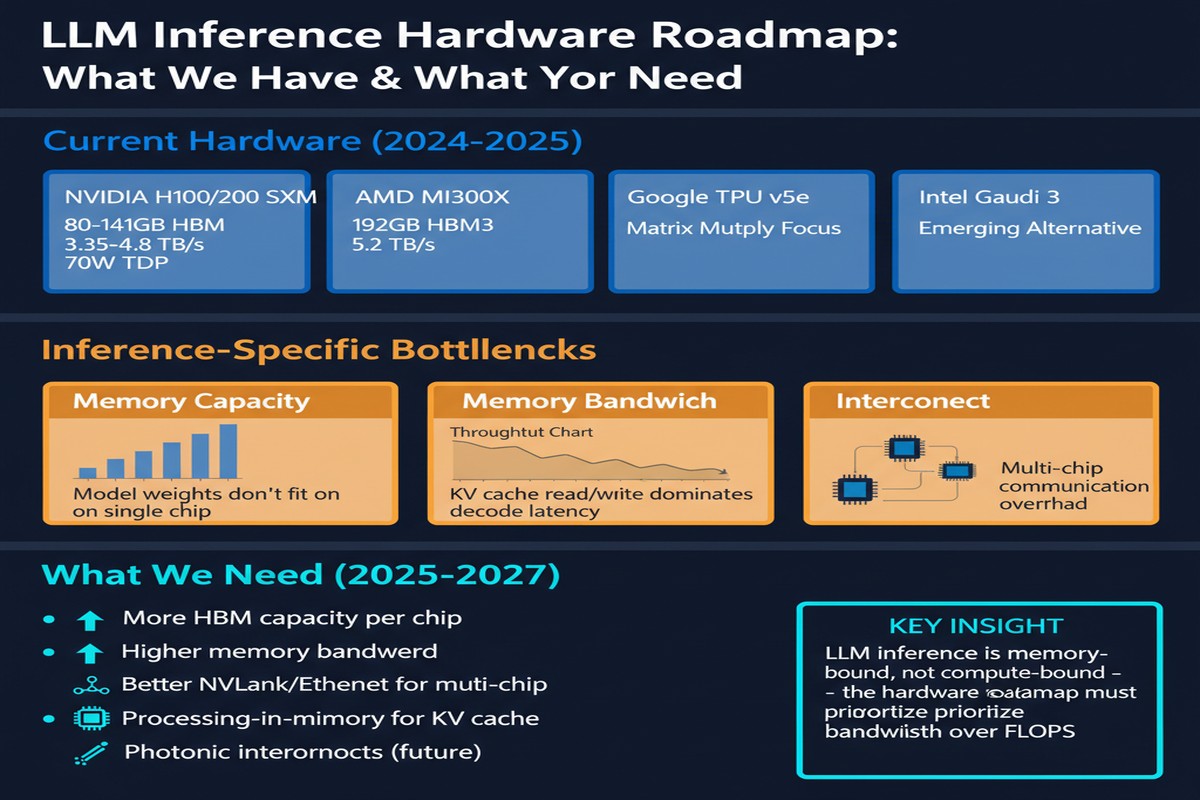
This is the most well-understood bottleneck. LLM decode is dominated by GEMV operations where you load billions of weights to compute one output vector per token. Current HBM3 provides ~3.35 TB/s bandwidth; HBM3e (in H200/B200) pushes ~8 TB/s; projected HBM4 may reach ~12-15 TB/s.
But here's the cold calculation: a 70B model in BF16 is 140GB. To generate one token in 10ms (100 tokens/second), you need to stream all 140GB through the memory bus in 10ms — requiring 14 TB/s. Current HBM can't sustain that without batching (which increases latency). HBM4 barely meets it for 70B. For 400B+ models? No current or near-term memory technology closes the gap.
The paper is honest about this: the bandwidth wall is a physics constraint, not an engineering choice. The DRAM cell physics limits how fast you can read data. You can put more DRAM dies in a stack (3D NAND-style), but each die has access latency and power constraints that limit how aggressively you can scale bandwidth.
graph LR
subgraph BandwidthWall["Bandwidth Wall vs Model Demands"]
A["HBM3: 3.35 TB/s"] --> B["70B model @ 100 tok/s\nNeeds ~14 TB/s"]
C["HBM3e: 8 TB/s"] --> D["70B model @ 57 tok/s\nBaseline only"]
E["HBM4: ~15 TB/s"] --> F["70B model @ ~100 tok/s\nNeeds full utilization"]
G["400B model @ 100 tok/s\nNeeds ~80 TB/s"] --> H["Beyond near-term\nHBM roadmap"]
end
style H fill:#ff4444,color:#fff
style G fill:#ff6b35,color:#fff
style F fill:#76b900,color:#fff
2. The Capacity Wall
Bandwidth and capacity are related but distinct problems. Even if you could stream 70B weights at the required rate, you need to store them somewhere accessible. Current GPU memory configurations:
- H100 SXM5: 80GB HBM3
- H200: 141GB HBM3e
- B200: 192GB HBM3e
- GB200 (2-die): 384GB HBM3e
A 70B model in BF16: 140GB. Fits on H200 (barely, with little room for KV cache). Fits on B200/GB200 with room for KV cache. A 400B model in BF16: ~800GB. Requires 4+ GB200s and NVLink for model parallelism.
The capacity wall creates a forcing function toward quantization. If you quantize 70B to INT4 (35GB), it fits on an H100 with 45GB left for KV cache. But INT4 has quality costs — particularly on reasoning-heavy tasks — and the industry is still working out the quality-efficiency frontier.
3. The Latency Wall
The bandwidth and capacity walls interact to create a latency wall for single-user, low-batch inference. Batching is the standard GPU solution for improving throughput: instead of serving one user at a time, serve 32 simultaneously, amortizing the weight loading cost across multiple useful outputs.
But batching increases per-user latency. If you're building a conversational AI where users expect responses in <100ms, batching has hard limits. Low-batch inference is memory-bandwidth-limited in a way that large-batch inference isn't, and current hardware is poorly optimized for this regime.
Proposed Research Directions
The paper maps out several research directions for addressing these walls. I'll highlight the ones I find most compelling:
3D Stacking and HBM Advances
HBM4, projected for 2025-2026 production, represents the next step in the known memory roadmap. The paper also discusses more speculative options: 3D-stacked SRAM (fast but expensive and capacity-limited), CXL memory expansion (adds remote memory capacity with higher latency), and near-memory processing (compute logic embedded in the memory stack).
The key finding: no single memory technology closes the bandwidth gap for frontier-scale models. The paper argues for heterogeneous memory systems that combine HBM (high bandwidth, limited capacity) with high-density DRAM (lower bandwidth, higher capacity) and on-chip SRAM caching, managed by intelligent hardware-software co-designed controllers.
Processing-Near-Memory (PNM) and PIM
The paper dedicates significant attention to PNM/PIM approaches — a clear signal that the research community sees these as the most promising direction beyond HBM scaling. The analysis matches what I described in my HPIM piece: SRAM-PIM for irregular, latency-sensitive operations; HBM-PIM for regular, bandwidth-intensive weight operations.
Critically, the paper identifies the compiler and programming model problem as the key challenge: PIM hardware requires fundamentally different code generation than GPU-style CUDA kernels. Until there are mature compilers that can automatically map LLM inference graphs to PIM hardware, PIM will remain a research topic rather than a production tool.
Sparsity and Structured Computation
The paper highlights sparsity exploitation as a hardware research direction with high potential. Modern LLMs exhibit significant activation sparsity (many neurons output near-zero values) that isn't currently exploited by production hardware. NVIDIA's sparse tensor cores (A100/H100) address weight sparsity but not activation sparsity. Designing hardware that dynamically exploits activation sparsity during inference could yield substantial efficiency gains without model quality degradation.
flowchart TD
A["LLM Inference\nHardware Challenges"] --> B["Bandwidth Wall"]
A --> C["Capacity Wall"]
A --> D["Latency Wall"]
B --> E["PNM/PIM Research\nHBM4/5 Roadmap"]
B --> F["3D Stacking\nAdvanced HBM"]
C --> G["Quantization\nINT4/INT8"]
C --> H["Model Architecture\nMoE, Sparse"]
D --> I["Batching Strategies\nContinuous Batching"]
D --> J["Speculative Decoding\nParallel Inference"]
E --> K["Hardware Platform\nRequirements"]
F --> K
G --> K
H --> K
I --> K
J --> K
style A fill:#ff6b35,color:#fff
style K fill:#76b900,color:#fff
Why This Matters
This paper matters because the AI hardware community needs an honest assessment of where the limits are. Too many papers propose solutions to specific bottlenecks without acknowledging the system-level constraints that make those solutions difficult to deploy.
The authors don't do this. They're clear that:
- HBM scaling alone can't close the bandwidth gap for frontier models
- PIM/PNM is promising but has a maturation timeline of years, not months
- Quantization is the most practical near-term solution but has quality ceilings
- No single technology "solves" the inference hardware problem — it requires a portfolio of complementary advances
My Take
I have a somewhat contrarian take on where the AI hardware field is headed.
The paper's analysis correctly identifies the bandwidth wall as the fundamental constraint. But I think the industry is about to make a mistake that the paper hints at but doesn't state directly: we're going to keep building bigger, more expensive GPU clusters when the right solution is smaller, more efficient specialized hardware at scale.
The economics of inference are different from the economics of training. Training is done once; you amortize the compute cost over millions of inferences. Inference happens continuously, 24/7. For most production use cases, inference efficiency matters far more than training efficiency. Yet the industry's R&D investment is heavily skewed toward training-optimized hardware (large H100/B200 clusters) because that's where the research community is, and research drives purchase decisions.
The paper identifies PIM and 3D stacking as the right research directions. I agree. But I'd add: we need a corresponding shift in research focus toward inference-optimized hardware at the 50W-200W power range. The TerEffic paper I covered earlier shows that 46W FPGAs can outperform A100s for specific inference workloads. HPIM shows that PIM can achieve 22.8× A100 speedups. The research directions the field needs are increasingly clear.
What's not clear is whether the investment will follow. The CUDA ecosystem's gravitational pull is enormous. Every engineer at every AI company knows how to write CUDA. The path of least resistance is to buy more H100s and be done with it.
I hope this paper — and the broader body of work it synthesizes — shifts the conversation. The memory wall is real. It's physics. We need hardware designed around it, not hardware that pretends it doesn't exist.
References
- (2026). Challenges and Research Directions for Large Language Model Inference Hardware. arXiv:2601.05047.