
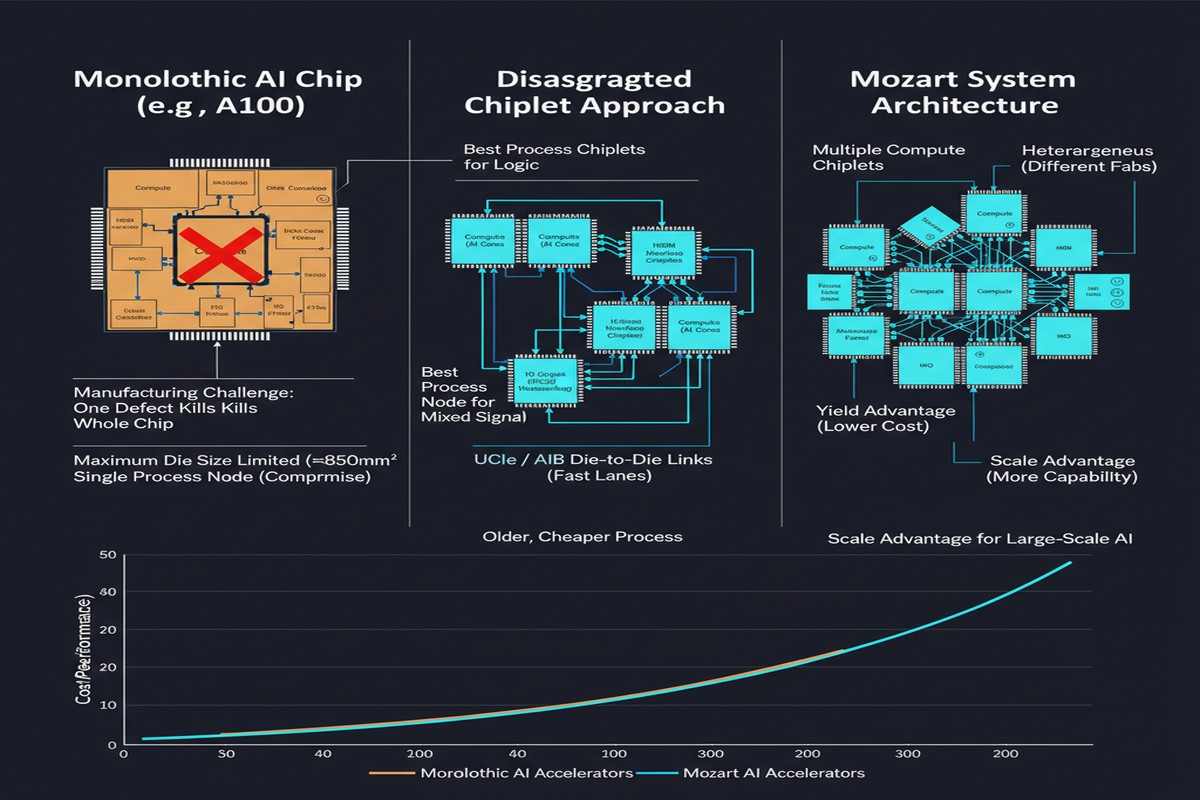
Every decade or so, semiconductor architecture undergoes a structural shift. We moved from single-core to multi-core. From monolithic SoCs to chiplets for memory. Now the disaggregation wave is hitting AI accelerators — and a paper called Mozart shows exactly what that future looks like.
Mozart, published in October 2025 by Jin, Yang, Liu, and colleagues (arXiv:2510.08873), introduces a chiplet ecosystem co-design framework for composable bespoke application-specific integrated circuits (BASICs). The title is a mouthful, but the idea is elegant: instead of building one big AI chip that handles every operation the same way, Mozart decomposes neural network inference operator by operator, assigns each operator class to the chiplet type that handles it best, and then assembles those chiplets into a physically validated composite accelerator.
The results are striking. With just 8 strategically selected chiplets, Mozart-generated BASICs achieve 43.5% energy reduction, 25.4% improvement in energy-cost product, 67.7% better energy-delay product (EDP), and 78.8% improvement in energy-delay-cost product compared to traditional homogeneous accelerators. These are not incremental improvements. These are the kind of numbers that make chip architects rethink their assumptions.
The Problem With Homogeneous Accelerators
Before diving into Mozart's solution, it's worth understanding why the status quo fails.
Current AI accelerators — from NVIDIA's H100 to Google's TPU v5 — are essentially homogeneous at the compute level. They provide a large array of uniform processing elements optimized for matrix multiplication, the dominant operation in transformer-based models. This works well when the workload is uniform. But neural networks are not uniform workloads.
A modern transformer inference pipeline includes:
- Attention operations (memory-bound, quadratic in sequence length)
- Feed-forward projections (compute-bound, highly parallelizable)
- Normalization layers (element-wise, latency-sensitive)
- Embedding lookups (random access, bandwidth-limited)
- Softmax and activation functions (sequential, precision-sensitive)
These operations have fundamentally different compute/memory ratios, parallelism profiles, and precision requirements. Throwing them all at the same homogeneous array is like using a single universal wrench for every bolt in an engine. It works, but it's wasteful.
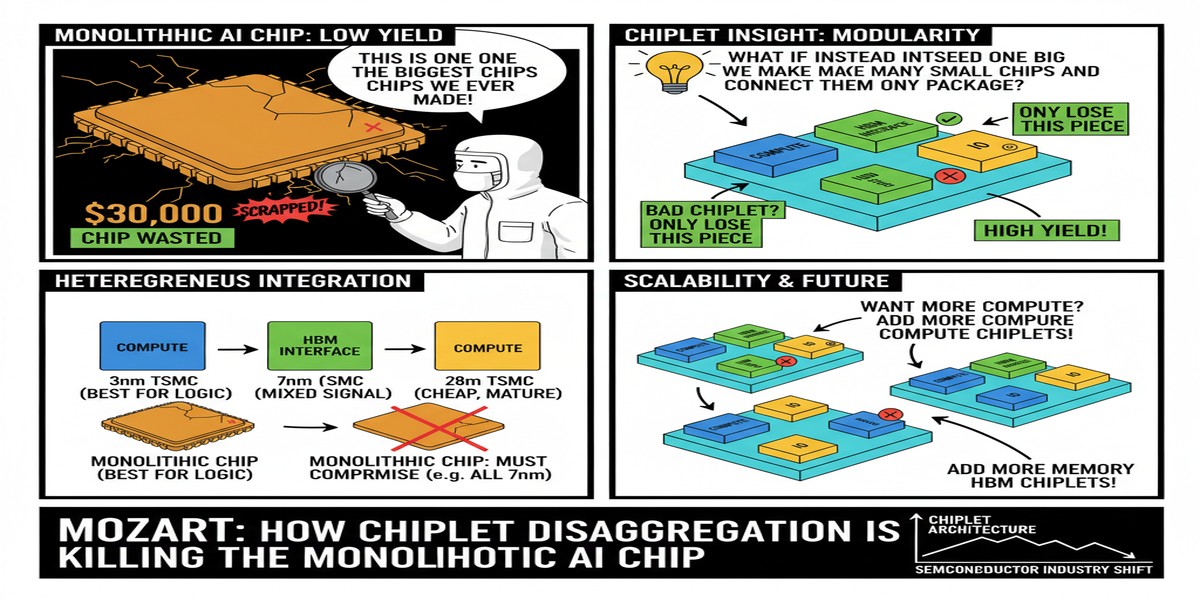
Mozart's diagnosis: network-level customization and operator-level heterogeneity are the correct approach — but the Non-Recurring Engineering (NRE) cost of designing fully custom heterogeneous chips has been prohibitively high. Chiplets change that equation.
What Mozart Actually Does
The Mozart framework has three core contributions:
1. Operator-level disaggregation. Mozart profiles a target neural network and groups its operators into classes based on computational characteristics — compute intensity, memory access patterns, parallelism degree. Each class becomes a candidate for a dedicated chiplet type.
2. Chiplet and memory heterogeneity exploration. Given a catalog of available chiplet IP blocks, Mozart's co-design engine explores how different combinations of chiplets (and memory configurations — HBM, LPDDR, on-chip SRAM in various ratios) map to the operator classes. The design space is enormous; Mozart uses operator-level analysis to prune it efficiently.
3. Tensor fusion and parallelism optimization with place-and-route validation. Once a candidate chiplet assignment is found, Mozart applies tensor fusion (combining operations to reduce off-chip memory traffic) and tensor parallelism (splitting tensors across chiplets for throughput). Crucially, it validates physical implementability through place-and-route analysis — not just simulation — ensuring the design can actually be manufactured.
flowchart TD
A[Neural Network Workload] --> B[Operator Profiling & Classification]
B --> C[Compute-Bound Ops]
B --> D[Memory-Bound Ops]
B --> E[Bandwidth-Bound Ops]
C --> F[Matrix Multiply Chiplet]
D --> G[Attention Chiplet w/ HBM]
E --> H[Embedding / Lookup Chiplet]
F --> I[Tensor Fusion Engine]
G --> I
H --> I
I --> J[Place-and-Route Validation]
J --> K{Physically Implementable?}
K -->|Yes| L[BASIC: Bespoke ASIC]
K -->|No| B
L --> M[43.5% energy reduction vs homogeneous]
The BASIC acronym — Bespoke Application-Specific Integrated Circuits — is deliberate. These are not general-purpose chips designed to handle any workload. They are purpose-built for a specific model or class of models, assembled from reusable chiplet building blocks.
The Chiplet Economics Argument
The key insight that makes Mozart viable is the separation of NRE costs across chiplet types. Traditional ASIC design requires paying the full NRE cost (mask sets, verification, tape-out) every time you want a new chip. With chiplets, you amortize that cost.
If you have a catalog of 10 well-validated chiplet IP blocks — a matrix multiply chiplet, an attention chiplet, a normalization chiplet, an embedding lookup chiplet, and various memory controller variants — you can assemble them in different configurations for different models without incurring full NRE costs each time. Mozart demonstrates that with just 8 chiplets, you can cover a surprisingly large fraction of the AI operator space with near-optimal assignments.
This is analogous to what happened in consumer electronics with standardized connectors and modular boards. The "chipletization" of AI accelerators is the logical next step after the chipletization of memory (HBM, LPDDR).
graph LR
subgraph "Traditional Approach"
A[Monolithic AI ASIC] -->|Full NRE per model| B[High cost, uniform compute]
end
subgraph "Mozart Approach"
C[Chiplet Catalog] --> D[Attention Chiplet]
C --> E[Matrix Chiplet]
C --> F[Memory Controller]
D --> G[BASIC Composition Engine]
E --> G
F --> G
G -->|Low NRE per model| H[Heterogeneous, model-optimized]
end
style B fill:#f88,stroke:#c00
style H fill:#8f8,stroke:#080
Why This Matters
The AI chip industry is facing a wall. Dennard scaling ended years ago. TSMC's N2 node gives you another generation of gains, but those gains are shrinking. Meanwhile, model sizes keep growing — LLMs with hundreds of billions of parameters are becoming standard, and multimodal models add vision, audio, and video workloads on top of text.
Homogeneous scaling will not get us through the next decade of AI compute demand. The hardware community needs architectural diversity, and chiplets provide the mechanism to achieve that diversity without the cost of fully custom silicon for every application.
Mozart is one of the first frameworks to demonstrate this concretely for AI accelerators, with physical validation rather than just simulation. The 43.5% energy reduction number is impressive. The 78.8% energy-delay-cost improvement is transformative if it holds across diverse model families — which the paper's evaluation across multiple workloads suggests it does.
My Take
I've been watching the chiplet conversation in AI hardware for years, mostly around memory bandwidth (HBM integration) and I/O (die-to-die interconnects like UCIe). Mozart represents something qualitatively different: chiplets as the unit of compute heterogeneity, not just memory or connectivity.
This is the right direction, and I'll tell you why it took this long: the toolchain wasn't ready. Physical co-design across chiplet boundaries requires EDA tools that understand both the die-level and package-level design simultaneously. Mozart's insistence on place-and-route validation suggests the toolchain is finally catching up.
What I find most interesting about this paper is not the energy numbers — impressive as they are. It's the operator-level disaggregation philosophy. The authors are essentially arguing that neural network operators are so different from each other that treating them uniformly in silicon is a fundamental mistake. I agree. The gap between an attention operation (memory-bound, irregular access patterns, precision-sensitive) and a feed-forward projection (regular, compute-bound, amenable to quantization) is enormous. They deserve different silicon.
The risk is fragmentation. If every model family requires a different chiplet composition, we lose the ecosystem benefits of standardization. Mozart partially addresses this by constraining the chiplet catalog size — demonstrating that 8 chiplets can cover substantial ground — but the industry will need to converge on interoperability standards (UCIe is a start) for the Mozart vision to scale beyond research prototypes.
I'm also watching the memory architecture implications. Mozart's heterogeneous memory assignment — HBM for attention, SRAM for feed-forward, LPDDR for embedding — mirrors what I think the optimal inference stack looks like. The attention mechanism's quadratic memory hunger is a qualitatively different problem from the projection layer's bandwidth hunger. Mozart treats them differently. That's the correct call.
If you're building AI infrastructure at any scale, this paper deserves your attention. The chiplet era for AI compute is arriving.
Mozart: A Chiplet Ecosystem-Accelerator Codesign Framework for Composable Bespoke Application Specific Integrated Circuits — Haoran Jin, Jirong Yang, Yunpeng Liu, Barry Lyu, Kangqi Zhang, Nathaniel Bleier. arXiv:2510.08873, October 2025.


