
AlphaProof at the IMO: Silver in 2024, Gold in 2025, and What It Actually Means
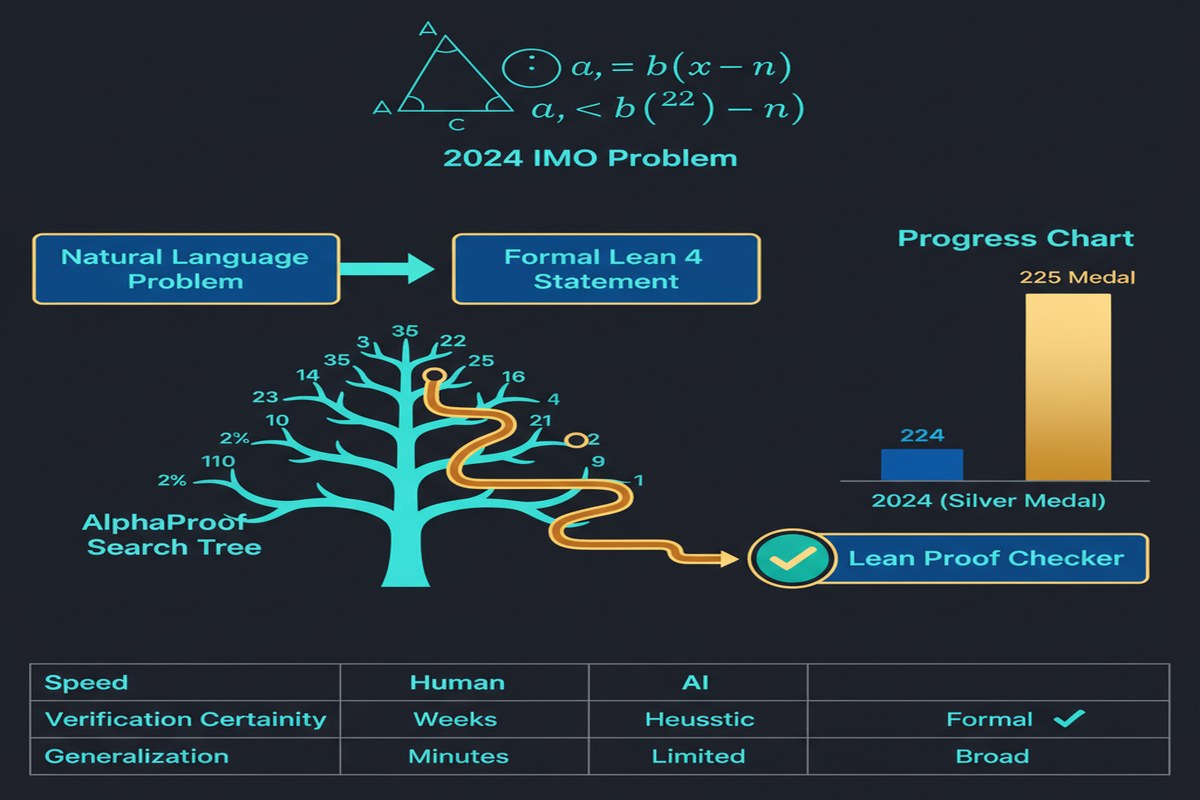
July 2024: Google DeepMind's AlphaProof solves 4 out of 6 International Mathematical Olympiad problems, earning a score equivalent to a silver medal. The methodology is published in Nature in November 2025. The world absorbs what happened: an AI system performed at the top 1% of human mathematical competition.
July 2025: Gemini Deep Think achieves a gold-medal-level score on the 2025 IMO. OpenAI's system scores similarly. The IMO, the world's most prestigious mathematics competition for pre-university students, is no longer a place where humans definitively outperform AI.
This trajectory — from none of the problems solved (2023) to silver (2024) to gold (2025) in just two years — is one of the fastest capability improvements I've seen documented in any complex cognitive domain. It deserves careful analysis.
What AlphaProof Is (and Isn't)
AlphaProof is not a language model that writes mathematical text. It is an AlphaZero-inspired agent that learns to find formal proofs in the Lean4 proof assistant using reinforcement learning.
flowchart TD
A[IMO Problem] --> B[Natural Language\nProblem Statement]
B --> C[AlphaGeometry 2:\nFormalize to Lean4]
C --> D[Formal Problem\nin Lean4]
D --> E[AlphaProof:\nRL-based Proof Search]
E --> F{Valid Lean4 Proof?}
F -->|No| G[Generate candidate\nproof attempt]
G --> H[Lean4 Verification]
H -->|Fail| I[Update policy via RL]
I --> E
H -->|Pass| J[Verified Proof]
J --> K[Translate back to\nnatural language solution]
style J fill:#059669,color:#fff
style E fill:#2563eb,color:#fff
AlphaGeometry 2 handles geometry problems by translating them into formal language. AlphaProof handles algebra, number theory, and combinatorics through Lean4-based proof search.
The crucial property: every solution is formally verified. AlphaProof doesn't guess answers — it constructs proofs that Lean4 certifies as correct. This is categorically different from LLMs that can write plausible-looking but incorrect mathematics.
How AlphaProof's RL Works
AlphaProof trains on a dataset of millions of auto-formalized mathematical problems — theorems extracted from mathematical literature and competition databases, automatically translated into Lean4. The key is scale: hundreds of millions of proof search trajectories, with Lean4 as the automatic oracle.
Test-Time Reinforcement Learning (TTRL): For the hardest problems (the IMO problems), AlphaProof uses TTRL — generating and learning from millions of variants of the target problem at inference time, before finalizing a solution. This problem-specific adaptation at inference time is what enables solving competition problems that weren't in the training distribution.
The nature of the reward is what makes this tractable: Lean4 proof verification is binary, deterministic, and fast. The system can try millions of proof attempts per problem, receiving exact correctness feedback each time. This is the RL dream scenario: a perfect, automatic reward function.
The 2024 IMO Results in Detail
AlphaProof solved 4 of 6 IMO 2024 problems:
- Problem 1 (algebra): Solved ✓
- Problem 2 (combinatorics): Solved ✓
- Problem 4 (geometry, via AlphaGeometry 2): Solved ✓
- Problem 6 (algebra, hardest problem): Solved ✓ — with the highest score in the competition
Problem 6 is notable: it was rated the most difficult problem of the 2024 IMO. AlphaProof found a proof that earned full marks — better than most human competitors.
Problems 3 and 5 remained unsolved. Total: 28 of 42 points — silver medal equivalent.
xychart-beta
title "AlphaProof IMO 2024 Score vs Human Medalists"
x-axis ["Bronze Threshold", "AlphaProof", "Silver Threshold", "Gold Threshold", "Top Score"]
y-axis "Points" 0 --> 42
bar [14, 28, 22, 29, 42]
The 2025 Progression: Gold Medal
By 2025 IMO, multiple AI systems achieved gold-medal scores. Gemini Deep Think's performance improved inference efficiency by approximately two orders of magnitude compared to AlphaProof's 2024 approach while achieving equivalent or better results. OpenAI's system also solved 5 of 6 problems.
The progression from 2023 (0 problems) to 2024 (4 problems, silver) to 2025 (5-6 problems, gold) in just two years suggests that IMO-level mathematics is no longer the right frontier for measuring AI mathematical capability. The question has shifted from "can AI do competition mathematics" to "what comes after competition mathematics."
Why the Nature Publication Matters
The November 2025 Nature publication of AlphaProof's methodology (not just results) is significant for the scientific community:
Reproducibility: Nature's peer-review process required detailed methodology disclosure. The formal proof search, TTRL procedure, and auto-formalization pipeline are now published and can be built upon.
Scientific credibility: Nature publication legitimizes AI mathematical results in the eyes of the mathematics community — which had been skeptical of claims about AI "proving theorems" when the proofs were informal sketches rather than formal verifications.
Benchmark clarification: The paper explicitly distinguishes between AI that can discuss mathematics (LLMs) and AI that can formally prove mathematics (AlphaProof). This distinction is crucial and often blurred in popular coverage.
The Limits of What This Means
I want to be clear-eyed about what AlphaProof's IMO performance does and doesn't mean.
What it means: AI can construct formally verified proofs of competition-level mathematical problems. The formal verification guarantee is real — these aren't plausible-looking proofs, they're machine-checked proofs.
What it doesn't mean: AI is doing mathematical research. IMO problems have known answers, known techniques, and are specifically designed to be solvable by talented humans in 4.5 hours. They test clever application of known mathematics, not discovery of new mathematics.
The frontier of research mathematics — finding new theorems, identifying new patterns, formulating new conjectures — remains entirely human. An AI that can solve every IMO problem would still be years from contributing meaningfully to, say, the Langlands program.
graph LR
A[Solved: IMO Problems\nCompetition Math\nKnown Techniques] --> B[Frontier: Research Math\nNew Theorems\nOpen Conjectures]
B --> C[Far Frontier:\nNew Mathematical Frameworks\nNew Branches of Mathematics]
style A fill:#059669,color:#fff
style B fill:#d97706,color:#fff
style C fill:#7c3aed,color:#fff
Why This Matters for AI Capability Research
The AlphaProof architecture represents a template for AI systems operating in verifiable domains — areas where correctness can be automatically checked:
- Code synthesis: Programs either pass tests or don't (DeepSeek-Prover-V2 uses exactly this principle)
- Scientific simulation: Physical simulations can validate predictions against known laws
- Logical reasoning: Satisfiability solvers can verify logical deductions
The RL-with-automatic-oracle approach that AlphaProof uses should work wherever you have a reliable correctness oracle. This is a significant design pattern for the next generation of AI systems.

My Take
AlphaProof is one of the most significant AI systems of the decade. Not because competition mathematics is important per se, but because it demonstrates that formal verification + reinforcement learning + scale is a path to genuine correctness guarantees — not just impressive-looking outputs.
The speed of improvement from 2023 to 2025 is alarming in the best sense. Two years to go from zero IMO problems to gold-medal performance is not a gradual curve — it's an exponential.
My concern: the field is moving faster than the institutions designed to assess it. IMO-level performance should trigger serious conversations about how universities test mathematical ability, what mathematical research will look like when AI systems can verify proofs, and what "mathematical understanding" means for systems that prove things through search rather than insight.
The mathematics community is not ready for this. They should be.
Paper: "Olympiad-level formal mathematical reasoning with reinforcement learning", Nature, Nov 2025. Related: AlphaProof (Google DeepMind, 2024 IMO), Gemini Deep Think (2025 IMO gold medal).
Explore more from Dr. Jyothi


