
Yann LeCun has been arguing for years that large language models, for all their impressive capabilities, are fundamentally limited. His core thesis: systems that learn by predicting the next token in a text sequence cannot develop genuine understanding of the physical world. They can generate fluent text about gravity, but they do not understand what gravity does. They can describe how a ball bounces, but they cannot predict where it will land.
This week, LeCun's conviction received its most significant validation yet. AMI Labs — the company he co-founded to commercialize his vision of world models — raised $1.03 billion in what is now the largest seed round in European history. The investor list reads like a who's who of technology and sovereign capital: Jeff Bezos, NVIDIA, Samsung, and Temasek led the round, alongside a consortium of strategic and institutional investors.
This is not speculative hype money chasing the next chatbot. This is serious capital from serious investors betting that the next paradigm in AI is not better language models — it is models that understand the physical world.
What Are World Models, and Why Do They Matter?
The concept of a world model is deceptively simple: an AI system that builds an internal representation of how the world works and uses that representation to predict, plan, and reason about physical reality. Humans do this instinctively. When you catch a ball, you are not running a physics simulation. Your brain has an internal model of how objects move through space, built from years of experience, and you use that model to predict where the ball will be.
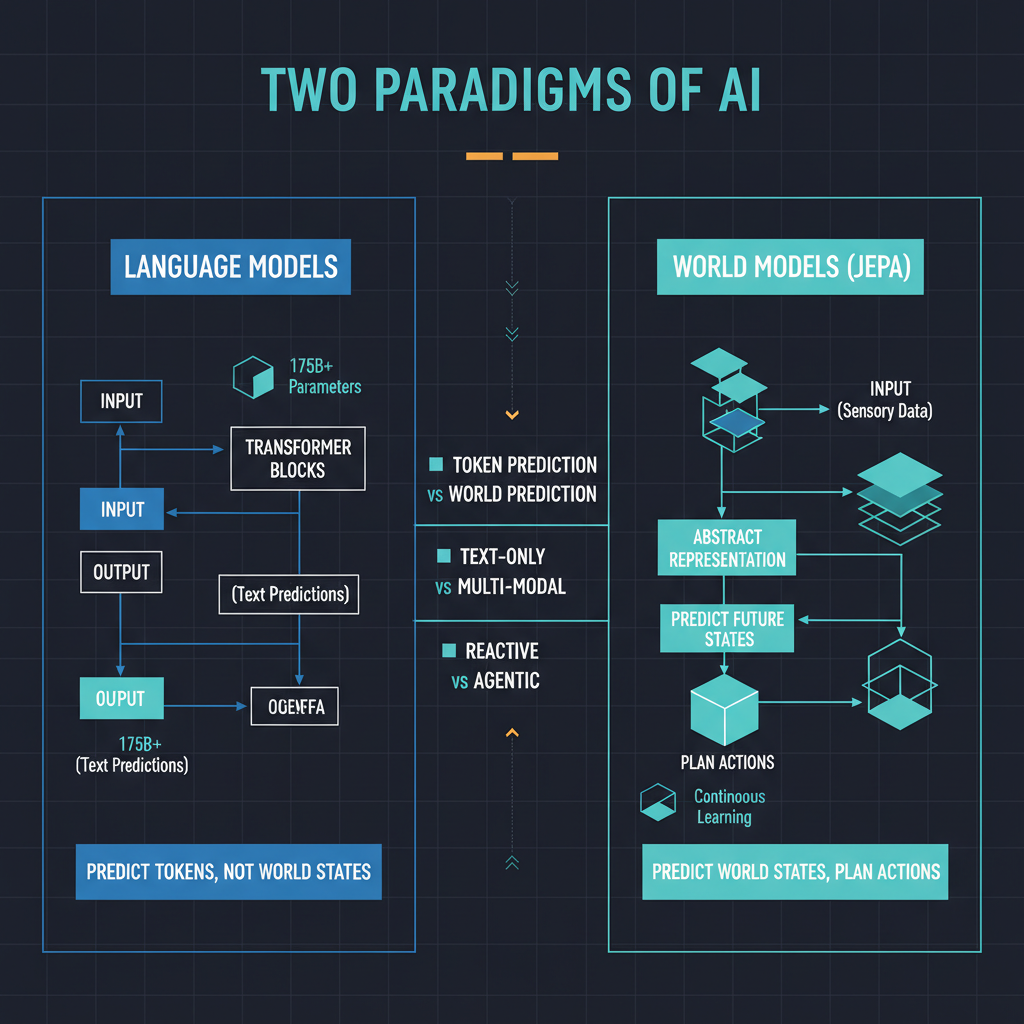
Current AI systems, including the most capable large language models, do not work this way. They learn statistical patterns in data and generate outputs that are consistent with those patterns. This approach is extraordinarily powerful for language, and increasingly capable for images and video. But it has fundamental limitations when the task requires genuine physical reasoning — understanding cause and effect, predicting the consequences of actions, planning multi-step manipulations of objects in space.
LeCun's JEPA architecture — Joint Embedding Predictive Architecture — is designed to address this gap. Instead of predicting raw pixels or tokens, JEPA learns to predict abstract representations of future states. The system learns what matters about a scene and builds its predictions at that higher level of abstraction, rather than trying to predict every pixel of the next video frame. This is both more computationally efficient and more aligned with how biological intelligence appears to model the world.
V-JEPA 2: The Technical Breakthrough
The most compelling evidence for the JEPA approach came from AMI Labs' V-JEPA 2 system, which demonstrated something genuinely remarkable: zero-shot robot planning.
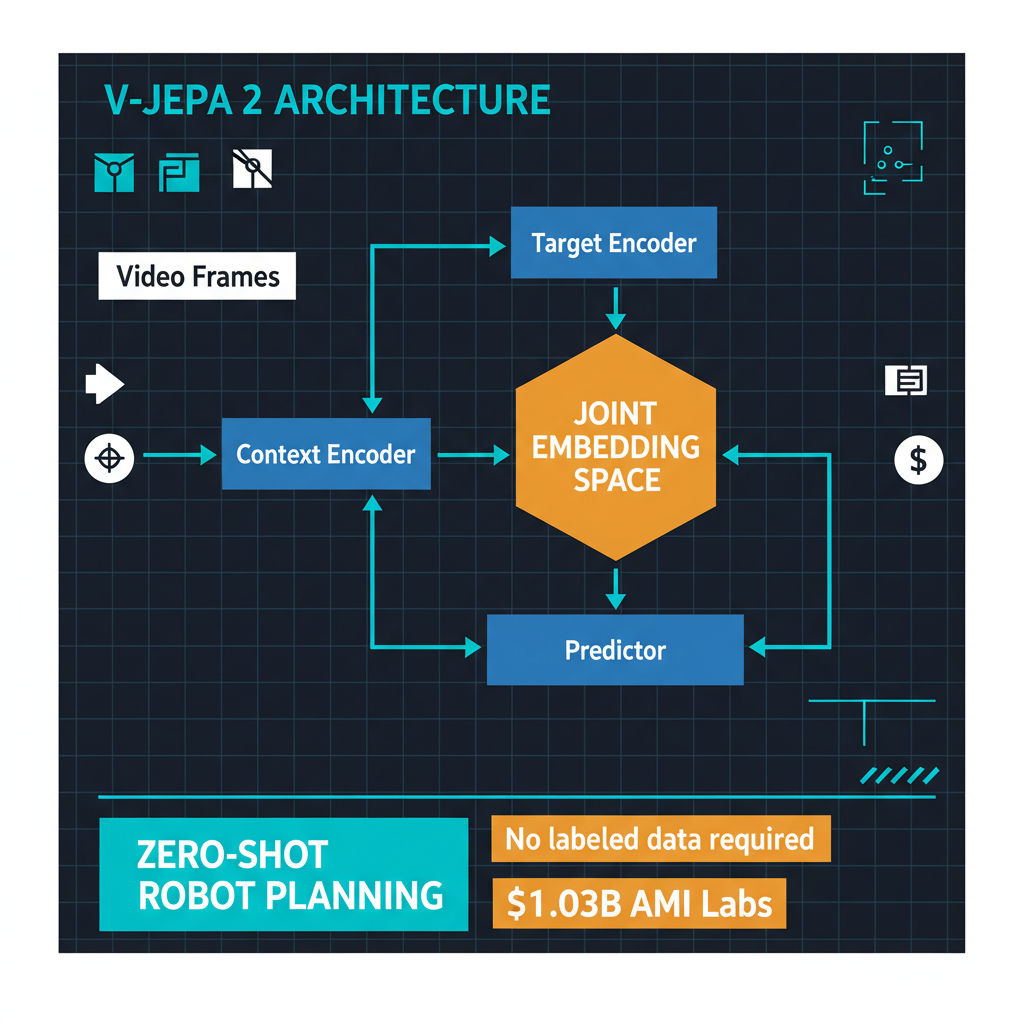
Here is what that means in practice. V-JEPA 2 was trained on video data — not robot-specific training data, not carefully labeled manipulation sequences, just 62 hours of domain-specific video. After this training, the system could plan and execute robotic manipulation tasks it had never seen before. No task-specific fine-tuning. No reward engineering. No simulation-to-real transfer. The system watched videos of the physical world, built an internal model of how objects behave, and used that model to plan actions.
This is a qualitative shift from how robotic AI systems have traditionally been built. Conventional approaches require extensive task-specific training: thousands of demonstrations, carefully designed reward functions, and painstaking sim-to-real transfer. Each new task essentially requires a new training pipeline. V-JEPA 2 suggests a path toward robotic systems that can generalize across tasks because they understand the underlying physics, not because they have been trained on each specific task.
Sixty-two hours of training data is also noteworthy. Foundation language models are trained on trillions of tokens scraped from the entire internet. V-JEPA 2 achieved meaningful physical reasoning from a comparatively tiny amount of domain-specific data. If this efficiency holds as the approach scales, it has profound implications for how quickly world models can be adapted to new domains.
World Labs and the Broader Paradigm Shift
AMI Labs is not the only company pursuing this vision. World Labs, co-founded by Fei-Fei Li, has also raised over $1 billion to build spatial intelligence systems — AI that understands three-dimensional space and can reason about physical environments. The parallel emergence of two billion-dollar companies pursuing variations of the same fundamental idea is significant.
When multiple well-funded research groups independently converge on the same paradigm, it usually means the paradigm has merit. This happened with transformers in 2017-2018, with scaling laws in 2020-2021, and with instruction tuning in 2022-2023. The convergence on world models in 2025-2026 suggests that the field has collectively recognized both the limitations of pure language modeling and the technical viability of alternatives.
The investor composition reinforces this reading. NVIDIA's participation in the AMI Labs round is particularly telling. NVIDIA does not make speculative bets on research directions — they invest in approaches that will drive demand for their hardware. Their assessment that world models represent the next major compute-intensive AI workload is a strong market signal.
What This Means for the LLM Paradigm
I want to be precise about what the rise of world models means — and does not mean — for large language models.
LLMs are not going away. They are extraordinarily capable for language understanding, generation, reasoning about text, and increasingly for code and structured data tasks. The business models built around LLMs — the enterprise AI platforms, the coding assistants, the customer service systems — are generating real revenue and delivering real value. Nothing about the world models paradigm invalidates that.
What world models do challenge is the assumption that scaling language models is sufficient for achieving artificial general intelligence. LeCun has been the most vocal proponent of this view, arguing that systems trained only on text cannot develop the kind of grounded understanding that is necessary for genuine intelligence. The success of V-JEPA 2 in robotic planning — a domain where language models have struggled despite massive scale — provides concrete evidence for this position.
The most interesting future is likely a hybrid one. Systems that combine the linguistic and reasoning capabilities of language models with the physical understanding of world models could be far more capable than either approach alone. Imagine an AI system that can read a technical manual describing a manufacturing process, build an internal model of how that process works physically, and then plan and execute the process robotically — integrating language understanding, physical reasoning, and action planning in a unified system.
The European Dimension
The fact that this is the largest European seed round ever matters for reasons beyond the dollar amount. Europe has consistently struggled to compete with the United States and China in the AI foundation model race, primarily due to capital constraints and talent concentration in Silicon Valley. AMI Labs represents a different kind of European AI company: one that is competing at the frontier of a new paradigm rather than trying to catch up in the existing one.
LeCun's decision to base AMI Labs in Europe — rather than adding to the concentration of AI research in San Francisco — is a meaningful statement about where the next wave of AI innovation can come from. It also reflects a strategic reality: European capital markets, particularly sovereign and institutional investors, are willing to make large bets on AI research that has a longer time horizon than typical venture-backed startups.
My Take
I have followed LeCun's arguments about the limitations of LLMs for years, and I have found them intellectually compelling but practically unproven. V-JEPA 2 changes that calculus. Zero-shot robotic planning from 62 hours of video data is not a marginal improvement on existing approaches — it is a fundamentally different capability.
The $1 billion round validates the thesis at the market level. But the real validation will come from the next generation of systems that AMI Labs builds with this capital. If JEPA-based world models can scale the way transformers scaled — if adding more data and more compute yields predictable improvements in physical reasoning capability — then we are looking at the beginning of a paradigm shift as significant as the transformer revolution itself.
LeCun has been patient with his vision. The field is now catching up to where he has been pointing for years. Whether AMI Labs delivers on the full promise of world models remains to be seen, but the direction of travel is clear: the future of AI is not just about understanding language. It is about understanding the world.


