
Sometime in the last two years, AI systems crossed a threshold. They stopped being answer machines and became action machines. An agent that can search the web, write files, call APIs, execute terminal commands, and then decide what to do next based on the results isn't just generating text — it's operating in the world. And systems that operate in the world can be attacked in ways that passive text generators cannot.
"Agentic AI Security: Threats, Defenses, Evaluation, and Open Challenges" (arXiv:2510.23883, October 2025) is the field's attempt to systematize what that actually means. It's essential reading for anyone building or deploying autonomous AI systems — which, increasingly, is everyone in software engineering.
What Makes Agentic AI Different from LLMs
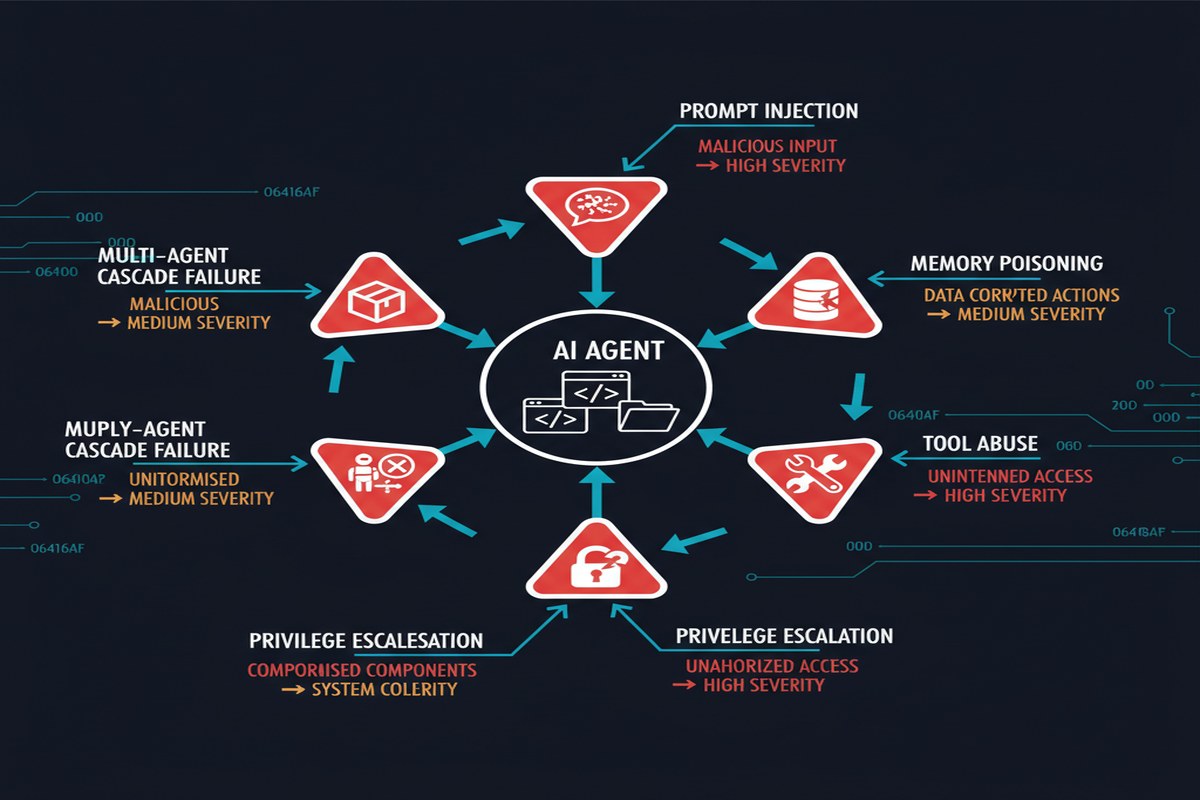
The security community spent years studying LLM security: jailbreaking, prompt injection, training data extraction. That work isn't obsolete, but agentic systems introduce attack dimensions that don't exist for purely generative models:
Persistent state: Agentic systems maintain memory across interactions. A compromised state can persist and affect future decisions, unlike a stateless LLM query.
Real-world actions with real-world consequences: When an agent writes a file, sends an email, deploys code, or transfers funds, the attack doesn't just produce bad text — it produces bad outcomes in the physical or digital world.
Tool ecosystems and trust chains: Agents call tools, which call other services, which may call other agents. Each hop in this chain is a potential injection or compromise point.
Multi-agent collaboration: Enterprise deployments increasingly use networks of specialized agents coordinating on complex tasks. An attacker who compromises one agent in the network can potentially propagate influence across the whole system.
Extended execution windows: Agents run for minutes, hours, or indefinitely. An adversary who can influence early decisions in a long-running agent shapes all subsequent decisions — a form of temporal leverage that doesn't exist in single-shot queries.
The Threat Taxonomy
The paper's primary contribution is a structured taxonomy of threats to agentic systems. It's worth walking through systematically because the completeness is what makes it useful:
mindmap
root((Agentic AI\nThreats))
Input Attacks
Direct Prompt Injection
Indirect Injection via Tools
Goal Hijacking
Context Manipulation
Memory Attacks
Memory Poisoning
Memory Extraction
Cross-Session Contamination
Tool/Action Attacks
Tool Misuse via Injection
Unauthorized Action Execution
Resource Abuse
Side-Channel Exfiltration
Multi-Agent Attacks
Agent Impersonation
Trust Chain Exploitation
Cascading Compromise
Training-Time Attacks
Data Poisoning
Backdoor Insertion
Fine-tuning Manipulation
Each category has distinct characteristics and requires distinct defenses. This is the first paper I've seen that treats these as a coherent system rather than isolated attack types.
The Sandbox Problem
One of the paper's most practically important sections deals with execution sandboxing. The finding here is bleak: most production agentic deployments don't use adequate sandboxing.
The researchers demonstrate an experiment with a Bash-based agent: without sandboxing, over 75% of malicious commands injected via prompt injection execute successfully. With container-based sandboxing (Docker, gVisor-style isolation), nearly all such commands are blocked.
The math is obvious. The adoption isn't happening fast enough. Why? Because sandboxing introduces friction. An agent in a container can't freely access the developer's home directory, can't call arbitrary system binaries, can't write to arbitrary paths. These restrictions make agents less capable of the open-ended tasks users want them to perform.
This creates a genuine security-capability tradeoff:
%%{init: {'quadrantChart': {'chartWidth': 500, 'chartHeight': 400, 'pointLabelFontSize': 12, 'quadrantLabelFontSize': 13}}}%%
quadrantChart
title Agent Capability vs Security Isolation
x-axis Low Security --> High Security
y-axis Low Capability --> High Capability
quadrant-1 Ideal
quadrant-2 Typical Today
quadrant-3 Over-Restricted
quadrant-4 Safe but Limited
"No sandbox": [0.15, 0.88]
"Full container": [0.9, 0.3]
"Capability-scoped": [0.7, 0.7]
"Read-only": [0.8, 0.4]
"Network-isolated": [0.6, 0.6]
The paper argues — correctly — that the industry needs capability-scoped sandboxes: isolation architectures that restrict what an agent can do based on what it's supposed to do, rather than just blanket container boundaries. An agent whose job is to analyze code should have filesystem read access to the repository and no other capabilities. This is the principle of least privilege applied to AI agents, and it's largely not implemented today.
Multi-Agent Trust Chains
The multi-agent section deserves special attention. As orchestration frameworks (LangGraph, AutoGen, CrewAI, and dozens of others) gain adoption, multi-agent systems are becoming common. These systems have a critical trust problem.
When Agent A delegates a subtask to Agent B, how does Agent B know the instruction is legitimate? In most current implementations: it doesn't. There's no cryptographic attestation of message provenance. Agent B trusts Agent A's messages because they arrive on an expected channel, which means any attacker who can inject into that channel can impersonate orchestrating agents.
The paper documents attacks where a compromised sub-agent convinced its orchestrator to escalate privileges, exfiltrate data, or approve actions the orchestrator would normally reject — by crafting responses that mimicked the expected format of legitimate task completion reports.
This is the AI equivalent of confused deputy attacks in operating systems. And unlike the OS world, where decades of work has produced robust privilege separation mechanisms, the multi-agent AI world has almost none.
Evaluation Frameworks and Open Challenges
The paper's review of existing evaluation frameworks for agentic security is sobering. Most existing benchmarks (AgentBench, WebArena, SWE-bench) test capability, not security. There are almost no standardized benchmarks for measuring the security properties of agentic systems.
The authors identify several open challenges that I think deserve the field's attention:
No standardized agentic threat modeling language: Security teams can't coherently talk about agentic threats without shared vocabulary. The paper's taxonomy is a start.
No certified isolation standards: Unlike web sandboxes (which have developed into robust standards over decades), there's no equivalent for AI agent execution environments.
No reliable instruction/data separation: The fundamental LLM vulnerability — inability to distinguish trusted instructions from untrusted data — remains unsolved at the architectural level.
No provenance tracking for agent actions: When an agent takes an action, there's typically no tamper-evident record of what context drove that decision. Forensics after an incident is nearly impossible.
Why This Matters
We are in the early phase of what will likely be remembered as the agentic AI era. The frameworks being built now, the trust assumptions being encoded now, the security practices (or lack thereof) being normalized now — these will become the foundations that future systems build on.
The window to establish good security norms is narrow. Once agentic AI systems are deeply embedded in enterprise infrastructure, once they're managing real assets and making real decisions at scale, the cost of retrofitting security is enormous. We have a brief opportunity to get the foundations right.
This paper provides the conceptual vocabulary to have that conversation. What it cannot provide is the organizational will to act on it.
My Take
The threat taxonomy in this paper is excellent and I'll be using it in my own security reviews. But I want to highlight what I think is the single most underappreciated finding: the multi-agent trust chain problem.
Everyone in the field is focused on "can I jailbreak the LLM?" as the primary security question for AI agents. That's too narrow. The more dangerous question is "can I compromise the agent's decision-making by controlling the messages it receives from other agents?" In a world of multi-agent systems, the answer is frequently yes, with trivial effort, because message provenance isn't verified.
My argument to engineering teams deploying multi-agent systems: treat inter-agent messages with the same skepticism you'd apply to messages from untrusted external systems. That means:
- Validate that orchestrator messages have the expected format and scope
- Don't escalate to capabilities not granted in the original task specification, even if asked by an "orchestrating agent"
- Log all inter-agent messages with sufficient context for forensic reconstruction
- Build kill switches at each agent level, not just at the orchestrator
The paper frames agentic AI security as an "open challenge." That's accurate. But "open challenge" should not become an excuse for not acting on the substantial knowledge we already have. The 75% uninstructed command execution rate in unsandboxed deployments isn't an open challenge — it's a known problem with a known solution that we're choosing not to implement. That choice has consequences.
Paper: "Agentic AI Security: Threats, Defenses, Evaluation, and Open Challenges" — arXiv:2510.23883 (October 2025)


