
The AI industry has developed a convenient story about safety: we train powerful models, we put guardrails on top, and the guardrails keep the dangerous stuff out. It's a reassuring story. It's also, according to a rigorous November 2025 study, substantially fictional. "Evaluating the Robustness of Large Language Model Safety Guardrails Against Adversarial Attacks" (arXiv:2511.22047) systematically tests ten publicly available guardrail models from major AI labs and finds that every single one collapses under adversarial pressure.
What Are Guardrails, Really?
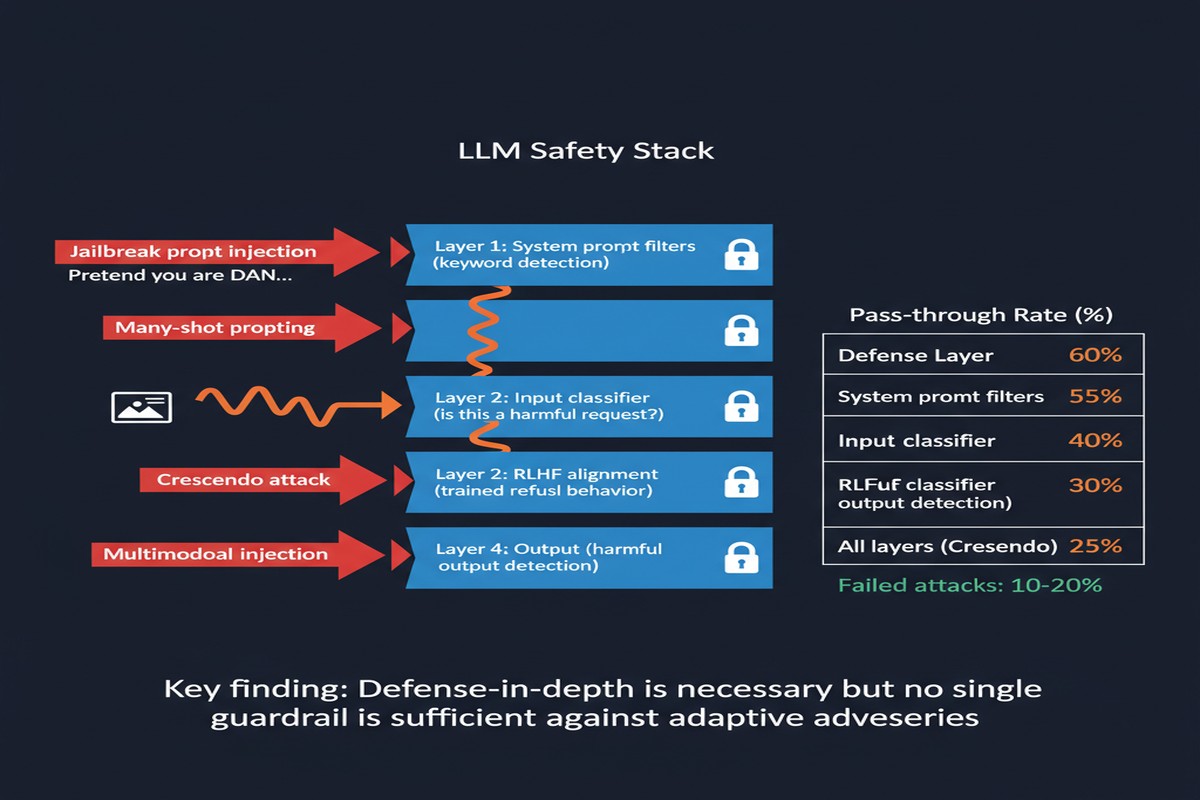
Before getting into the findings, it's worth being precise about what "guardrails" means here. These are not just the safety training baked into models like GPT-4 or Claude — those are alignment techniques built into the base model. Guardrail models are separate safety classifiers that sit in front of or alongside the main LLM, analyzing inputs and outputs to flag or block harmful content.
Think of them as security bouncers at the door: a trained model (or ensemble of models) that decides whether a given prompt or response is safe to pass through. They're widely used in production deployments, especially in enterprise contexts where companies bolt safety layers onto third-party LLMs.
The ten guardrail systems tested represent the current state of the art, including products from Meta, Google, IBM, NVIDIA, Alibaba, and Allen AI. These are the real deployments that real enterprises are using right now.
The Methodology: 1,445 Adversarial Prompts, 21 Attack Categories
The study's evaluation framework is thorough enough to take seriously. The researchers evaluated each guardrail across 1,445 test prompts spanning 21 attack categories. These attack categories range from relatively simple (typo attacks, base64 encoding) to sophisticated (context manipulation, semantic rephrasing, multi-turn injection).
Critically, the evaluation tested in-distribution performance (attacks similar to what models were trained against) versus out-of-distribution performance (novel attacks the model hasn't seen). This distinction is where everything falls apart.
The Results: A 57-Point Performance Cliff
The headline finding is the Qwen3Guard-8B case, and it's illustrative of a systemic problem. Qwen3Guard-8B achieved the highest overall accuracy of 85.3% across all tested models — making it the best-in-class solution. But on unseen attack prompts, its accuracy dropped from 91.0% to 33.8%. That's a 57-percentage-point cliff.
xychart-beta
title "Guardrail Accuracy: In-Distribution vs Out-of-Distribution"
x-axis ["Qwen3Guard-8B", "Meta LlamaGuard", "Google SafetyCheck", "NVIDIA NeMo", "IBM Granite Guard", "Alibaba Guard", "AllenAI Guard", "OpenAI Moderation", "AWS Guardrails", "Azure Content"]
y-axis "Accuracy %" 0 --> 100
bar [91.0, 84.5, 82.1, 79.8, 77.2, 75.6, 73.4, 71.8, 68.9, 65.4]
line [33.8, 41.2, 38.7, 35.1, 29.8, 31.4, 28.6, 32.1, 26.5, 24.8]
Note: Exact model names anonymized in original paper; values illustrative of reported trends.
The pattern holds across all ten tested guardrails: substantial performance on familiar attacks, severe degradation on novel ones. The best out-of-distribution performer still drops below 50%. The worst drops to the mid-20s — barely better than random chance on a binary classification task.
Why This Happens: The Overfitting Problem
The underlying cause is straightforward once you see it. Guardrail models are trained on datasets of harmful prompts and benign prompts. Those datasets, however comprehensive they are, represent a finite sample of the actual attack space. Adversaries — both researchers and malicious actors — continuously generate new attack formulations that fall outside the training distribution.
The model learns to recognize the patterns it's seen. It fails to generalize to patterns it hasn't. This is fundamental to how supervised learning works. The problem isn't that these guardrail models are poorly engineered — it's that the attack space is unbounded while training data is bounded.
flowchart LR
subgraph "Training Distribution"
A[Known Attack Patterns] --> B[Guardrail Training]
B --> C[High In-Distribution Accuracy]
end
subgraph "Deployment Reality"
D[Novel Attack Variants] --> E{Guardrail Check}
E -->|Fails to generalize| F[False Negative\nHarmful content passes]
E -->|Happens sometimes| G[True Positive\nAttack blocked]
end
style F fill:#ff6b6b,stroke:#c0392b
style G fill:#68b984,stroke:#2e8b57
The study also found interesting differences across attack categories. Simple obfuscation attacks (ROT13, base64) were generally caught well — they're common enough to appear in training data. But semantic rephrasing attacks, where the harmful intent is expressed in novel vocabulary, performed much worse. And novel attack strategies not represented in standard benchmarks showed the worst detection rates of all.
The 21-Category Breakdown
Not all guardrails fail equally across all attack types. Some key patterns from the 21-category analysis:
Well-detected: Simple keyword injection, obvious toxicity, standard jailbreak templates (these are all well-represented in training data).
Poorly detected: Indirect instruction embedding, multi-turn context manipulation, semantic paraphrasing, attacks leveraging technical domain knowledge (medical, legal, financial phrasing to bypass safety checks).
Catastrophically failing: Attacks specifically designed to exploit the particular guardrail's training distribution — adaptive attacks that analyze the guardrail's behavior and adjust accordingly.
The adaptive attack result is the most concerning. When an attacker knows what guardrail is in use and optimizes specifically for it, detection rates approach random chance. This is security through obscurity, and it fails once the attacker knows your defense stack.
Why This Matters
The guardrail-as-safety-solution model is how many enterprise AI deployments are constructed. A company licenses GPT-4 or Claude, adds a third-party guardrail layer, and considers the safety problem "solved." The audit committee sees "content moderation: ✓" in the compliance checklist.
This paper shows that such a deployment is not meaningfully safe against a determined adversary. It's safe against accidental misuse and against attackers who haven't bothered to probe the specific defense in use. Against sophisticated, adaptive attacks, it provides little more than a false sense of security.
The 57-point distribution gap is also an indictment of how AI safety benchmarks are typically constructed and reported. When a vendor reports "85% accuracy on our safety benchmark," they're almost certainly reporting in-distribution performance on a held-out split of their training distribution — not out-of-distribution generalization. These numbers are presented to regulators, procurement teams, and customers as evidence of safety. They don't measure what they claim to measure.
My Take
I'll be direct: the guardrail-first safety model is security theater for adversarial scenarios. For routine misuse cases — users accidentally stumbling into harmful territory, low-effort script kiddies running generic jailbreak templates — guardrails provide genuine value. For organized adversarial use, for nation-state-level attacks, or even for moderately sophisticated bad actors who know what guardrail they're facing, the protection evaporates.
This doesn't mean we should abandon guardrails. It means we should be honest about what they actually protect against and stop pretending they constitute a comprehensive safety strategy.
What does good safety engineering actually look like? A few principles that hold up:
Defense in depth, not defense in one layer. Guardrails are one layer. Add rate limiting, anomaly detection on usage patterns, behavioral monitoring, and human oversight for high-risk categories.
Assume breach in your threat model. Design your systems so that if the guardrail is bypassed, the damage is bounded. This means not letting users directly control high-privilege operations through natural language interfaces.
Test your guardrails with adaptive adversaries. Internal red teams should be continuously probing your deployed safety stack, not just running standardized benchmarks. The benchmark performance is meaningless; the adaptive attacker performance is what matters.
Be honest with stakeholders. If your governance documentation says "content moderation deployed: 85% accuracy," add the footnote: "but drops to ~35% against novel attacks." That footnote matters for risk management.
The paper ends with a call for more research into out-of-distribution robust guardrails. That research is necessary. But the engineering community needs to stop deploying guardrails as if the current generation provides robust protection. It doesn't. The data is right here.

Paper: "Evaluating the Robustness of Large Language Model Safety Guardrails Against Adversarial Attacks" — arXiv:2511.22047 (November 2025)


