
I have a complicated relationship with empirical comparison papers. Most of them compare things under conditions that favor their preferred approach, benchmark on toy datasets that don't reflect production use, and draw conclusions that are technically accurate but practically useless.
Anuj Maharjan and Umesh Yadav's January 2026 paper on RAG architectures for policy document question answering is not one of those papers. It's an honest comparison under realistic conditions with clear, actionable conclusions. In a field drowning in systems papers, a well-executed empirical study is more valuable than people give it credit for.
The Setup
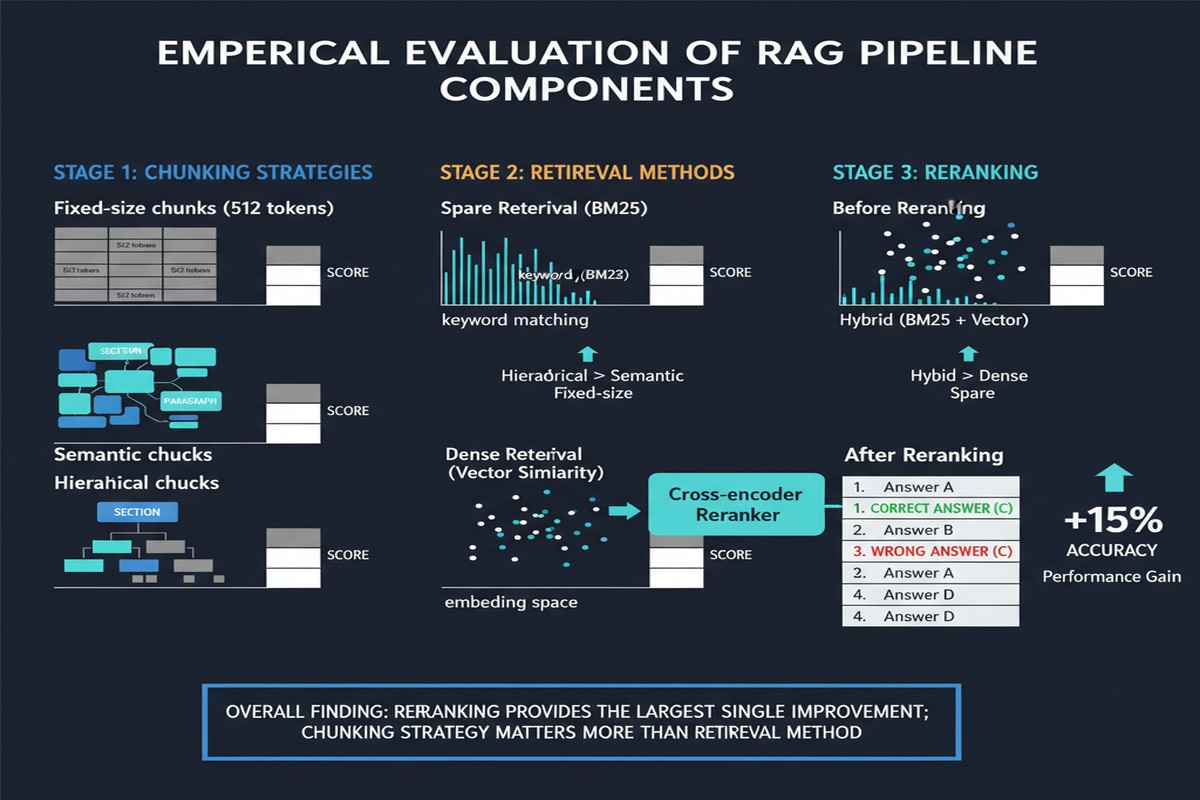
The paper compares three tiers of a RAG system applied to CDC public health policy documents — the kind of complex, technical documents that real government and healthcare organizations actually need to query:
Tier 1: Baseline LLM — No retrieval. Just ask the language model the question from parametric knowledge.
Tier 2: Basic RAG — Standard chunking + dense retrieval. The most common RAG setup in production today.
Tier 3: Advanced RAG — Standard chunking + dense retrieval + cross-encoder re-ranking.
The evaluation uses RAGAS metrics: faithfulness (does the answer stick to the retrieved context?), answer relevancy (does the answer address the question?), and context precision (are the retrieved chunks relevant?).
barChart
title Faithfulness by RAG Tier
x-axis ["Baseline LLM (No RAG)", "Basic RAG", "Advanced RAG (with Re-ranking)"]
y-axis "Faithfulness Score" 0 --> 1
bar [0.347, 0.621, 0.797]
The results:
| Configuration | Faithfulness | Answer Relevancy | Context Precision |
|---|---|---|---|
| Baseline LLM | 0.347 | 0.741 | N/A |
| Basic RAG | 0.621 | 0.783 | 0.812 |
| Advanced RAG | 0.797 | 0.821 | 0.867 |
The headline number: adding re-ranking to basic RAG improves faithfulness by 28 percentage points (from 0.621 to 0.797). That is not a marginal improvement. That's the difference between a system that halluccinates nearly 40% of the time and one that's reliable enough to actually use.
Why Re-ranking Makes Such a Difference
The paper's analysis of why re-ranking helps is where it earns its keep.
Dense retrieval is good at finding topically related content. It embeds the query and finds chunks whose embeddings are nearby in vector space. This works well when topical similarity correlates with answering utility — which it often does for simple factoid questions.
But policy documents have a specific failure mode: off-topic topical overlap. A query about "COVID-19 testing guidelines for healthcare workers" might retrieve chunks about "healthcare worker safety protocols" (topically related) and "COVID-19 testing reagent procurement" (topically related) instead of the specific section about testing guidelines. Both are topically close in embedding space. Neither answers the question.
A cross-encoder re-ranker doesn't embed independently — it jointly encodes the query and the candidate chunk, allowing fine-grained relevance assessment. The cross-encoder can distinguish "this chunk discusses COVID-19 testing protocols as they apply to healthcare workers" from "this chunk discusses COVID-19 testing in general." That distinction is exactly what policy QA requires.
flowchart LR
Q[Query:\nCOVID-19 testing\nfor healthcare workers] --> Dense[Dense Retrieval\nTop-20 chunks]
Dense --> Topical[Topically Related\nbut not precise]
Topical --> Reranker[Cross-Encoder\nRe-ranker]
Reranker --> Precise[Precisely Relevant\nTop-5 chunks]
Precise --> LLM[Generator]
LLM --> Answer[High-Faithfulness Answer]
The Chunking Problem
The paper also includes a frank admission that deserves attention: "challenges remain in document segmentation that affect performance on complex multi-step reasoning tasks."
Chunking is the part of RAG that most practitioners underinvest in. People spend weeks tuning their vector database and retriever and then chunk everything at 512 tokens with 50-token overlap because it's the default setting.
Policy documents are not uniform prose. They contain:
- Numbered sections with hierarchical structure
- Cross-references ("see section 4.2.1 for criteria")
- Definitions that apply throughout the document
- Tables and figures embedded in prose
- Conditional statements ("if condition X, then procedure Y applies")
A fixed-size chunker treats all of this identically. The result is chunks that straddle section boundaries, split conditional logic, or lose the definitional context needed to interpret later chunks.
The paper doesn't propose a solution — it flags the problem honestly. But the implication is clear: for high-stakes domain-specific RAG, chunking strategy is not a one-time configuration decision. It's an ongoing engineering investment.
The Relevance to Real Deployments
Let me be concrete about what these numbers mean for teams building RAG in production.
A faithfulness score of 0.621 for basic RAG means that roughly 38% of generated answers contain content not grounded in the retrieved context. For an internal knowledge base tool, that's annoying. For a healthcare policy compliance assistant, it's a liability. For a legal research tool, it could be catastrophic.
The jump to 0.797 from re-ranking doesn't get you to perfection. About 20% of responses still have faithfulness issues. But it crosses a threshold that matters: the system is reliable enough that users can treat it as a first-pass tool with human review for edge cases, rather than a system that requires verification of every output.
This threshold analysis — what faithfulness score is "good enough" for your use case? — is something most teams don't do explicitly. They build a RAG system, evaluate it informally, and declare it ready. This paper provides the kind of grounded numbers that should inform those conversations.
What's Missing
The paper's scope is limited to text-chunked CDC documents. I'd push back on two fronts:
First, the chunking strategies tested are modest — fixed-size chunking with varying overlap settings. There's a rich literature on semantic chunking, recursive character splitting, parent-document retrieval, and hierarchical indexing that the paper doesn't evaluate. The conclusion that re-ranking matters more than chunking strategy may be an artifact of testing only rudimentary chunking approaches.
Second, the evaluation is on a single domain. Policy document QA is a specific genre with specific characteristics (formal language, explicit cross-references, structured sections). I'd expect the relative importance of chunking vs. re-ranking to vary significantly across domains. Technical code documentation, narrative news articles, and scientific papers each have different failure modes.
My Take
Papers like this are unfashionable in the research community — they don't propose novel architectures, they don't achieve state-of-the-art on a prestigious benchmark, and they don't have an elegant theoretical contribution. But they fill a genuine gap: telling practitioners what actually works in realistic conditions.
The finding that re-ranking provides a 28-point faithfulness improvement over basic RAG is the kind of concrete, actionable result that should change how teams allocate their RAG engineering time.
My recommendation: before you invest in fancy retrieval architectures, complex chunking pipelines, or fine-tuned embedding models — add a cross-encoder re-ranker. The improvement-per-engineering-hour ratio is higher than almost anything else you can do to your RAG system.
The complexity is manageable (cross-encoders are well-supported in LlamaIndex, LangChain, and Haystack), the latency cost is acceptable if you cache aggressively, and the faithfulness improvement is real. This paper gives you the numbers to justify the investment to your team.
arXiv: 2601.15457



