
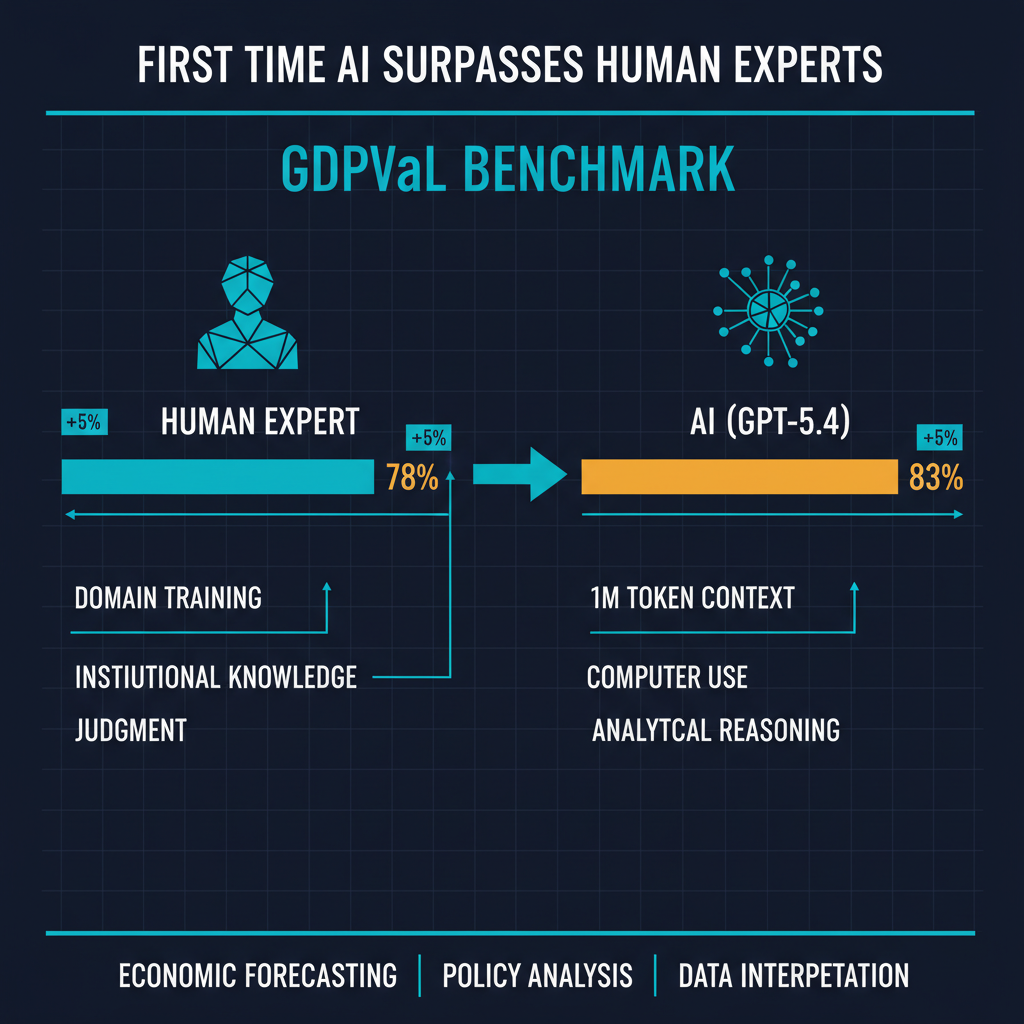
OpenAI's release of GPT-5.4 "Thinking" marks a threshold that many in the industry expected was still a year or two away. The model scored 83.0% on the GDPVal benchmark -- a rigorous evaluation framework designed to test economic reasoning, forecasting, and data interpretation -- surpassing the average performance of human domain experts. It ships with a one-million-token context window and, perhaps most significantly, native computer use capabilities integrated directly into the Codex development environment.
This is not the first time an AI model has beaten a benchmark designed for human specialists. But the nature of the benchmark, the breadth of the capability set, and the product decisions wrapped around this release deserve careful analysis. There is more happening here than another number on a leaderboard.
What GDPVal Actually Measures
GDPVal is not a trivia test. It was developed by a consortium of economists and data scientists to evaluate the kind of analytical reasoning that professional economists perform daily: interpreting macroeconomic data, identifying causal relationships in complex systems, forecasting outcomes under uncertainty, and synthesizing information from multiple sources into coherent assessments.
The benchmark includes tasks like analyzing conflicting economic indicators to produce a growth forecast, evaluating policy proposals with incomplete data, and interpreting time-series data with structural breaks. These are tasks where human experts bring years of domain training, institutional knowledge, and what we casually call "judgment."
GPT-5.4 Thinking scoring 83.0% against a human expert average of roughly 78% is meaningful precisely because these are not the kinds of tasks where pattern matching alone should suffice. Economic reasoning requires handling ambiguity, weighing conflicting evidence, and making defensible judgment calls when the data underdetermines the answer. The model appears to be doing something that at least resembles expert reasoning, whether or not we are comfortable calling it that.
The One-Million-Token Context Window
GPT-5.4's one-million-token context window is not a first -- Anthropic's Claude Opus 4.6 shipped with the same capacity around the same time, and Google's Gemini models have been pushing context length boundaries for over a year. But it represents the consolidation of an important trend: frontier models now routinely handle context lengths that would have been considered impractical 18 months ago.
What matters here is not the raw number but what it enables in practice. A million tokens is roughly the equivalent of four to five full-length novels, or an entire company's quarterly financial filings, or a complete codebase with documentation. The ability to hold all of this in context simultaneously changes how these models can be used for analysis tasks. Instead of carefully chunking and summarizing information in a retrieval pipeline, practitioners can increasingly just provide the full source material.
I have been working with large-context models extensively, and the practical implications are significant. The retrieval-augmented generation paradigm that dominated 2024-2025 application architecture was partly a workaround for limited context windows. As context windows expand, the optimal architecture for many applications shifts. Not all RAG systems become obsolete -- there are still strong reasons for structured retrieval, cost management, and working with corpora that exceed even million-token limits -- but the design space for AI applications has genuinely expanded.
Computer Use Inside Codex: The Quiet Revolution
The feature that I think deserves the most attention in this release is native computer use capabilities integrated into Codex. OpenAI has positioned this as a developer productivity feature, but the implications extend far beyond writing code.
Computer use -- the ability for an AI model to interact with a computer the way a human would, navigating interfaces, clicking buttons, reading screens, and executing multi-step workflows -- is the bridge between language models and agentic systems. When a model can not only reason about a task but also execute it by directly manipulating software, the boundary between "AI assistant" and "AI agent" becomes functionally meaningless.
Codex with computer use means that GPT-5.4 can, in principle, perform end-to-end development workflows: read requirements, write code, run tests, debug failures, deploy changes, and verify the deployment. Each of these steps involves interacting with different tools and interfaces. The model is not just generating text that a human then acts on -- it is acting directly.
This is the same direction Anthropic has been pursuing with Claude's computer use capabilities, and it signals an industry-wide convergence toward models that operate in the world rather than merely describing it. For software development specifically, this could accelerate a shift I have been watching closely: the move from AI-assisted coding to AI-executed coding with human review.
What Does "Surpassing Human Experts" Actually Mean?
I want to be precise about what this benchmark result does and does not tell us.
What it tells us: GPT-5.4 can perform structured analytical reasoning tasks in economics at a level that matches or exceeds the average performance of credentialed human experts on a specific, well-designed benchmark. This is a genuine capability milestone.
What it does not tell us: that GPT-5.4 "understands" economics, that it can replace economists, or that benchmark performance translates directly to real-world expert judgment. Benchmarks, even good ones, are controlled evaluations. Real-world economic analysis involves navigating political context, institutional dynamics, stakeholder communication, and the kind of integrative judgment that comes from decades of professional experience. A model that scores 83% on GDPVal is not the same as a model that can serve as Federal Reserve chair.
The history of AI benchmarks is littered with cases where impressive benchmark performance did not translate cleanly to practical superiority. ImageNet accuracy plateaued while real-world computer vision systems still struggled with edge cases. Machine translation benchmarks showed near-human performance while actual translations remained awkward in context. We should be both impressed by and appropriately skeptical of this result.
Industry Implications
The convergence of expert-level reasoning, massive context windows, and computer use capabilities in a single model release is more significant than any one of these features alone. It suggests that the frontier of AI capability is advancing on multiple axes simultaneously.
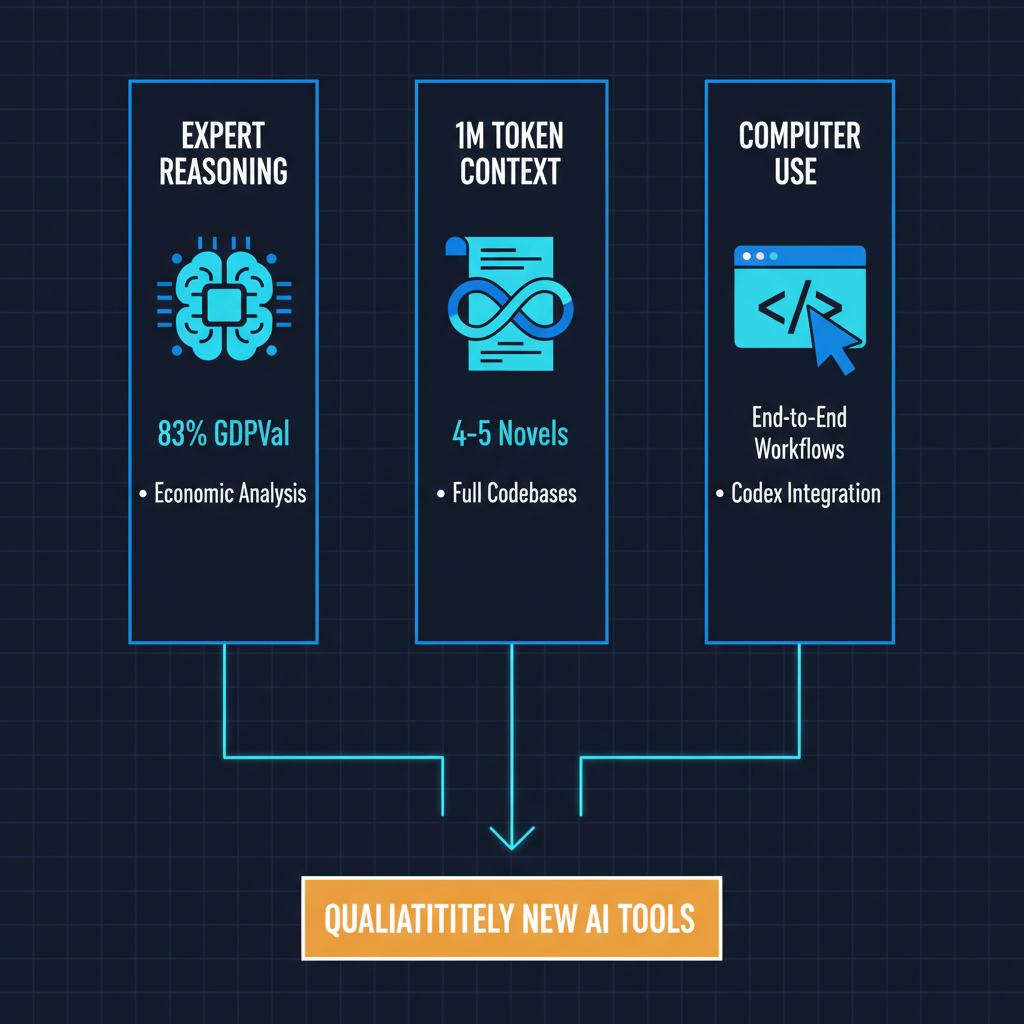
For enterprises, this means the calculus around AI adoption is changing again. Models that can reason at expert level across long documents while also executing tasks autonomously are qualitatively different tools than the chatbots and summarizers that defined the first wave of enterprise AI. The organizations that have built robust evaluation and governance frameworks for AI systems are better positioned to absorb these capabilities than those still running ad hoc pilot programs.
For AI practitioners, the message is that the ceiling on what models can do in bounded analytical domains is higher than many of us expected at this point. The research focus needs to shift increasingly toward reliability, consistency, and the hard problem of knowing when the model's confident-sounding analysis is actually wrong. An 83% score means that roughly one in five expert-level tasks is still answered incorrectly, and in high-stakes domains like economic policy, that error rate matters enormously.
For the broader AI ecosystem, GPT-5.4 Thinking is a reminder that the pace of capability improvement shows no signs of decelerating. The question is no longer whether AI will reach expert-level performance on cognitive tasks -- it is how we build the institutional frameworks to integrate that capability responsibly.
The models are now genuinely good at things that matter. The hard work is making sure we are good at using them wisely.


