
Continual GUI Agents: Teaching AI to Keep Up With a Changing Digital World
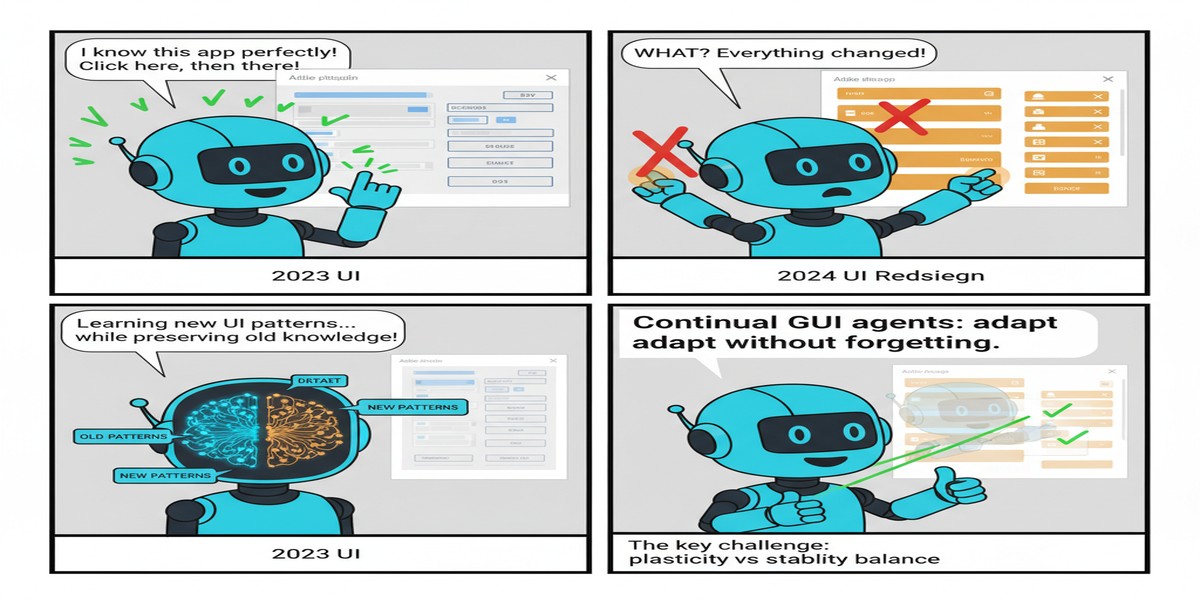
Here's a problem nobody talks about enough: your GUI agent is trained on screenshots from six months ago. The app has shipped 23 updates since then. The "Settings" button moved. The navigation structure changed. A new dialog appears before the old flow. The agent, frozen in time, fails.
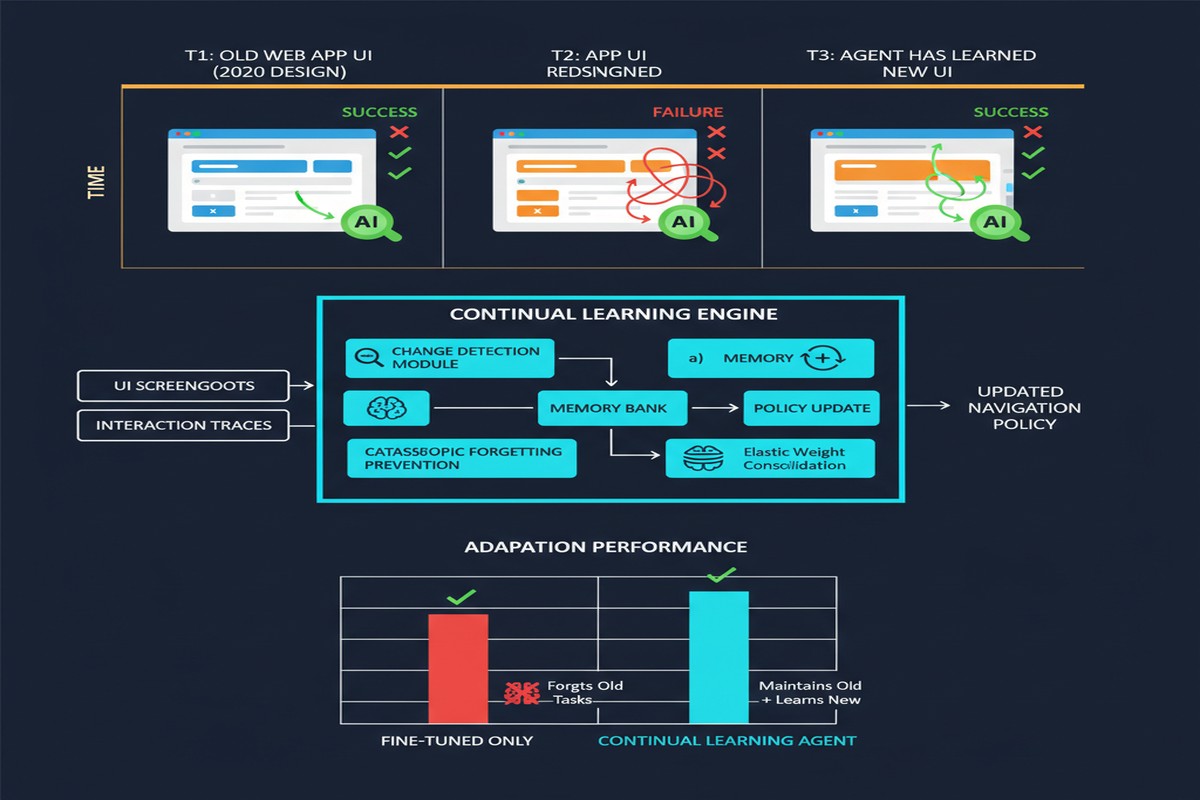
Continual GUI Agents (arXiv: 2601.20732, Jan 2026) confronts this problem directly. It frames GUI agent deployment not as a one-time training problem but as a continual learning problem: models must adapt to evolving interfaces without catastrophically forgetting how to use the interfaces they've already learned.
The Problem: GUIs Are Living Systems
Most GUI agent research treats the interface as static. You collect demonstrations, train a model, evaluate on held-out tasks, publish the benchmark number. But software doesn't stand still.
Consider the scale of the problem:
- Major mobile apps ship updates weekly
- Enterprise SaaS platforms update continuously
- OS interfaces change with every major version
- Web applications update layouts, flows, and components constantly
An agent trained to navigate, say, Slack's interface from early 2025 encounters a different interface in late 2025. The layout shifts. New features appear. Old workflows are reorganized. The agent's learned policy, specialized to the old interface, transfers imperfectly.
timeline
title GUI Interface Evolution Problem
2025-Q1 : Agent trained on App v1.0
: Navigation: sidebar
: Settings: top-right menu
2025-Q2 : App v2.0 ships
: Navigation: bottom tab bar
: Settings: hamburger menu
2025-Q3 : Agent tested on App v2.0
: Failure rate spikes
: Must retrain from scratch?
2025-Q4 : Continual GUI Agents approach
: Adapts incrementally
: Preserves old interface knowledge
Naive retraining on new interface data causes catastrophic forgetting — the model performs well on new interfaces but degrades on old ones. This is unacceptable for production agents that must handle many different applications simultaneously.
What Continual GUI Agents Does
The paper proposes a continual learning framework specifically designed for the GUI agent domain, with three key components:
1. Domain-Incremental Interface Streams
The framework treats each application (or major version of an application) as a separate domain. Rather than fine-tuning on all data at once, the agent encounters new interface domains sequentially — mirroring real deployment where you add new application capabilities over time.
The experimental setup covers multiple mobile apps and operating system variants across multiple versions, creating a realistic stream of evolving domains.
2. RLVR-Based Adaptation
Reinforcement Learning with Verifiable Rewards (RLVR) is central to the adaptation mechanism. When the agent encounters a new interface version, it receives reward signals from task completion — and crucially, these rewards are verifiable: success at completing a task in the new interface is unambiguous.
This RLVR approach is more data-efficient than supervised learning for adaptation because it doesn't require demonstration data for every new interface state. The agent can explore and receive feedback.
flowchart TD
A[New Interface Version] --> B[RLVR Exploration]
B --> C{Task Success?}
C -->|Yes| D[Positive Reward\nUpdate Policy]
C -->|No| E[Negative Reward\nExplore Different Strategy]
D --> F[Regularization to\nPrevent Forgetting]
E --> B
F --> G[Adapted Agent\nOld + New Interface Knowledge]
style D fill:#059669,color:#fff
style F fill:#2563eb,color:#fff
style G fill:#7c3aed,color:#fff
3. Selective Regularization for Memory Preservation
The core technical contribution is a selective regularization mechanism that identifies which model parameters are most important for previously learned interfaces and protects them from large updates when learning new ones.
The approach is related to elastic weight consolidation (EWC) but adapted for the specific structure of VLM-based GUI agents, where different parameter groups (visual encoding layers vs. action prediction heads vs. interface-specific representations) have different roles in retaining interface knowledge.
Evaluation Results
The paper evaluates on a challenging benchmark spanning:
- Multiple mobile applications (productivity, social, e-commerce categories)
- Multiple versions of each app (capturing real evolution)
- Tasks ranging from simple navigation to complex multi-step workflows
Key results:
Continual GUI Agents significantly outperforms naive fine-tuning on both backward transfer (old interface performance) and forward transfer (new interface adaptation).
RLVR adaptation is 3-5x more sample-efficient than supervised fine-tuning for new interface versions, because it doesn't require complete demonstration coverage of the new interface states.
The approach scales: performance improvements hold as the number of interface domains increases, unlike naive methods that degrade proportionally with the number of domains.
The Broader Context: Why GUI Agents Matter
GUI agents are potentially one of the most economically significant AI applications. Consider:
- Billions of dollars spent on robotic process automation (RPA) using brittle rule-based tools
- Enterprise workflows locked into legacy systems without APIs
- Accessibility tools for users who can't interact with standard interfaces
- Testing automation for software QA
All of these applications require agents that interact with real, evolving software interfaces. The static-training paradigm has been a major limitation. Continual learning for GUI agents isn't an academic curiosity — it's a fundamental requirement for production deployment.
Connection to Computer Use APIs
The timing of this paper is relevant: Anthropic's Computer Use API (Claude 3.5 Sonnet) and similar systems from OpenAI have made GUI agents a practical product category. But these systems face exactly the adaptation problem this paper studies — they must work across different user environments, versions of software, and configurations.
The techniques in Continual GUI Agents could serve as the training-side counterpart to inference-side computer use capabilities: while the model handles arbitrary interfaces at inference time, continual learning ensures the underlying policy stays current as the digital landscape evolves.
Why This Matters
The research question is simple: can AI agents keep up with a world that doesn't stop changing? The answer matters enormously for deployment viability.
Every enterprise that deploys an agent-based automation knows the maintenance nightmare: interfaces change, workflows update, the agent breaks, somebody has to fix it. Continual learning is the path to agents that maintain themselves — reducing the operational burden of keeping AI-powered automation functional over time.
My Take
This paper addresses a real, underappreciated problem. The field has been too focused on peak capability at a single point in time and not enough on sustained performance across time. Real deployment is a continual learning problem.
The RLVR-based adaptation approach is elegant — verifiable task completion is a natural and abundant reward signal for GUI tasks, and it sidesteps the need for expensive demonstration data for every new interface state.
I'm cautious about one thing: the regularization approach relies on identifying "important" parameters, which is non-trivial. The quality of the importance estimation heavily influences forgetting rates. The paper's approach seems to work for the evaluated domains, but I'd want to see robustness analysis across more heterogeneous application categories before committing to this specific mechanism.
The research direction is unambiguously correct. GUI agents need continual learning to be production-viable. This paper makes serious progress on figuring out how.
Next frontier: agents that don't just adapt to new interfaces but proactively signal when they're uncertain due to interface changes, rather than silently failing. Uncertainty-aware adaptation in the face of distribution shift.
Paper: "Continual GUI Agents", arXiv: 2601.20732, Jan 2026.


