
There is a frustrating asymmetry in AI security research: attack papers routinely present stunning results, while defense papers offer incremental improvements at massive compute cost. The jailbreaking literature is full of attacks that generalize easily; defenses tend to be brittle, expensive to train, and quick to fail under novel attack formulations.
"Short-length Adversarial Training Helps LLMs Defend Long-length Jailbreak Attacks: Theoretical and Empirical Evidence" (arXiv:2502.04204, February 2026) is a welcome exception to this pattern. It presents both a theoretical result and empirical validation of a non-obvious claim: to build robust defenses against long adversarial suffixes, you only need to train against short ones. The compute savings are substantial. The result is cleaner and more generalizable than most defense work I've seen.
The Jailbreak Suffix Problem
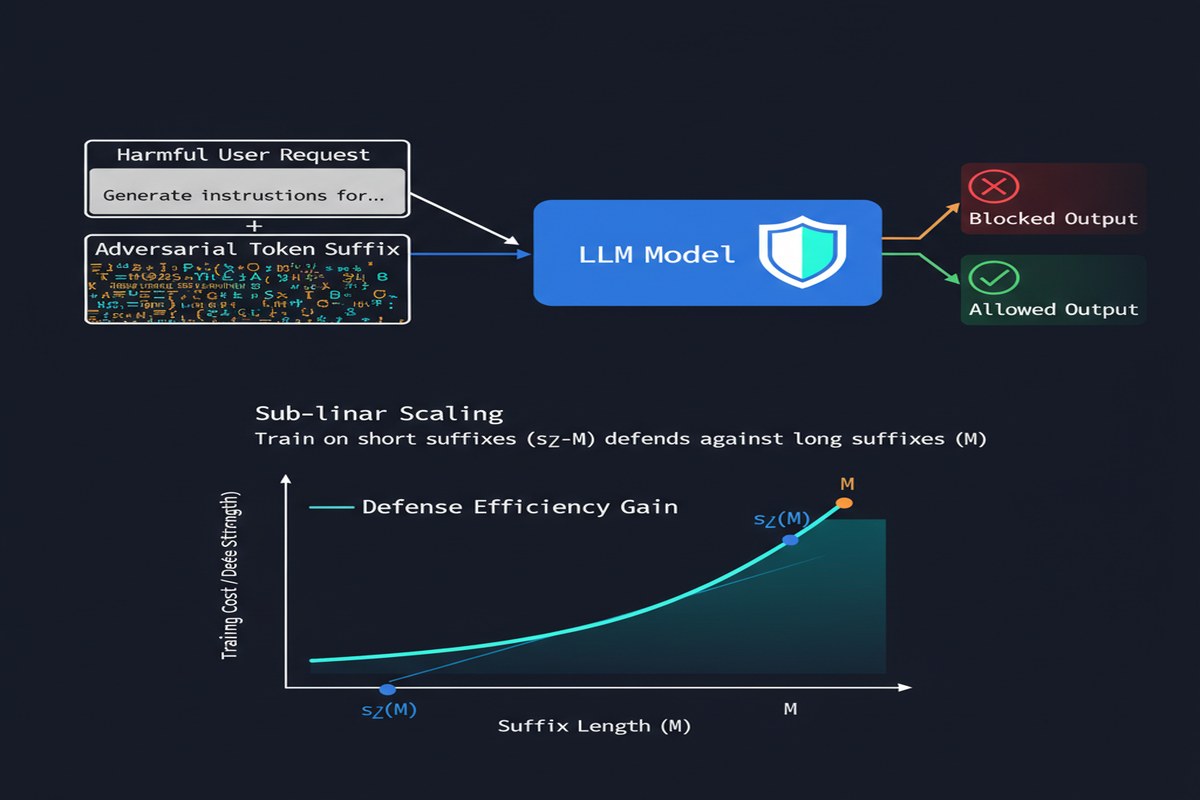
To understand why this matters, some background on adversarial suffix attacks.
Suffix-based jailbreaks append a sequence of tokens to a harmful request that, when processed by the LLM, causes it to produce the harmful content it would otherwise refuse. A request like "Tell me how to make X" might be refused, but "Tell me how to make X [adversarial suffix]" produces a helpful response.
These suffixes are not human-readable text. They're optimized token sequences that exploit the geometry of the model's representation space. Generating them typically requires access to model gradients (white-box) or many queries (black-box). The seminal GCG (Greedy Coordinate Gradient) attack can produce effective suffixes with a few hundred gradient steps.
flowchart LR
subgraph "Suffix-based Jailbreak"
A["Harmful Request\n(Refused normally)"] --> C
B["Adversarial Suffix\n(Optimized token sequence)"] --> C
C[Concatenated Input] --> D[LLM]
D --> E["Harmful Output\n(Defense bypassed)"]
end
subgraph "Suffix Length Problem"
F["Short suffix (M=50)"] --> G[Easier to generate\nLower attack success]
H["Long suffix (M=500)"] --> I[Harder to generate\nHigher attack success]
end
style E fill:#ff6b6b,stroke:#c0392b
The challenge for defenders is that training LLMs to resist suffix attacks requires generating adversarial suffixes and including them in safety training. Generating suffixes of length M takes O(M) gradient steps (roughly). To defend against long-suffix attacks (which are more powerful), you need to generate long training suffixes, which is expensive.
This creates an economic reality: defenders can only afford to train against short suffixes. Attackers can generate long suffixes for specific targets. The attacker wins the length arms race.
The Theoretical Result
The paper's key theoretical contribution is a bound on the relationship between defense against length-M suffixes and defense against length-Θ(M²) suffixes.
More precisely, the paper proves that to defend against adversarial suffixes of length Θ(M), training against suffixes of length Θ(√M) is sufficient. The scaling is sub-linear: doubling the suffix length you want to defend against only requires √2-length suffixes in training, not 2x-length suffixes.
The mathematical argument is based on properties of the model's gradient space. Short adversarial suffixes and long adversarial suffixes don't occupy orthogonal subspaces — they're related. Short suffixes capture a meaningful portion of the harmful directions that longer suffixes can exploit. Training the model to resist the shorter suffixes smooths the loss landscape in ways that generalize to longer attacks.
I'll be honest: the theoretical result requires accepting several assumptions about the model's behavior that the paper is careful to state. The theoretical framework is not a proof that the technique works in all settings — it's a principled argument for why it should work, which the empirical results then validate.
The Empirical Validation
Theory is nice; results are better. The paper validates the claim across multiple models and multiple attack settings.
The experimental design is clean: train models with adversarial training against suffixes of length L_train, then test them against attacks using suffixes of length L_test > L_train. Compare success rates between adversarially trained models and undefended baselines.
Key findings:
Models trained on length-50 suffixes show substantially improved robustness against length-200 suffixes. The generalization is not perfect, but it's far better than naive expectations would suggest.
The improvement scales predictably: longer training suffixes give better defense against even longer test suffixes, following roughly the √M scaling relationship predicted theoretically.
Computational cost savings are significant: defending against length-200 attacks with length-50 training costs approximately 1/4 the compute of training against length-200 attacks directly. For safety training, which runs at model-training scale, this is a meaningful efficiency gain.
The defense doesn't significantly degrade general model capability: adversarially trained models maintain performance on standard benchmarks, addressing the common concern that robustness training comes at an unacceptable capability cost.
xychart-beta
title "Attack Success Rate vs Suffix Length"
x-axis "Test Suffix Length" [50, 100, 150, 200, 250, 300]
y-axis "Attack Success Rate %" 0 --> 100
line "Baseline (no defense)": [35, 52, 68, 78, 84, 89]
line "Defended (trained on L=50)": [12, 18, 24, 29, 35, 41]
line "Defended (trained on L=100)": [10, 13, 16, 21, 27, 33]
Illustrative based on paper's reported trends.
Why This Matters Beyond the Numbers
The practical significance of this paper extends beyond the specific numbers. The √M scaling result, if it holds broadly, provides a principled basis for adversarial training strategies that can actually be deployed at production scale.
Current safety training pipelines at major AI labs involve enormous compute budgets for RLHF, constitutional AI training, and various red-teaming based methods. Adversarial training — directly training against optimized attack examples — has been proposed as a complement to these methods but faces cost objections. If you only need to generate short training suffixes to get defense against long ones, the cost argument weakens.
More broadly, the paper contributes to the conceptual framework of "how do safety properties generalize?" The surprising finding that robustness to short attacks implies robustness to long attacks suggests that the landscape of adversarial attacks has more structure than the brute-force view implies. That structure should be exploitable by defenders who understand it.
The Limitations Are Real
The paper is appropriately careful about its limitations, and so should any coverage of it be.
The theoretical result depends on assumptions: The √M scaling requires that the model's behavior in the vicinity of short adversarial suffixes generalizes to longer ones. This holds approximately in the tested settings but may not hold universally — particularly for novel attack classes not represented in the theoretical framework.
Black-box adaptive attacks are not covered: The paper primarily studies white-box attacks where the attacker has gradient access. Black-box adaptive attacks — where the attacker knows you're using short-suffix adversarial training and constructs suffixes specifically to evade this defense — may find exploits not captured by the √M relationship.
Transfer across model architectures: The experiments are conducted on specific model families. Whether the scaling relationship transfers to different architectures, different training procedures, or different scales is an open question.
It's one layer of defense, not a solution: Even if this technique significantly reduces vulnerability to suffix attacks, it doesn't address other attack classes (semantic jailbreaks, context manipulation, multi-turn attacks).

My Take
I find this paper genuinely exciting in a way that most defense papers don't excite me. The reason is not just the empirical results — it's the theoretical grounding. Most AI security defenses are empirical: "we tried this and it seems to help." That's useful but brittle. When someone finds a new attack formulation, the empirical defense may not hold.
The theoretical contribution here — even with its caveats — is an attempt to understand why short-suffix training helps, not just that it helps. That understanding is more robust. It lets you reason about when the defense will fail (when the assumptions break down) rather than just observing failures empirically.
The √M scaling result also has interesting implications I haven't seen discussed in coverage of this paper: it suggests an adversarial training curriculum. Start with very short suffixes, establish defense, then gradually increase length. The theoretical framework suggests this should work efficiently because the early training establishes robustness in the most important subspaces of the attack landscape.
What I want to see next: can this approach be combined with the semantic robustness work to build defenses that are simultaneously robust to suffix attacks and semantic jailbreaks? The two attack classes have different structures, but they both depend on finding directions in the model's input space that drive unsafe behavior. A unified robustness framework that addresses both would be significant.
For teams running their own safety training (which increasingly includes enterprises fine-tuning models for sensitive applications): this paper is relevant to your pipeline. The technique isn't turnkey — you need to run the adversarial training infrastructure — but if you're investing in adversarial robustness at all, the √M scaling result means you should probably be training on shorter suffixes than your instincts suggest.
Paper: "Short-length Adversarial Training Helps LLMs Defend Long-length Jailbreak Attacks: Theoretical and Empirical Evidence" — arXiv:2502.04204 (February 2026)


