
How Hungry Is AI? The Environmental Cost of LLM Inference Is Bigger Than You Think
The AI industry has a sustainability problem it doesn't like talking about. Model training gets all the headlines — GPT-3's training run consumed enough energy to power a small city, etc. But training is a one-time cost. Inference — running AI models to serve user queries every second of every day — is the ongoing burn. And as LLMs become embedded in every application, the inference bill is growing faster than the industry's efficiency improvements.
"How Hungry is AI? Benchmarking Energy, Water, and Carbon Footprint of LLM Inference" (arXiv: 2505.09598, May 2025) is the first infrastructure-aware benchmarking framework that quantifies the environmental footprint of LLM inference across 30 state-of-the-art models in commercial datacenter conditions. The results are sobering.
The Numbers: What Each AI Query Costs
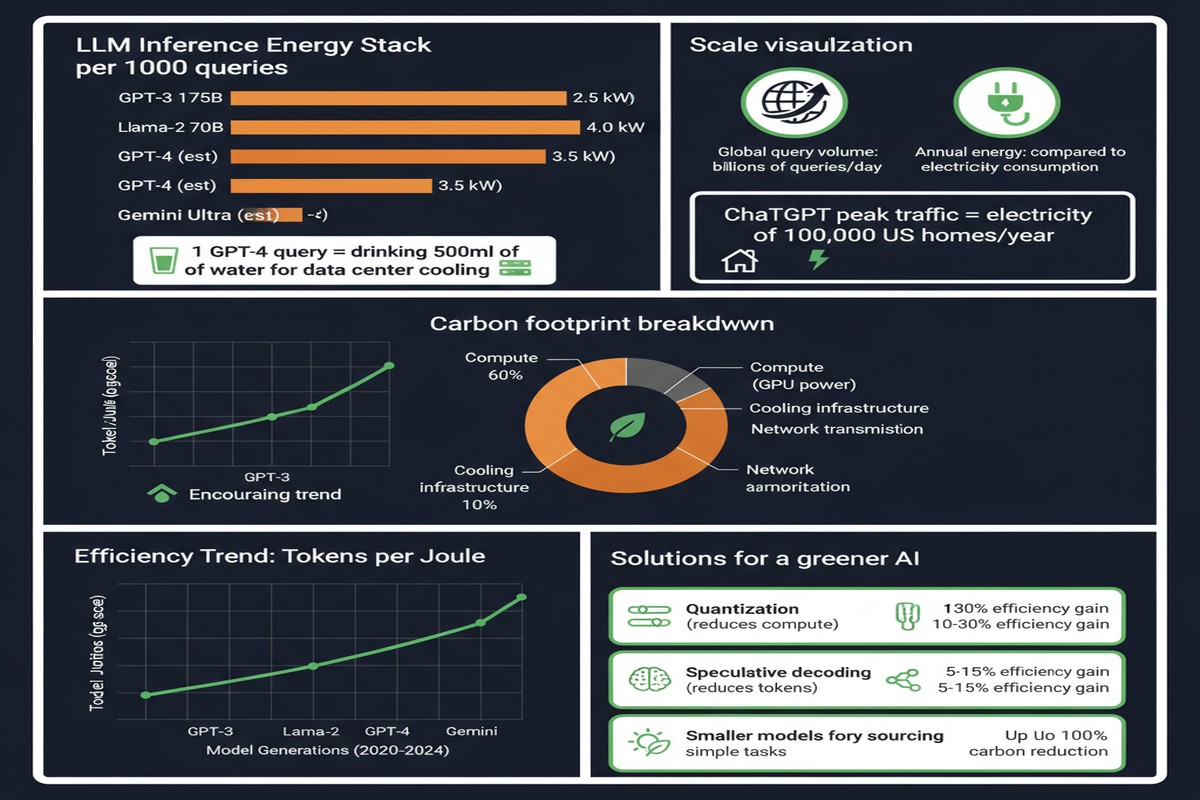
The paper measures energy (Wh), water (liters evaporated for cooling), and carbon (gCO₂eq) per query for a range of LLMs across short and long prompts.
Energy per query comparison:
- Google web search: 0.30 Wh
- Short GPT-4o query: 0.42 Wh (+40% vs. a Google search)
- Long GPT-4o query: ~5-8 Wh (15-25x a Google search)
- Most energy-intensive models measured: 29+ Wh per long prompt
bar
title Energy Consumption Per Query (Wh)
x-axis ["Google Search", "Short GPT-4o", "Efficient LLM", "Standard LLM", "Large LLM (long)"]
y-axis 0 --> 30
"Energy (Wh)" : [0.3, 0.42, 0.8, 3.5, 29]
The scale effect is where it gets serious.
At 700 million queries/day (GPT's estimated scale) with an average cost of 0.42 Wh each:
- Annual electricity: equivalent to powering 35,000 U.S. homes
- Freshwater evaporation: equivalent to the annual drinking needs of 1.2 million people
- Carbon emissions: requiring a Chicago-sized forest to offset annually
And that's conservative — it uses the short-query 0.42 Wh figure. Average queries are longer.
The Water Problem Nobody Talks About
Carbon emissions get all the attention. Water consumption is the silent crisis.
Data centers use evaporative cooling — they evaporate water to keep servers cool. The water evaporated is consumed, not returned to the water supply in usable form. For AI inference:
- GPT-3 training consumed over 5 million liters of freshwater
- AI-related withdrawals could reach 6.6 trillion liters annually by 2027 (from the broader literature)
- The paper measures per-query water consumption across models, with larger models evaporating proportionally more
Water stress is increasingly a constraint on datacenter siting. Google, Microsoft, and Amazon have all received criticism for datacenter water use in water-scarce regions. As AI inference scales, this becomes a genuine resource allocation problem in water-stressed areas like the American Southwest, the Middle East, and parts of India.
Why Inference Trumps Training in Total Impact
AI conversations typically focus on training compute because training runs are dramatic, one-time events with measurable energy budgets. The math changes when you account for model lifetime:
flowchart LR
subgraph Training
T1[One-time cost] --> T2[GPT-3: ~1,300 MWh]
end
subgraph Inference over Model Lifetime
I1[Daily queries: 700M] --> I2[Annual energy: 300,000+ MWh]
I2 --> I3[3+ year model lifetime]
I3 --> I4[Total: 900,000+ MWh]
end
T2 -->|Training fraction| C[~0.1% of lifecycle cost]
I4 -->|Inference fraction| D[~99.9% of lifecycle cost]
style D fill:#dc2626,color:#fff
style C fill:#059669,color:#fff
Training is the tip of the iceberg. Inference is what sinks ships.
This reframes the sustainability conversation entirely. Efficiency improvements that reduce inference cost per query by 10% matter far more than equivalent improvements to training efficiency. Every percentage point of inference efficiency improvement, applied to millions of queries daily, compounds significantly.
The 65x Efficiency Gap
The paper's most actionable finding: across 30 models evaluated, the most energy-efficient systems use 65 times less energy per long prompt than the least efficient.
This gap is not primarily about model size — it's about:
- Architecture efficiency: MoE models, efficient attention mechanisms
- Inference optimization: quantization, speculative decoding, batching strategies
- Hardware matching: running models on hardware suited to their memory and compute requirements
- Deployment configuration: batch sizes, sequence lengths, KV cache management
The 65x variation means that organizations deploying LLMs have substantial control over their environmental footprint through infrastructure choices, not just model selection.
The Paradox of Accessible AI
Here's the uncomfortable truth the paper highlights: AI is getting cheaper, so people use more of it.
As frontier model inference costs drop — driven by hardware improvements, quantization, and competition — usage scales up. The net energy consumption of AI doesn't decrease; it stays flat or increases because volume growth outpaces efficiency gains.
This is the classic Jevons paradox applied to AI compute: efficiency improvements increase total consumption. The only way out is either:
- Absolute efficiency gains large enough to outpace volume growth (hard)
- Renewable energy powering AI infrastructure (necessary but insufficient)
- Applications that genuinely displace higher-energy alternatives (case-by-case)
The third point is underappreciated. If an AI system replaces a 30-minute human search process that would have required physical travel, the energy math can favor AI even at high query costs. The environmental case for AI depends heavily on what it replaces, not just what it consumes.
Infrastructure-Aware Benchmarking: Why It Matters
Previous energy estimates for AI inference used simplified models that ignored real datacenter dynamics. This paper's "infrastructure-aware" methodology accounts for:
- Power Usage Effectiveness (PUE): Datacenter overhead beyond just server power
- Grid carbon intensity: When and where inference happens matters for carbon calculation
- Cooling systems: Water usage varies by cooling technology and climate
- Hardware utilization: Partial GPU utilization is less efficient per useful operation
The result is estimates that better reflect actual environmental costs than previous back-of-envelope calculations.
Why This Matters for AI Policy and Development
The paper isn't just an academic exercise. Its findings have direct implications:
For AI labs: Inference efficiency should be a first-class metric alongside performance metrics. The 65x efficiency gap suggests many deployments are leaving significant efficiency gains on the table.
For enterprises deploying AI: The choice of model, deployment configuration, and hardware all have measurable environmental impact. Smaller, task-specific models deployed efficiently often outperform large general-purpose models on environmental metrics while matching performance for specific use cases.
For regulators: The EU AI Act and emerging AI regulations are beginning to require energy reporting for high-impact AI systems. Benchmarks like this one provide the methodology that regulation will need.
My Take
This paper is necessary and overdue. The AI industry's sustainability narrative has been dominated by labs' carbon neutrality pledges and renewable energy purchases — which are real but incomplete. The actual resource consumption numbers need to be in the public domain.
The water consumption finding deserves more attention than it gets. Carbon is abstract and global. Water stress is local and immediate. When an AI datacenter in a water-scarce region evaporates millions of liters of groundwater, the impact is felt by local communities and ecosystems — not offset by purchasing renewable energy credits.
I have two concerns about the paper's framing:
First, the comparisons to "Google searches" are rhetorically effective but potentially misleading. A GPT-4o query that writes a detailed analysis saves hours of human research. A Google search finds a URL. The energy comparison doesn't capture the value delivered.
Second, the efficiency narrative needs a longer timeline. Inference efficiency has improved dramatically over the past 3 years — today's 70B model runs faster and cheaper than last year's 13B model. Snapshot measurements may not capture the trajectory.
Still: transparency about environmental costs is unambiguously good. The 65x efficiency spread across models gives AI teams actionable data for making greener deployment choices. That's progress.
AI's environmental footprint is real. The first step to managing it is measuring it honestly.

Paper: "How Hungry is AI? Benchmarking Energy, Water, and Carbon Footprint of LLM Inference", arXiv: 2505.09598, May 2025.
Explore more from Dr. Jyothi


